
Edición de video de retratos potenciada por
Priores generativos multimodales
Los métodos tradicionales de edición de videos de retratos suelen tener problemas con los efectos 3D y la coherencia temporal, y también tienen un rendimiento deficiente en términos de calidad y eficiencia de renderizado. Para solucionar estos problemas, PortraitGen convierte cada fotograma de un video de retrato en un campo gaussiano 3D dinámico unificado, que garantiza la coherencia estructural y temporal de un fotograma a otro. PortraitGen es un potente método de edición de videos de retratos que permite una estilización consistente y expresiva con señales multimodales.
Además, PortraitGen ha diseñado un nuevo mecanismo de texturización gaussiana neuronal que no solo permite una edición estilística compleja, sino que también permite velocidades de renderización superiores a 100 fotogramas por segundo. PortraitGen combina una amplia gama de entradas que se mejoran con el conocimiento extraído de modelos generativos 2D a gran escala. También presenta una guía de similitud de expresiones y un módulo de edición de retratos con reconocimiento facial, lo que reduce de manera efectiva los problemas que pueden surgir al actualizar iterativamente un conjunto de datos. (Enlace al final del artículo)
01 Contenido del subtítulo
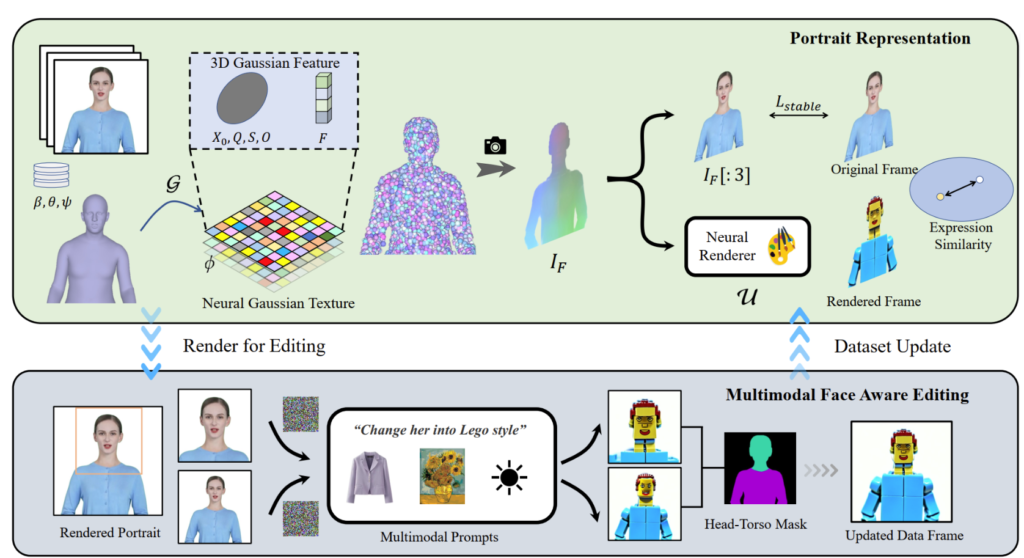
PortraitGen convierte videos de retratos en 2D en un campo gaussiano en 4D para la edición de retratos multimodales en tan solo 30 minutos. El retrato 3D editado se puede renderizar a 100 cuadros por segundo. Primero se rastrean los coeficientes SMPL-X en el video monocular y luego se genera un campo de características gaussiano en 3D utilizando un mecanismo de textura neuro-gaussiana.
Estos datos neurogaussianos se procesan aún más para generar la imagen del retrato. PortraitGen también emplea una estrategia iterativa de actualización de conjuntos de datos para la edición de retratos y propone un módulo de edición de reconocimiento facial para mejorar la calidad de las expresiones y preservar la estructura facial personalizada.
02 Usos prácticos
La solución PortraitGen es un marco unificado para la edición de videos de retratos. Cualquier modelo de edición de imágenes que conserve la estructura se puede utilizar para componer videos de retratos coherentes en el tiempo y consistentes en 3D.
Edición basada en texto: InstructPix2Pix se utiliza como modelo de edición 2D. Su UNet requiere tres entradas: una imagen RGB de entrada, un comando de texto y un ruido latente. Agrega algo de ruido a la imagen renderizada y la edita en función de la imagen de origen de entrada y las instrucciones.
Edición basada en imágenes: se centra en dos tipos de edición basados en las señales de la imagen. Uno consiste en extraer el estilo global de una imagen de referencia y el otro en personalizar la imagen colocando objetos en ubicaciones específicas. Estos métodos se utilizan experimentalmente para la migración de estilos y el ajuste virtual. El estilo de la imagen de referencia se migró a los marcos del conjunto de datos utilizando el algoritmo Neural Style Migration y la ropa del sujeto se cambió utilizando AnyDoor.
Reiluminación: uso de IC-Light para manipular la iluminación de los fotogramas del vídeo. Dada una descripción de texto como condición de iluminación, el método PortraitGen ajusta de forma armoniosa la iluminación del vídeo de retrato
03 Experimentos de contraste y ablación
El método PortraitGen se compara con métodos de edición de video de última generación, incluidos TokenFlow, Rerender A Video, CoDeF y AnyV2V. El método PortraitGen supera significativamente a los otros métodos en términos de preservación justo a tiempo, preservación de la identidad y consistencia temporal.
La duración del tiempo 00:47
Inspirado en la textura neuronal propuesta en 'Delayed Neural Rendering', PortraitGen propone una textura neuronal gaussiana. Este enfoque almacena características que se pueden aprender para cada gaussiana en lugar de almacenar coeficientes armónicos esféricos. A continuación, se utiliza un renderizador neuronal 2D para convertir los mapas de características procesados en señales RGB. Este método proporciona información más completa que los coeficientes armónicos esféricos y permite una mejor fusión de las características procesadas, lo que facilita la edición de estilos complejos como Lego y pixel art.
Al editar una imagen de la parte superior del cuerpo, si el rostro ocupa un área pequeña, es posible que la edición del modelo no se adapte bien a la pose de la cabeza y la estructura facial. La edición de retratos con reconocimiento facial (FA) puede mejorar los resultados al realizar dos ediciones para aumentar el enfoque en la estructura facial.
Al mapear la imagen renderizada y la imagen de la fuente de entrada en el espacio de expresión latente de EMOCA y optimizar la similitud de las expresiones, podemos garantizar que las expresiones permanezcan naturales y consistentes con los cuadros de video originales.
La tecnología detrás de PortraitGen
Referencia
Puede encontrar más información sobre PotraitGen aquí: https://ustc3dv.github.io/PortraitGen/
