
인물 비디오 편집 기능 제공
다중 모드 생성 사전
기존의 인물 영상 편집 방법은 종종 3D 효과와 시간적 일관성에 문제가 있으며, 렌더링 품질과 효율성 측면에서도 성능이 좋지 않습니다. 이러한 문제를 해결하기 위해 PortraitGen은 인물 영상의 각 프레임을 통합된 동적 3D 가우시안 필드로 끌어올려 프레임마다 구조적, 시간적 일관성을 보장합니다. PortraitGen은 다중 모달 큐를 사용하여 일관되고 표현력 있는 스타일을 가능하게 하는 강력한 인물 영상 편집 방법입니다.
또한 PortraitGen은 복잡한 스타일 편집을 허용할 뿐만 아니라 초당 100프레임을 초과하는 렌더링 속도를 가능하게 하는 새로운 신경 가우시안 텍스처링 메커니즘을 고안했습니다.PortraitGen은 대규모 2D 생성 모델에서 추출한 지식으로 강화된 광범위한 입력을 결합합니다.또한 표현 유사성 안내 및 얼굴 인식 초상화 편집 모듈을 도입하여 데이터 세트를 반복적으로 업데이트할 때 발생할 수 있는 문제를 효과적으로 줄입니다.(기사 하단의 링크)
01 캡션 내용
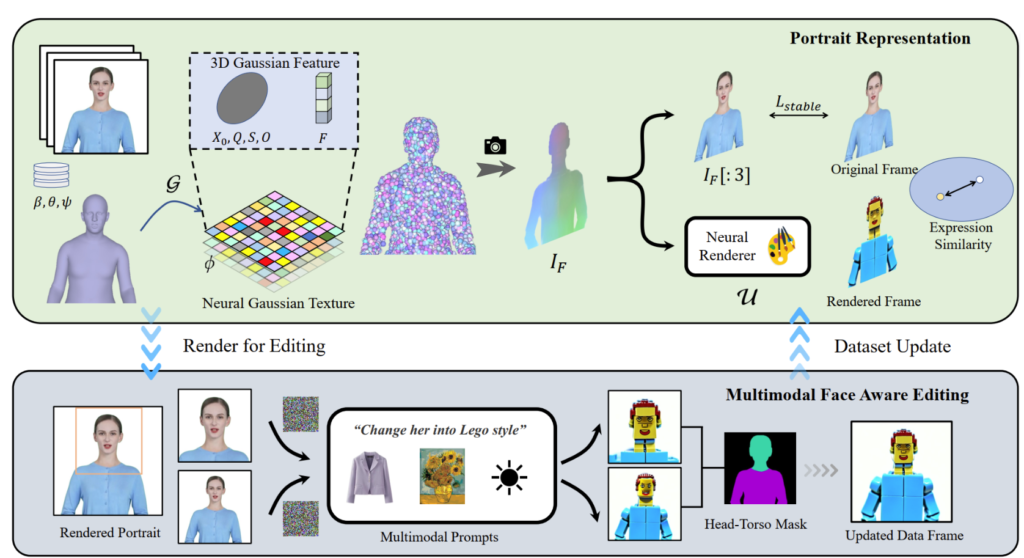
PortraitGen은 2D 인물 영상을 단 30분 만에 멀티모달 인물 영상 편집을 위한 4D 가우시안 필드로 끌어올립니다. 편집된 3D 인물 영상은 초당 100프레임으로 렌더링할 수 있습니다. 단안 영상의 SMPL-X 계수를 먼저 추적한 다음, Neuro-Gaussian 텍스처 메커니즘을 사용하여 3D 가우시안 특징 필드를 생성합니다.
이러한 신경 가우시안 데이터는 추가로 처리되어 인물 이미지를 렌더링합니다. 또한, PortraitGen은 인물 편집을 위해 반복적인 데이터 세트 업데이트 전략을 사용하고 표정의 품질을 향상시키고 개인화된 얼굴 구조를 보존하기 위한 얼굴 인식 편집 모듈을 제안합니다.
02 실용적 활용
PortraitGen 솔루션은 초상화 비디오 편집을 위한 통합 프레임워크입니다. 구조를 유지하는 모든 이미지 편집 모델은 3D 일관되고 시간적으로 일관된 초상화 비디오를 구성하는 데 사용할 수 있습니다.
텍스트 기반 편집: InstructPix2Pix는 2D 편집 모델로 사용됩니다. UNet에는 세 가지 입력이 필요합니다. 입력 RGB 이미지, 텍스트 명령 및 노이즈 잠재성입니다. 렌더링된 이미지에 약간의 노이즈를 추가하고 입력 소스 이미지와 지침에 따라 편집합니다.
이미지 기반 편집: 이미지 단서를 기반으로 하는 두 가지 유형의 편집에 초점을 맞춥니다. 하나는 참조 이미지의 글로벌 스타일을 추출하는 것이고 다른 하나는 특정 위치에 객체를 배치하여 이미지를 사용자 지정하는 것입니다. 이러한 방법은 스타일 마이그레이션 및 가상 피팅에 실험적으로 사용됩니다. 참조 이미지의 스타일은 Neural Style Migration 알고리즘을 사용하여 데이터 세트 프레임으로 마이그레이션되었고 피사체의 옷은 AnyDoor를 사용하여 변경되었습니다.
재조명: IC-Light를 사용하여 비디오 프레임의 조명을 조작합니다. 조명 조건으로 텍스트 설명을 제공하면 PortraitGen 방법은 인물 비디오의 조명을 조화롭게 조정합니다.
03 대조 및 소거 실험
PortraitGen 방식은 TokenFlow, Rerender A Video, CoDeF, AnyV2V를 비롯한 최첨단 비디오 편집 방식과 비교됩니다. PortraitGen 방식은 적시 보존, 신원 보존 및 시간적 일관성 측면에서 다른 방식보다 상당히 우수한 성과를 보입니다.
시간 지속 00:47
'지연된 신경 렌더링'에서 제안된 신경 텍스처에서 영감을 얻은 PortraitGen은 신경 가우시안 텍스처를 제안합니다. 이 접근 방식은 구면 고조파 계수를 저장하는 대신 각 가우시안에 대한 학습 가능한 피처를 저장합니다. 다음으로, 2D 신경 렌더러를 사용하여 처리된 피처 맵을 RGB 신호로 변환합니다. 이 방법은 구면 고조파 계수보다 더 풍부한 정보를 제공하고 처리된 피처의 더 나은 융합을 허용하여 레고 및 픽셀 아트와 같은 복잡한 스타일을 편집하기가 더 쉽습니다.
상체 이미지를 편집할 때 얼굴이 작은 영역을 차지하면 모델 편집이 머리 포즈와 얼굴 구조에 잘 맞지 않을 수 있습니다. 얼굴 인식 초상화 편집(FA)은 얼굴 구조에 초점을 맞추기 위해 두 번의 편집을 수행하여 결과를 향상시킬 수 있습니다.
렌더링된 이미지와 입력 소스 이미지를 EMOCA의 잠재 표현 공간에 매핑하고 표현의 유사성을 최적화함으로써 표현이 자연스럽고 원본 비디오 프레임과 일관성을 유지하도록 할 수 있습니다.
PortraitGen의 기술
참고문헌
PotraitGen에 대한 자세한 내용은 여기에서 확인할 수 있습니다: https://ustc3dv.github.io/PortraitGen/
