
人像视频编辑功能由
多模态生成先验
传统的人像视频编辑方法往往在三维效果和时间一致性方面存在问题,在渲染质量和效率方面也表现不佳。为了解决这些问题,PortraitGen 将人像视频的每一帧提升为统一的动态 3D 高斯场,从而确保每一帧之间的结构和时间一致性。
此外,PortraitGen 还设计了一种新的神经高斯纹理机制,不仅可以进行复杂的风格编辑,还能使渲染速度超过每秒 100 帧。它还引入了表情相似性指导和面部识别肖像编辑模块,有效减少了迭代更新数据集时可能出现的问题。(链接在文章底部)
01 字幕内容
PortraitGen 可在 30 分钟内将 2D 人像视频转换成 4D 高斯场,用于多模态人像编辑。编辑后的三维人像可以每秒 100 帧的速度渲染。首先跟踪单目视频中的 SMPL-X 系数,然后利用神经高斯纹理机制生成三维高斯特征场。
PortraitGen 还采用了迭代数据集更新策略进行人像编辑,并提出了面部识别编辑模块,以提高表情质量并保留个性化的面部结构。
02 实际用途
PortraitGen 解决方案是人像视频编辑的统一框架。任何保留结构的图像编辑模型都可用于制作三维一致、时间连贯的人像视频。
文本驱动编辑:InstructPix2Pix 用作二维编辑模型。它的 UNet 需要三个输入:输入 RGB 图像、文本指令和噪声潜像。根据输入的源图像和指令,为渲染图像添加一些噪点并进行编辑。
图像驱动编辑:侧重于基于图像线索的两类编辑。一种是提取参考图像的整体风格,另一种是通过在特定位置放置对象来定制图像。这些方法被实验性地用于风格迁移和虚拟拟合。使用神经风格迁移算法将参考图像的风格迁移到数据集帧中,并使用 AnyDoor 更改被试者的衣服。
重新照明:使用 IC-Light 处理视频帧的照明。将文字描述作为光照条件,PortraitGen 方法能和谐地调整人像视频的光照。
03 对比和消融实验
PortraitGen 方法与 TokenFlow、Rerender A Video、CoDeF 和 AnyV2V 等最先进的视频编辑方法进行了比较。
时间长度 00:47
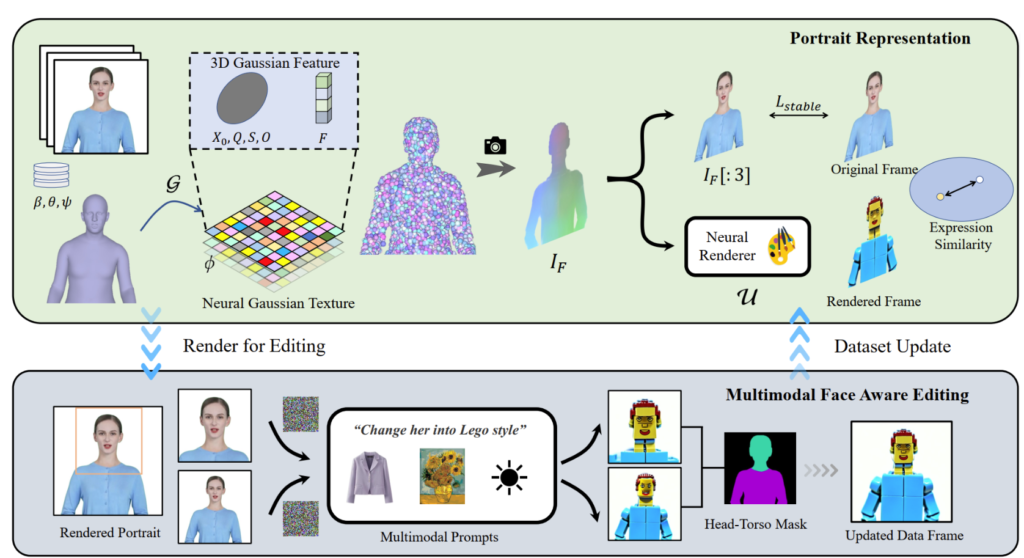
受 "延迟神经渲染 "中提出的神经纹理启发,PortraitGen 提出了神经高斯纹理。这种方法为每个高斯存储可学习的特征,而不是存储球谐波系数。然后,使用二维神经渲染器将处理过的特征图转换为 RGB 信号。与球谐波系数相比,这种方法能提供更丰富的信息,并能更好地融合处理后的特征,从而更容易编辑乐高和像素艺术等复杂风格。
在编辑上半身图像时,如果面部所占面积较小,对模型的编辑可能无法很好地适应头部姿势和面部结构。面部感知肖像编辑(FA)可以通过进行两次编辑来增强效果,从而提高对面部结构的关注度。
通过将渲染图像和输入源图像映射到 EMOCA 的潜在表情空间并优化表情的相似性,我们可以确保表情保持自然,并与原始视频帧保持一致。
PortraitGen 背后的技术
参考资料
有关 PotraitGen 的更多信息,请访问网站:https://ustc3dv.github.io/PortraitGen/。
