

什么是LLM模式?
定义和概述
人工智能模型是一种经过一组数据训练的程序,可以识别某些模式或做出某些决策,而无需进一步的人工干预。
大型语言模型,也称为 法学硕士,都是基于大量数据进行预训练的大型深度学习模型。
底层 Transformer 是一组神经网络,由具有自注意力功能的编码器和解码器组成。编码器和解码器从文本序列中提取含义,并理解其中单词和短语之间的关系。
哪一个型号最适合您?
AI大模型的发展非常迅速,不同的公司和研究机构每天都会推出新的研究成果,同时还会推出新的大型语言模型。
因此,我们无法明确地告诉您哪一个是最好的。
不过现在也有一些顶级的公司和模型,比如OpenAI,现在也有一套标准和测试题来评估模型。
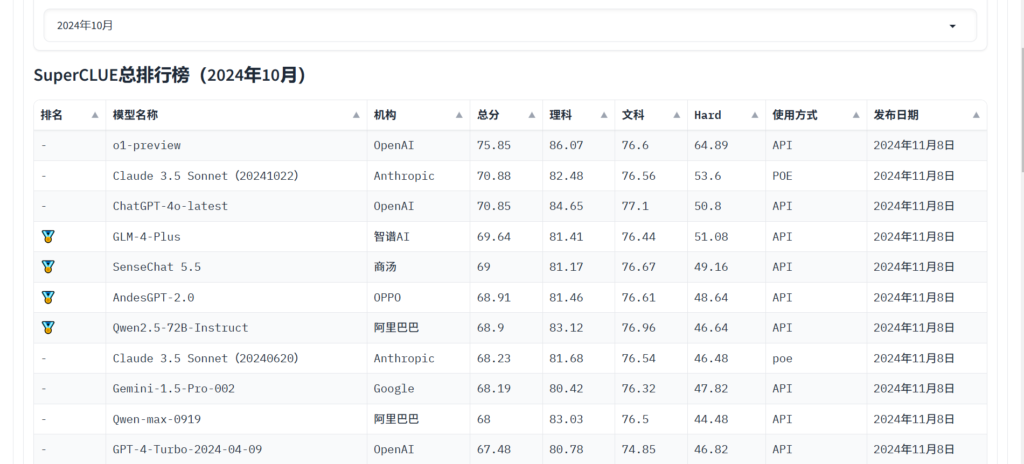
您可以参考 超级线索 查看模型在各个任务中的得分,并选择适合您的模型。此外,您还可以关注最新消息,以了解有关 LLM 模型能力的更多信息。
混元-大版 腾讯
模型介绍
11月5日, 腾讯 发布开源 MoE 大型语言模型 Hunyuan-large,共拥有 3980 亿个参数,为业界最大,激活参数达 520 亿个。
公测结果显示,腾讯混元大模型在各项目上全面领先。

技术优势
- 高质量合成数据:通过利用合成数据增强训练, 浑源-大 可以学习更丰富的表示,处理长上下文输入,并更好地推广到看不见的数据。
- KV 缓存压缩:利用分组查询注意(GQA)和跨层注意(CLA)策略显著减少KV缓存的内存使用量和计算开销,提高推理吞吐量。
- 针对专家的学习率调整:为不同的专家设置不同的学习率,以确保每个子模型有效地从数据中学习并提高整体性能。
- 长上下文处理能力:预训练模型支持高达256K的文本序列,Instruct模型支持高达128K,显著增强了处理长上下文任务的能力。
- 广泛的基准测试:在多种语言和任务上进行大量实验,验证混元-Large的实用有效性和安全性。
推理框架与训练框架
此开源版本提供了两个推理后端选项,专门针对 混元-大型模型:流行 vLLM-后端 和 TensorRT-法学硕士 后端。两种解决方案都包括增强性能的优化。
Hunyuan-Large开源模型完全兼容Hugging Face格式,方便科研开发者使用hf-deepspeed框架进行模型微调,同时支持通过flash Attention进行训练加速。
如何进一步使用此模型
这是一个开源模型。你可以在以下网址找到“tencent-hunyuan” GitHub,其中提供了详细的说明和使用指南。您可以进一步探索和研究它以创造更多可能性。
登月计划(君美)由 Moonshot AI 提供
摘要简介
Moonshot 是 Dark Side of the Moon 开发的大规模语言模型。以下是其功能概述:
- 技术突破:Moonshot 在长文本处理方面取得显著进步,其智能助手产品 Kimichat 支持多达 200 万个汉字的无损上下文输入。
- 模型架构:通过采用创新的网络结构和工程优化,它实现了长距离注意力,而无需依赖滑动窗口、下采样或通常会降低性能的较小模型等“捷径”解决方案。即使具有数千亿个参数,这也使人们能够全面理解超长文本。
- 应用导向:Moonshot 以实际应用为开发重点,旨在成为用户不可或缺的日常工具,并根据真实的用户反馈不断发展以产生切实的价值。

主要功能
- 长文本处理能力:能够处理小说或完整的财务报告等大篇幅文本,为用户提供深入、全面的见解和长篇文档摘要。
- 多模态融合:整合多种模态,将文本与图像数据相结合,增强分析和生成能力。
- 高度的语言理解和生成能力:表现出色,能够准确解释用户输入并生成高质量、连贯且语义上适当的响应。
- 灵活的可扩展性:具有强大的可扩展性,可根据不同的应用场景和需求进行定制和优化,为开发者和企业提供极大的灵活性和自主性。
使用方法
- API 集成:用户可以在“月之暗面”官方平台注册账号,申请API密钥,然后使用兼容编程语言的API将Moonshot的功能集成到自己的应用程序中。
- 使用官方产品和工具:直接使用基于Moonshot模型的智能助手产品Kimichat,或者利用Dark Side of the Moon提供的相关工具和平台。
- 与其他框架和工具的集成:Moonshot 可以与 LangChain 等流行的 AI 开发框架集成,以构建更为强大的语言模型应用程序。
由 zhipu.ai 提供的 GLM-4-Plus
摘要简介
智普AI研发的GLM-4-Plus是完全自研的GLM基础模型的最新版本,在语言理解、指令跟随和长文本处理方面有显著增强。
主要特点和优势
- 强大的语言理解能力:GLM-4-Plus 经过大量数据集和优化算法的训练,擅长处理复杂的语义,准确解释各种文本的含义和上下文。
- 出色的长文本处理能力:GLM-4-Plus采用创新的内存机制和分段处理技术,可以有效处理长达128k个标记的长文本,具有非常出色的数据处理和信息提取能力。
- 增强推理能力:结合近端策略优化(PPO)在探索最优解的同时保持稳定性和效率,显著提高模型在数学和编程等复杂推理任务中的表现。
- 指令执行准确度高:准确理解并遵守用户指示,根据用户要求生成高质量、符合期望的文本。
使用说明
- 注册账户并获取API密钥:首先,在智扑官网注册一个账号,并获取一个API key。
- 查看官方文档:详细参数及使用说明请参考GLM-4系列官方文档。
SenceTime 的 SenseChat 5.5
摘要简介
SenseChat 5.5是商汤科技自主研发的大型语言模型5.5版本,该模型基于中国最早建立的万亿级参数大型语言模型之一InternLM-123b,并持续更新。

主要特点和优势
- 强大的综合性能:在多项评估任务中持续名列前茅,在人文和科学领域的基础能力以及高级“困难”任务中表现出色。它在人文学科的语言理解和安全性方面表现出色,在科学领域的逻辑和编码方面表现出色。
- 高效的边缘应用:商汤科技发布SenseChat Lite-5.5版本,初始加载时间压缩至仅0.19秒,较4月份发布的SenseChat Lite-5.0提升40%,推理速度达90.2个字符/秒,单机年费用低至9.9元。
- 卓越的语言能力:作为一款自然语言应用,它能够有效处理大量文本数据,具有强大的自然语言对话能力、逻辑推理能力、知识面广、更新频繁等特点。它支持简体中文、繁体中文、英文和常见的编程语言。
用途及应用产品
- 直接使用:用户可以在【SenseTime官网】注册,通过网页或手机APP访问SenseChat并与模型进行交互。
- API 集成:商汤科技为企业和开发者提供API访问,使他们能够将SenseChat 5.5集成到他们的产品或应用程序中。
Qwen2.5-72B-由阿里云 Qwen 团队指导
模型介绍
Qwen2.5 是 Qwen 最新推出的大型语言模型系列。 Qwen2.5之后,团队发布了多个基础语言模型和指令调优语言模型,参数规模从5亿到720亿不等。
主要特色
- 密集、易于使用、仅用于解码器的语言模型,可用于 0.5亿, 15亿, 3B, 7B, 14B, 32B和 72B 尺寸、基础和指导变体。
- 在我们最新的大规模数据集上进行预训练,涵盖多达 18T 代币。
- 在指令跟踪、生成长文本(超过 8K 个标记)、理解结构化数据(例如表格)以及生成结构化输出(尤其是 JSON)方面有显著改进。
- 更能适应系统提示的多样性,增强聊天机器人的角色扮演实现和条件设定。
- 上下文长度最多支持 128千 代币,最多可产生 8K 代币。
- 超过的多语言支持 29 语言包括中文、英语、法语、西班牙语、葡萄牙语、德语、意大利语、俄语、日语、韩语、越南语、泰语、阿拉伯语等。
如何快速启动?
你可以在 Github 和 Hugging face 上找到使用大型模型的教程,基于这些教程你可以有效地运行模型,实现你的功能和想法。
Doubao-pro,作者:字节跳动豆宝团队
摘要简介
Doubao-pro是字节跳动自主研发的大型语言模型,于2024年5月15日正式发布。在Flageval大模型评测平台中,Doubao-pro以75.96分的成绩位列闭源模型第二名。
- 版本:Doubao-pro包含4k、32k、128k上下文窗口的版本,每个版本支持不同长度的上下文进行推理和微调。
- 性能改进:根据字节跳动内部测试,Doubao-pro-4k在11项行业标准公开基准测试中取得了总成绩76.8分。
主要特点和优势
- 综合能力强:Doubao-pro在客观和主观评价中均表现出色,包括数学、知识应用和解决问题等。
- 应用范围广泛:作为国内使用最广泛、功能最全的车型之一,豆宝的AI助手“豆宝”在苹果应用商店及安卓各大应用市场AIGC应用中下载量位居第一。
- 高成本效益:Doubao-pro-32k 的推理输入成本仅为每千个 token 0.0008 元。例如,处理中文版 哈利·波特 (274万个字符)售价仅为1.5元。
- 出色的语言理解和生成:Doubao-pro能够准确理解多种自然语言输入,并生成高质量、连贯、有逻辑的响应,满足用户简单问答、复杂文本创建和专业领域解释的需求。
- 高效的推理速度:通过大量的数据训练和优化,Doubao-pro具有推理速度优势,可以快速响应并增强用户体验,尤其是在处理大量文本或复杂任务时。
使用方法
- 通过 Volcano Engine:通过调用模型的API来使用Doubao-pro,代码示例可以在Volcano Engine的官方文档中找到。
- 对于特定产品:Doubao-pro 通过 Volcano Engine 面向企业市场推出,企业可将其集成到产品或服务中。您也可以通过 Doubao 应用体验 Doubao 模型。
360 的 360gpt2-pro
摘要简介
- 型号名称:360GPT2-Pro属于360自主研发的360智脑大模型系列。
- 技术基础:360依托20年安全数据、10年AI经验,以及80位AI专家和100位安全专家的专业知识,在200天内利用5,000个GPU资源来训练和优化智脑模型,其中360GPT2-Pro是其高级版本之一。

主要特点和优势
- 强语言生成:擅长语言生成任务,尤其是人文学科,通过创作高质量、富有创意、逻辑连贯的内容,例如故事和文案。
- 扎实的知识理解与应用:拥有广泛的知识基础,可以准确地解释和应用信息来回答问题并有效地解决问题。
- 增强型基于检索的生成:擅长检索增强生成,特别是针对中文,使模型能够生成符合用户需求和真实世界数据的响应,从而降低幻觉概率。
- 增强的安全功能:得益于360在安全领域的长期专业知识,360GPT2-Pro提供了一定的安全性和可靠性,有效应对各种安全风险。
使用方法及相关产品
- 360AI搜索:将360GPT2-Pro与搜索功能集成,为用户提供更全面、更深入的搜索体验。
- 360AI浏览器:将360GPT2-Pro融入360AI浏览器,用户可以通过特定界面或通过语音输入与模型进行交互,获取信息和建议。
Step-2-16k 作者 stepfun
摘要简介
- 开发人员:StepStar 发布正式版 STEP-2 万亿参数语言模型 在 2024 年,step-2-16k 指的是支持 16k 上下文窗口的变体。
- 模型架构:基于创新的MoE(混合专家)架构,根据任务和数据分布动态激活不同的专家模型,提高性能和效率。
- 参数比例:该模型拥有一万亿个参数,捕捉了广泛的语言知识和语义信息,在各种自然语言处理任务中展现出强大的能力。

主要特点和优势
- 强大的语言理解和生成:准确解释输入文本并生成高质量、自然的响应,准确且有价值地支持回答问题、内容生成和对话交流等任务。
- 多领域知识覆盖:该模型经过海量数据集的训练,涵盖了数学、逻辑、编程、知识和创意写作等领域的广泛知识,使其能够灵活地进行跨领域的响应和应用。
- 长序列处理能力:该模型具有 16k 上下文窗口,擅长处理长文本序列,有助于理解和处理长篇文章和复杂文档。
- 性能接近GPT-4:该模型在多个语言任务中实现了接近GPT-4的性能,展示了高水平的综合语言处理能力。
用途和应用
StepStar为企业和开发者提供了一个开放的平台,用于申请访问 step-2-16k 模型.
用户可以通过API调用将模型集成到应用程序或开发项目中,使用平台提供的文档和开发工具来实现各种自然语言处理功能。
DeepSeek-V2.5 由 deepseek 提供
摘要简介
DeepSeek-V2.5由 DeepSeek 团队开发的 是一个强大的开源语言模型,它集成了 DeepSeek-V2-Chat 和 DeepSeek-Coder-V2-Instruct 的功能,代表了之前模型改进的顶峰。关键细节如下:
- 发展历史:2024 年 9 月,他们正式发布了 DeepSeek-V2.5,结合了聊天和编码功能。此版本增强了一般语言能力和编码功能。
- 开源性质:秉承开源开发的承诺,DeepSeek-V2.5 现已在 Hugging Face 上发布,开发者可以根据需要调整和优化模型。

主要特点和优势
- 结合语言和编码能力:DeepSeek-V2.5 保留了聊天模型的对话能力和编码器模型的编码优势,使其成为真正的“一体化”解决方案,能够处理日常对话、复杂指令遵循、代码生成和完成。
- 人类偏好一致:该模型经过微调以适应人类偏好,针对写作质量和指令遵守情况进行了优化,在多个任务中表现得更自然、更智能,以更好地理解和满足用户需求。
- 出色的表现: DeepSeek-V2.5 在各项基准测试中超越了之前的版本,并在 humaneval python 和 live code bench 等编码基准测试中取得了最佳成绩,展示了其在指令遵循和代码生成方面的实力。
- 扩展上下文支持:DeepSeek-V2.5 的最大上下文长度为 128k 个标记,可以有效处理长文本和多轮对话。
- 高成本效益:与顶级闭源模型相比, 克劳德 3.5 十四行诗 和 GPT-4o、DeepSeek-V2.5 具有显著的成本优势。
使用方法
- 通过网页平台:通过 SiliconCloud 的 DeepSeek-V2.5 游乐场等网络平台访问 DeepSeek-V2.5。
- 通过 API:用户可以创建账号获取API key,然后通过API将DeepSeek-V2.5集成到自己的系统中,进行二次开发和应用。
- 本地部署:需要 8 个 GPU,每个 80GB,使用 Hugging Face 的 Transformers 进行推理。具体步骤请参阅文档和示例代码。
- 在特定产品内:
- 光标:这款基于VSCode的AI代码编辑器,允许用户配置DeepSeek-V2.5模型,通过快捷方式连接SiliconCloud的API进行页面代码生成,提高编码效率。
- 其他开发工具或平台:任何支持外部语言模型API的开发工具或平台理论上都可以通过获取API密钥来集成DeepSeek-V2.5,实现语言生成和代码编写功能。
百度的 Ernie-4.0-turbo-8k-preview
摘要简介
Ernie-4.0-turbo-8k-预览版 属于百度ERNIE 4.0 Turbo系列,于2024年6月28日正式发布,2024年7月5日向企业客户全面开放。
主要特点和优势
- 性能改进:作为 ERNIE 4.0 的升级版本,该模型将上下文输入长度从 2k 个 token 扩展到 8k 个 token,使其能够处理更大的数据集,读取更多的文档或 URL,并在涉及长文本的任务上表现得更好。
- 降低成本:ERNIE 4.0-turbo-8k-preview的投入产出成本分别低至每1000个代币0.03元人民币和每1000个代币0.06元人民币,较ERNIE 4.0通用版本降价70%。
- 技术优化:通过turbo技术的增强,该模型实现了训练速度和性能的双重提升,可以更快地进行模型训练和部署。
- 应用广泛:该模型凭借其性能和成本优势,广泛应用于智能客服、虚拟助手、教育、娱乐等领域,提供流畅自然的对话体验。其强大的生成能力也使其非常适合内容创作和数据分析。
用法
ERNIE 4.0-turbo-8k-preview 主要面向企业客户开放,企业客户可以通过百度智能云上的百度千帆大模型平台访问。
中国公司创造的十大人工智能模型
| 模型 | 开发人员 | 主要特点和优势 | 如何使用 |
| 浑源-大 | 腾讯 | 开源,3980亿个参数 | 下载模型 |
| Moonshot(君) | 登月计划人工智能 | 长文本处理能力、高语言理解能力 | API、官方App及工具 |
| GLM-4-Plus | 智扑网 | 语言理解、指令遵循和长文本处理。 | API |
| SenseChat 5.5 | 时间 | 综合性能强大,语言能力卓越 | 商汤科技网站、API |
| Qwen2.5-72B | 阿里云 | 上下文长度最大支持128K,支持超过29种语言 | 下载模型,官网 |
| 豆宝 | 字节跳动 | 综合能力强,性价比高,聊天机器人, | 淘宝APP,API |
| 360gpt2-pro | 360 | 增强的安全功能,强大的语言生成 | Lobechat、360AI浏览器 |
| 步骤-2-16k | 继子乐趣 | 万亿参数语言模型,多领域知识覆盖,性能接近GPT-4 | API |
| DeepSeek-V2.5 | 深度搜索 | 结合语言和编码能力,符合人类偏好 | Web平台、API、本地部署 |
| 厄尼-4.0-涡轮-8k | 百度 | 广泛应用,降低成本, | 仅限企业客户 |


