
تحرير الفيديو للصور الشخصية بواسطة
المقدمات التوليدية متعددة الوسائط
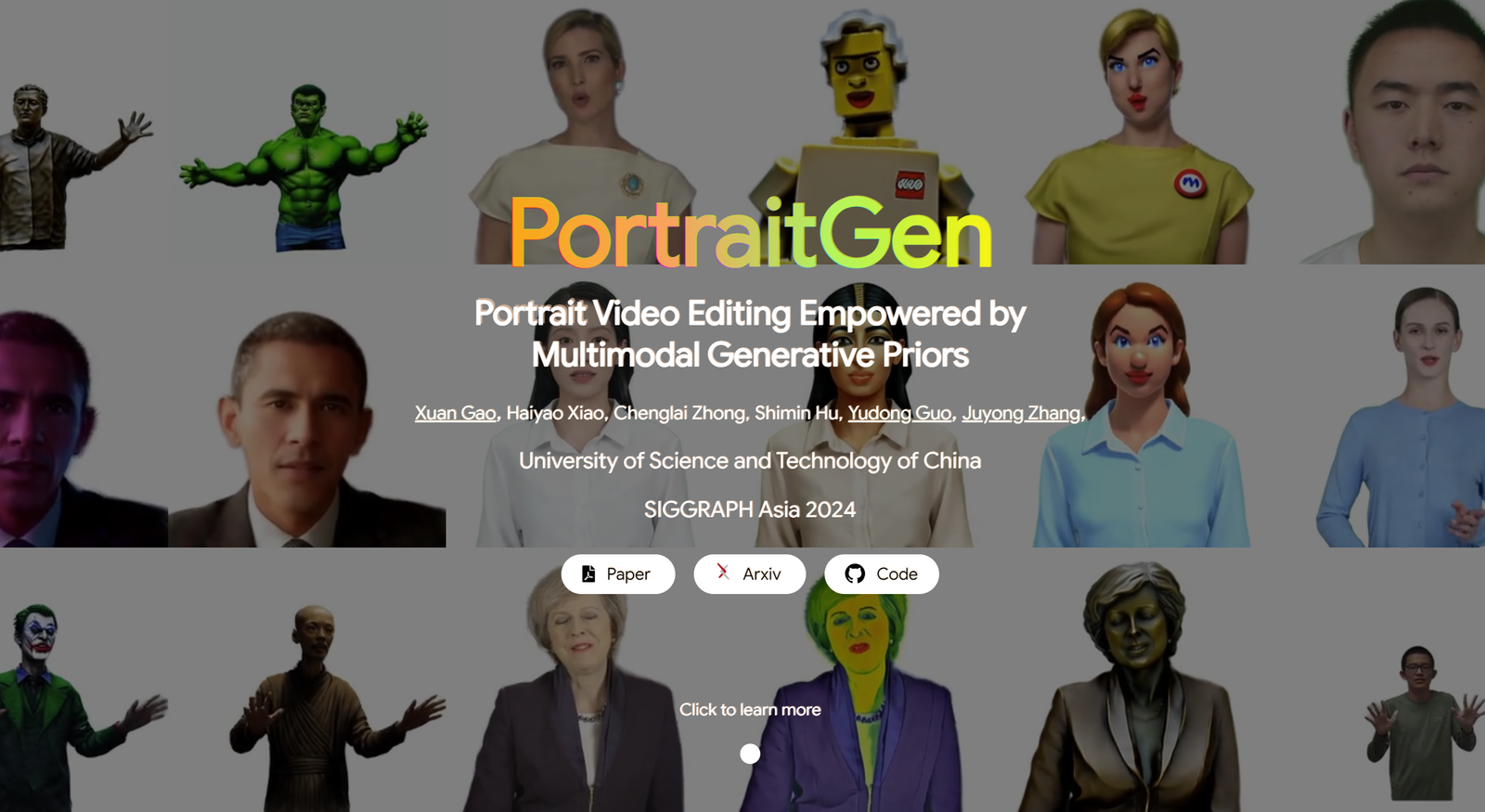
غالبًا ما تواجه طرق تحرير مقاطع الفيديو التقليدية للصور الشخصية مشكلات تتعلق بالتأثيرات ثلاثية الأبعاد والاتساق الزمني، كما أنها تؤدي أداءً ضعيفًا من حيث جودة العرض والكفاءة. لمعالجة هذه المشكلات، يرفع PortraitGen كل إطار من مقطع فيديو للصور الشخصية إلى حقل Gaussian ثلاثي الأبعاد ديناميكي موحد، مما يضمن الاتساق البنيوي والزمني من إطار إلى آخر. PortraitGen هي طريقة قوية لتحرير مقاطع الفيديو للصور الشخصية تسمح بالتصميم المتسق والمعبّر مع إشارات متعددة الوسائط.
بالإضافة إلى ذلك، ابتكرت PortraitGen آلية جديدة لإضفاء نسيج غاوسي عصبي لا تسمح فقط بالتحرير الأسلوبي المعقد، بل إنها تتيح أيضًا سرعات عرض تتجاوز 100 إطار في الثانية. يجمع PortraitGen بين مجموعة واسعة من المدخلات التي يتم تحسينها من خلال المعرفة المقطرة من نماذج توليدية ثنائية الأبعاد واسعة النطاق. كما يقدم إرشادات تشابه التعبير ووحدة تحرير الصور الشخصية للتعرف على الوجه، مما يقلل بشكل فعال من المشكلات التي قد تحدث عند تحديث مجموعة البيانات بشكل متكرر. (الرابط في أسفل المقال)
01 محتوى التسمية التوضيحية
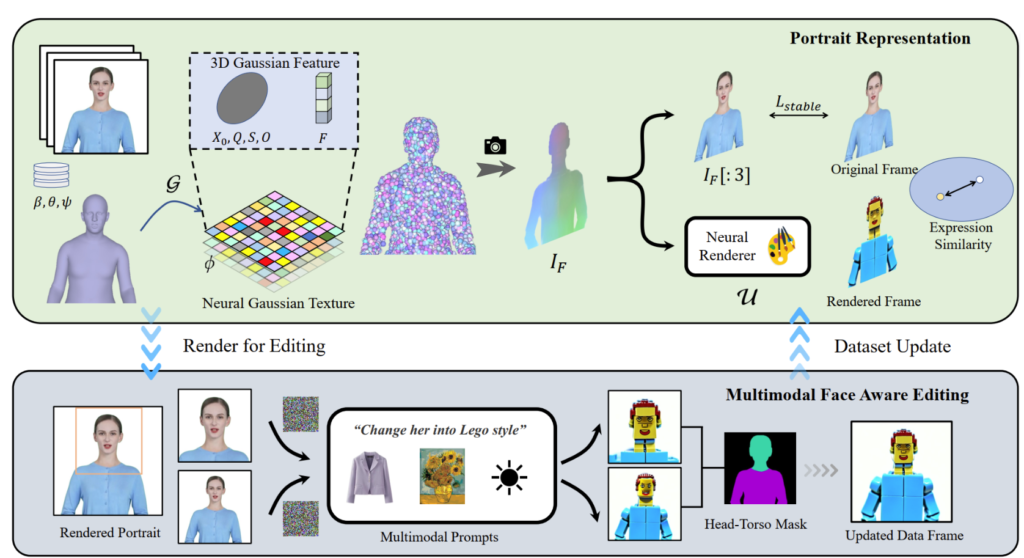
يقوم برنامج PortraitGen برفع مقاطع فيديو الصور الشخصية ثنائية الأبعاد إلى حقل Gaussian رباعي الأبعاد لتحرير الصور الشخصية متعدد الوسائط في 30 دقيقة فقط. يمكن عرض الصورة الشخصية ثلاثية الأبعاد المحررة بمعدل 100 إطار في الثانية. يتم أولاً تتبع معاملات SMPL-X في الفيديو أحادي العين، ثم يتم إنشاء حقل ميزة Gaussian ثلاثي الأبعاد باستخدام آلية نسيج Neuro-Gaussian.
يتم معالجة بيانات Neuro-Gaussian هذه بشكل أكبر لتقديم صورة الشخصية. يستخدم PortraitGen أيضًا استراتيجية تحديث مجموعة البيانات التكرارية لتحرير الصور الشخصية ويقترح وحدة تحرير التعرف على الوجه لتحسين جودة التعبيرات والحفاظ على بنية الوجه الشخصية.
02 الاستخدامات العملية
حل PortraitGen هو إطار عمل موحد لتحرير مقاطع الفيديو الشخصية. يمكن استخدام أي نموذج لتحرير الصور يحافظ على البنية لإنشاء مقاطع فيديو ثلاثية الأبعاد متناسقة ومتماسكة زمنيًا.
التحرير المستند إلى النص: يستخدم InstructPix2Pix كنموذج تحرير ثنائي الأبعاد. يتطلب UNet الخاص به ثلاثة مدخلات: صورة إدخال RGB وأمر نصي وضوضاء كامنة. يضيف بعض الضوضاء إلى الصورة المقدمة ويحررها بناءً على صورة المصدر المدخلة والتعليمات.
التحرير القائم على الصور: يركز على نوعين من التحرير بناءً على إشارات الصورة. الأول هو استخراج النمط العالمي لصورة مرجعية والآخر هو تخصيص الصورة عن طريق وضع الكائنات في مواقع محددة. تُستخدم هذه الطرق تجريبيًا لهجرة الأنماط والملاءمة الافتراضية. تم نقل نمط الصورة المرجعية إلى إطارات مجموعة البيانات باستخدام خوارزمية Neural Style Migration وتم تغيير ملابس الموضوع باستخدام AnyDoor.
إعادة الإضاءة: استخدام IC-Light للتحكم في إضاءة إطارات الفيديو. مع إعطاء وصف نصي كشرط للإضاءة، تعمل طريقة PortraitGen على ضبط إضاءة مقطع الفيديو البورتريه بشكل متناغم
03 تجارب التباين والاستئصال
تمت مقارنة طريقة PortraitGen بطرق تحرير الفيديو الحديثة بما في ذلك TokenFlow وRerender A Video وCoDeF وAnyV2V. تتفوق طريقة PortraitGen بشكل كبير على الطرق الأخرى من حيث الحفاظ في الوقت المناسب والحفاظ على الهوية والاتساق الزمني.
المدة الزمنية 00:47
مستوحى من الملمس العصبي المقترح في "التقديم العصبي المتأخر"، يقترح PortraitGen ملمسًا غاوسيًا عصبيًا. يخزن هذا النهج ميزات قابلة للتعلم لكل غاوسي بدلاً من تخزين معاملات التوافقيات الكروية. بعد ذلك، يتم استخدام مُقدم عصبي ثنائي الأبعاد لتحويل خرائط الميزات المعالجة إلى إشارات RGB. توفر هذه الطريقة معلومات أكثر ثراءً من معاملات التوافقيات الكروية وتسمح بدمج أفضل للميزات المعالجة، مما يجعل من الأسهل تحرير الأنماط المعقدة مثل Lego وفن البكسل.
عند تحرير صورة الجزء العلوي من الجسم، إذا كان الوجه يشغل مساحة صغيرة، فقد لا يكون تحرير النموذج ملائمًا بشكل جيد لوضع الرأس وبنية الوجه. يمكن لتحرير الصور الشخصية مع التركيز على الوجه (FA) تحسين النتائج من خلال إجراء تحريرين لزيادة التركيز على بنية الوجه.
من خلال تعيين الصورة المقدمة وصورة المصدر المدخلة في مساحة التعبير الكامنة في EMOCA وتحسين تشابه التعبيرات، يمكننا ضمان بقاء التعبيرات طبيعية ومتسقة مع إطارات الفيديو الأصلية.
التقنية وراء PortraitGen
المرجع
يمكنك العثور على مزيد من المعلومات حول PotraitGen هنا: https://ustc3dv.github.io/PortraitGen/
