
肖像影片編輯功能由
多模態生成先驗
傳統的人像影片編輯方法往往存在3D效果、時間一致性等問題,渲染品質和效率也表現不佳。為了解決這些問題,PortraitGen 將肖像影片的每一幀提升為統一的動態 3D 高斯場,從而確保幀與幀之間的結構和時間一致性。
此外,PortraitGen 設計了一種新的神經高斯紋理機制,不僅可以進行複雜的風格編輯,還可以實現超過每秒 100 幀的渲染速度。它還引入了表情相似度引導和人臉辨識肖像編輯模組,有效減少迭代更新資料集時可能出現的問題。 (連結在文章底部)
01 字幕內容
PortraitGen 將 2D 肖像影片提升到 4D 高斯場,只需 30 分鐘即可實現多模式肖像編輯。編輯後的3D肖像可以以每秒100幀的速度渲染。首先追蹤單眼影片中的SMPL-X係數,然後利用神經高斯紋理機制產生3D高斯特徵場。
此神經高斯資料經過進一步處理以呈現肖像影像。
02 實際用途
PortraitGen解決方案是肖像影片編輯的統一框架。任何保留結構的影像編輯模型都可以用於組成 3D 一致且時間連貫的肖像影片。
文字驅動編輯:InstructPix2Pix用作2D編輯模型。它的 UNet 需要三個輸入:輸入 RGB 圖像、文字命令和雜訊潛在。在渲染的影像中加入一些雜訊,並根據輸入的來源影像和指令進行編輯。
影像驅動編輯:重點關注兩種基於影像提示的編輯類型。一種是提取參考圖像的整體風格,另一種是透過將物件放置在特定位置來定製圖像。這些方法被實驗性地用於風格遷移和虛擬試穿。使用神經風格遷移演算法將參考影像的風格遷移到資料集幀,並使用 AnyDoor 更改主體的衣服。
重新照明:使用 IC-Light 來操縱視訊畫面的照明。給定一個文字描述作為照明條件,PortraitGen 方法可以和諧地調整肖像影片的照明
03 對比與消融實驗
PortraitGen 方法與最先進的影片編輯方法進行了比較,包括 TokenFlow、Rerender A Video、CoDeF 和 AnyV2V。 PortraitGen 方法在即時保存、身分保存和時間一致性方面明顯優於其他方法。
片長 00:47
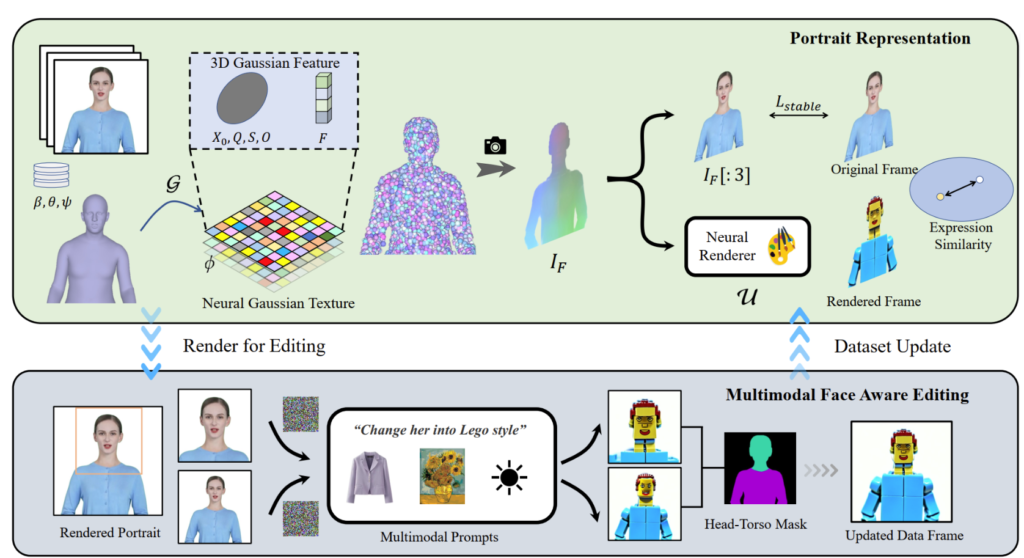
受到「延遲神經渲染」中提出的神經紋理的啟發,PortraitGen 提出了一種神經高斯紋理。這種方法儲存每個高斯的可學習特徵,而不是儲存球諧係數。接下來,使用 2D 神經渲染器將處理後的特徵圖轉換為 RGB 訊號。此方法比球面諧波係數提供了更豐富的信息,並且可以更好地融合處理後的特徵,從而更容易編輯樂高、像素藝術等複雜風格。
編輯上半身圖像時,如果臉部佔據的面積較小,模型的編輯可能無法很好地適應頭部姿勢和臉部結構。臉部意識肖像編輯 (FA) 可以透過進行兩次編輯來增強效果,以增加對臉部結構的注意力。
透過將渲染影像和輸入來源影像映射到EMOCA的潛在表情空間並優化表情的相似性,我們可以確保表情保持自然並與原始視訊幀保持一致。
PortraitGen 背後的技術
參考
你可以在這裡找到更多關於 PotraitGen 的資訊:https://ustc3dv.github.io/PortraitGen/
