

Che cos'è il modello LLM?
Definizione e panoramica
Un modello di intelligenza artificiale è un programma che è stato addestrato su un insieme di dati per riconoscere determinati modelli o prendere determinate decisioni senza ulteriore intervento umano.
I modelli linguistici di grandi dimensioni, noti anche come LLMsono modelli di apprendimento profondo di grandi dimensioni che vengono pre-addestrati su grandi quantità di dati.
Il trasformatore sottostante è un insieme di reti neurali che consistono in un codificatore e in un decodificatore con capacità di autoattenzione. L'encoder e il decoder estraggono i significati da una sequenza di testo e comprendono le relazioni tra le parole e le frasi in esso contenute.
Qual è il modello migliore per voi?
I modelli di AI di grandi dimensioni si stanno sviluppando molto rapidamente. Diverse aziende e istituti di ricerca presentano ogni giorno nuovi risultati di ricerca e nuovi modelli linguistici di grandi dimensioni.
Pertanto, non possiamo dirvi in modo definitivo quale sia il migliore.
Tuttavia, esistono aziende e modelli di alto livello, come OpenAI. Esiste ora una serie di standard e di domande di prova per valutare i modelli.
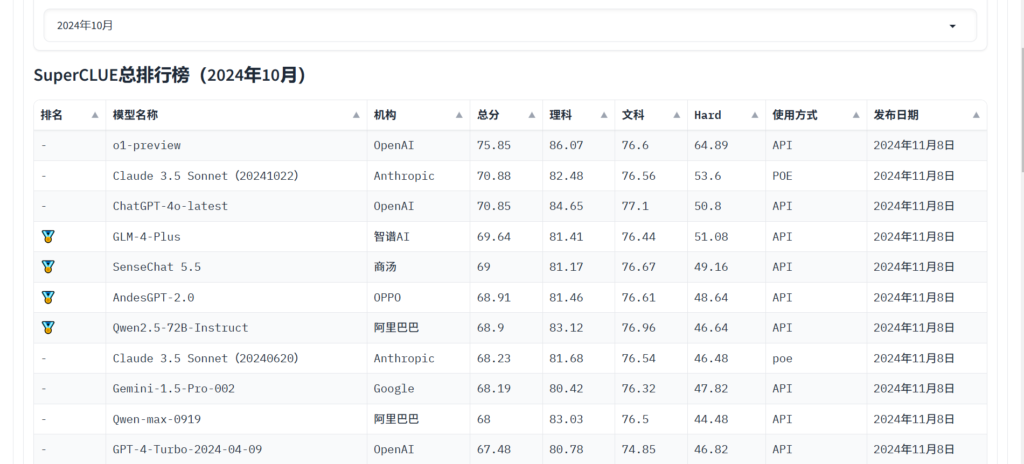
Si può fare riferimento a superclueai per visualizzare i punteggi del modello in vari compiti e scegliere quello che fa per voi. Inoltre, è possibile seguire le ultime notizie per saperne di più sulle capacità del modello LLM.
Hunyuan-Large di Tencent
Introduzione al modello
Il 5 novembre, Tencent rilascia il modello linguistico Open-Source MoE Large Hunyuan-large con un totale di 398 miliardi di parametri, che lo rende il più grande del settore, con 52 miliardi di parametri di attivazione.
I risultati della valutazione pubblica dimostrano che il modello Hunyuan Large di Tencent è leader assoluto in diversi progetti.

Vantaggi tecnici
- Dati sintetici di alta qualità: Migliorando l'addestramento con dati sintetici, Hunyuan-Grande possono apprendere rappresentazioni più ricche, gestire input con contesti lunghi e generalizzare meglio a dati non visti.
- Compressione della cache KV: Utilizza le strategie Grouped Query Attention (GQA) e Cross-Layer Attention (CLA) per ridurre significativamente l'uso della memoria e l'overhead computazionale delle cache KV, migliorando il throughput dell'inferenza.
- Scala del tasso di apprendimento specifica per l'esperto: Imposta tassi di apprendimento diversi per i vari esperti per garantire che ogni sottomodello apprenda efficacemente dai dati e contribuisca alle prestazioni complessive.
- Capacità di elaborazione di lunghi contesti: Il modello pre-addestrato supporta sequenze di testo fino a 256K, mentre il modello Instruct ne supporta fino a 128K, migliorando in modo significativo la capacità di gestire attività a contesto lungo.
- Ampio benchmarking: Conduce esperimenti approfonditi in varie lingue e attività per convalidare l'efficacia pratica e la sicurezza di Hunyuan-Large.
Struttura di inferenza e struttura di addestramento
Questa versione open-source offre due opzioni di backend di inferenza adattate per il sistema Modello Hunyuan-Grande: il popolare vLLM-backend e il TensorRT-LLM Backend. Entrambe le soluzioni includono ottimizzazioni per migliorare le prestazioni.
Il modello open-source di Hunyuan-Large è pienamente compatibile con il formato Hugging Face, consentendo a ricercatori e sviluppatori di eseguire la messa a punto del modello utilizzando il framework hf-deepspeed. Inoltre, supportiamo l'accelerazione dell'addestramento attraverso l'uso dell'attenzione flash.
Come utilizzare ulteriormente questo modello
Si tratta di un modello open-source. Potete trovare "tencent-hunyuan" su GitHubdove vengono fornite istruzioni dettagliate e guide all'uso. È possibile esplorare e ricercare ulteriormente per creare ulteriori possibilità.
Moonshot(Kimi) di Moonshot AI
Introduzione sintetica
Moonshot è un modello linguistico su larga scala sviluppato da Dark Side of the Moon. Ecco una panoramica delle sue caratteristiche:
- Innovazione tecnologica: Moonshot ha raggiunto notevoli progressi nell'elaborazione dei testi lunghi, con il suo prodotto per assistenti intelligenti, Kimichat, che supporta fino a 2 milioni di caratteri cinesi in inserimento contestuale senza perdite.
- Modello di architettura: Utilizzando una struttura di rete innovativa e ottimizzazioni ingegneristiche, raggiunge un'attenzione a lungo raggio senza ricorrere a soluzioni "scorciatoia" come le finestre scorrevoli, il downsampling o i modelli più piccoli che spesso degradano le prestazioni. Ciò consente la comprensione completa di testi lunghissimi anche con centinaia di miliardi di parametri.
- Orientato all'applicazione: Sviluppato con un'attenzione particolare all'applicazione pratica, Moonshot mira a diventare uno strumento quotidiano indispensabile per gli utenti, evolvendo sulla base del feedback reale degli utenti per generare un valore tangibile.

Caratteristiche principali
- Capacità di elaborazione di testi lunghi: È in grado di gestire testi estesi come romanzi o relazioni finanziarie complete, offrendo agli utenti approfondimenti e sintesi di documenti lunghi.
- Fusione multimodale: Integra più modalità, combinando i dati di testo con quelli di immagine per migliorare le capacità di analisi e generazione.
- Elevata capacità di comprensione e generazione della lingua: Dimostra eccellenti prestazioni multilingue, interpretando accuratamente gli input degli utenti e generando risposte di alta qualità, coerenti e semanticamente appropriate.
- Scalabilità flessibile: Offre una forte scalabilità, consentendo la personalizzazione e l'ottimizzazione in base a diversi scenari ed esigenze applicative, garantendo a sviluppatori e aziende una notevole flessibilità e autonomia.
Metodi di utilizzo
- Integrazione API: Gli utenti possono registrare un account sulla piattaforma ufficiale di Dark Side of the Moon, richiedere una chiave API e quindi integrare le funzionalità di Moonshot nelle loro applicazioni utilizzando l'API con linguaggi di programmazione compatibili.
- Utilizzo di prodotti e strumenti ufficiali: Utilizzare direttamente Kimichat, il prodotto di assistenza intelligente basato sul modello Moonshot, o sfruttare gli strumenti e le piattaforme associati offerti da Dark Side of the Moon.
- Integrazione con altri framework e strumenti: Moonshot può essere integrato con i più diffusi framework di sviluppo dell'intelligenza artificiale, come LangChain, per costruire applicazioni di modelli linguistici più robuste.
GLM-4-Plus di zhipu.ai
Introduzione sintetica
GLM-4-Plus, sviluppato da Zhipu AI, è l'ultima iterazione del modello di base GLM completamente sviluppato in proprio, con miglioramenti significativi nella comprensione del linguaggio, nel seguire le istruzioni e nell'elaborazione di testi lunghi.
Caratteristiche e vantaggi principali
- Forte comprensione della lingua: Addestrato su ampie serie di dati e su algoritmi ottimizzati, GLM-4-Plus eccelle nella gestione di semantiche complesse, interpretando accuratamente il significato e il contesto di vari testi.
- Elaborazione eccezionale di testi lunghi: Grazie a un meccanismo di memoria innovativo e a una tecnica di elaborazione segmentata, GLM-4-Plus è in grado di gestire efficacemente testi lunghi fino a 128k tokens, con un'elevata competenza nell'elaborazione dei dati e nell'estrazione delle informazioni.
- Capacità di ragionamento migliorate: Incorpora l'ottimizzazione della politica prossimale (PPO) per mantenere la stabilità e l'efficienza durante l'esplorazione delle soluzioni ottimali, migliorando significativamente le prestazioni del modello in compiti di ragionamento complessi come la matematica e la programmazione.
- Elevata precisione nel seguire le istruzioni: Comprende e rispetta con precisione le istruzioni dell'utente, generando testi di alta qualità e allineati alle aspettative in base ai requisiti dell'utente.
Istruzioni per l'uso
- Registrazione di un account e ottenimento di una chiave API: Innanzitutto, registrate un account sul sito ufficiale di Zhipu e acquisite una chiave API.
- Esaminare la documentazione ufficiale: Per i parametri dettagliati e le istruzioni d'uso, consultare la documentazione ufficiale della serie GLM-4.
SenseChat 5.5 di SenceTime
Introduzione sintetica
SenseChat 5.5, sviluppato da SenseTime, è la versione 5.5 del suo modello linguistico di grandi dimensioni, basato su InternLM-123b, uno dei primi modelli linguistici di grandi dimensioni della Cina costruito su trilioni di parametri e continuamente aggiornato.

Caratteristiche e vantaggi principali
- Prestazioni complete e potenti: Si posiziona costantemente tra i primi posti in una serie di compiti di valutazione, eccellendo nelle competenze fondamentali delle discipline umanistiche e scientifiche e nei compiti avanzati "difficili". Dimostra prestazioni superiori nella comprensione del linguaggio e nella sicurezza nelle materie umanistiche ed eccelle nella logica e nella codifica nelle materie scientifiche.
- Applicazioni Edge efficienti: SenseTime ha rilasciato la versione SenseChat Lite-5.5, che riduce il tempo di caricamento iniziale a soli 0,19 secondi, con un miglioramento di 40% rispetto a SenseChat Lite-5.0 rilasciato ad aprile, con una velocità di inferenza che raggiunge i 90,2 caratteri al secondo e un costo annuale per dispositivo di soli 9,9 yuan.
- Capacità linguistiche eccezionali: Come applicazione di linguaggio naturale, gestisce efficacemente dati testuali estesi, dimostrando un solido dialogo in linguaggio naturale, capacità di ragionamento logico, ampia conoscenza e aggiornamenti frequenti. Supporta il cinese semplificato, il cinese tradizionale, l'inglese e i più comuni linguaggi di programmazione.
Prodotti per l'uso e l'applicazione
- Uso diretto: Gli utenti possono registrarsi sul [sito web di SenseTime] per accedere a SenseChat attraverso il web o l'applicazione mobile e interagire con il modello.
- Integrazione API: SenseTime offre l'accesso alle API per le aziende e gli sviluppatori, consentendo loro di integrare SenseChat 5.5 nei loro prodotti o applicazioni.
Qwen2.5-72B-Istruzione del team Qwen, Alibaba Cloud
Modello di intorduzione
Qwen2.5 è l'ultima serie di modelli linguistici di grandi dimensioni Qwen. Per Qwen2.5Il team ha rilasciato una serie di modelli linguistici di base e di modelli linguistici tarati sulle istruzioni che vanno da 0,5 a 72 miliardi di parametri.
Caratteristiche principali
- Modelli linguistici densi, facili da usare, solo decodificati, disponibili in 0.5B, 1.5B, 3B, 7B, 14B, 32B, e 72B dimensioni e varianti di base e di istruzioni.
- Pre-addestrato sul nostro ultimo dataset su larga scala, che comprende fino a 18T gettoni.
- Miglioramenti significativi nel seguire le istruzioni, nel generare testi lunghi (oltre 8K token), nel comprendere dati strutturati (ad esempio, tabelle) e nel generare output strutturati, in particolare JSON.
- Più resistente alla diversità delle richieste del sistema, migliorando l'implementazione del gioco di ruolo e l'impostazione delle condizioni per i chatbot.
- La lunghezza del contesto supporta fino a 128K e può generare fino a 8K gettoni.
- Supporto multilingue per oltre 29 lingue, tra cui cinese, inglese, francese, spagnolo, portoghese, tedesco, italiano, russo, giapponese, coreano, vietnamita, tailandese, arabo e altre ancora.
Come iniziare rapidamente?
È possibile trovare esercitazioni per l'utilizzo di modelli di grandi dimensioni su Github e Hugging face. Sulla base di queste esercitazioni, è possibile eseguire efficacemente il modello e realizzare le proprie funzioni e idee.
Doubao-pro del team Doubao, ByteDance
Introduzione sintetica
Doubao-pro è un modello linguistico di grandi dimensioni sviluppato in modo indipendente da ByteDance e rilasciato ufficialmente il 15 maggio 2024. Nella piattaforma di valutazione Flageval per i modelli di grandi dimensioni, Doubao-pro si è classificato al secondo posto tra i modelli closed-source con un punteggio di 75,96.
- Versioni: Doubao-pro include versioni con finestre di contesto da 4k, 32k e 128k, ognuna delle quali supporta diverse lunghezze di contesto per l'inferenza e la messa a punto.
- Miglioramento delle prestazioni: Secondo i test interni di ByteDance, Doubao-pro-4k ha ottenuto un punteggio totale di 76,8 su 11 benchmark pubblici standard del settore.
Caratteristiche e vantaggi principali
- Forti capacità di comprensione: Doubao-pro eccelle in matematica, nell'applicazione delle conoscenze e nella risoluzione dei problemi nelle valutazioni oggettive e soggettive.
- Ampia gamma di applicazioni: Essendo uno dei modelli domestici più diffusi e versatili, l'assistente AI di Doubao, "Doubao", è al primo posto nei download tra le applicazioni AIGC sull'App Store di Apple e sui principali mercati di applicazioni Android.
- Alto rapporto costo-efficacia: Il costo di input dell'inferenza di Doubao-pro-32k è di soli 0,0008 yuan per mille token. Ad esempio, l'elaborazione della versione cinese di Harry Potter (2,74 milioni di caratteri) costa solo 1,5 yuan.
- Comprensione e generazione linguistica eccezionale: Doubao-pro comprende accuratamente diversi input in linguaggio naturale e genera risposte di alta qualità, coerenti e logiche, soddisfacendo le esigenze degli utenti in semplici domande e risposte, nella creazione di testi complessi e nelle spiegazioni in settori specializzati.
- Velocità di inferenza efficiente: Grazie alla formazione e all'ottimizzazione dei dati, Doubao-pro offre un vantaggio in termini di velocità di inferenza, consentendo tempi di risposta rapidi e una migliore esperienza utente, soprattutto quando si gestiscono grandi volumi di testo o attività complesse.
Metodi di utilizzo
- Attraverso il motore del vulcano: Utilizzare Doubao-pro richiamando l'API del modello, con esempi di codice disponibili nella documentazione ufficiale di Volcano Engine.
- Per prodotti specifici: Doubao-pro è disponibile per il mercato aziendale attraverso Volcano Engine, consentendo alle aziende di integrarlo nei loro prodotti o servizi. È possibile sperimentare il modello Doubao anche attraverso l'app Doubao.
360gpt2-pro di 360
Introduzione sintetica
- Nome del modello: 360GPT2-Pro fa parte della serie di modelli di grandi dimensioni sviluppata da 360 Zhibrain.
- Fondazione tecnica: Sfruttando 20 anni di dati sulla sicurezza, 10 anni di esperienza nell'IA e l'esperienza di 80 esperti di IA e 100 esperti di sicurezza, 360 ha utilizzato 5.000 risorse GPU per 200 giorni per addestrare e ottimizzare il modello Zhibrain, di cui 360GPT2-Pro è una delle versioni avanzate.

Caratteristiche e vantaggi principali
- Generazione di linguaggio forte: Eccelle nei compiti di generazione linguistica, soprattutto nelle materie umanistiche, creando contenuti di alta qualità, creativi e logicamente coerenti, come storie e copywriting.
- Comprensione e applicazione robusta della conoscenza: Dotato di un'ampia base di conoscenze, interpreta e applica con precisione le informazioni per rispondere alle domande e risolvere efficacemente i problemi.
- Generazione migliorata basata sul reperimento: Competente nella generazione aumentata del reperimento, in particolare per il cinese, che consente al modello di generare risposte allineate alle esigenze dell'utente e ai dati del mondo reale, riducendo la probabilità di allucinazione.
- Caratteristiche di sicurezza avanzate: Grazie alla lunga esperienza di 360 nel campo della sicurezza, 360GPT2-Pro offre un livello di sicurezza e affidabilità in grado di affrontare efficacemente i vari rischi di sicurezza.
Metodi d'uso e prodotti correlati
- Ricerca 360AI: Integra 360GPT2-Pro con la funzionalità di ricerca per offrire agli utenti un'esperienza di ricerca più completa e approfondita.
- Browser 360AI: Incorpora il 360GPT2-Pro nel 360AI Browser, consentendo agli utenti di interagire con il modello tramite interfacce specifiche o tramite input vocale per ottenere informazioni e suggerimenti.
Step-2-16k da stepfun
Introduzione sintetica
- Sviluppatore: StepStar ha rilasciato la versione ufficiale del Modello linguistico STEP-2 a mille miliardi di parametri nel 2024, con step-2-16k che si riferisce alla sua variante che supporta una finestra di contesto di 16k.
- Modello di architettura: Costruito su un'innovativa architettura MoE (Mixture of Experts), che attiva dinamicamente diversi modelli di esperti in base ai compiti e alla distribuzione dei dati, migliorando sia le prestazioni che l'efficienza.
- Scala dei parametri: Con un trilione di parametri, il modello cattura un'ampia conoscenza del linguaggio e informazioni semantiche, mostrando potenti capacità in diversi compiti di elaborazione del linguaggio naturale.

Caratteristiche e vantaggi principali
- Comprensione e generazione di linguaggio potente: Interpreta accuratamente il testo in ingresso e genera risposte naturali di alta qualità, supportando attività quali la risposta a domande, la generazione di contenuti e lo scambio di conversazioni con precisione e valore.
- Copertura della conoscenza multidominio: Addestrato su enormi insiemi di dati, il modello comprende un'ampia conoscenza di aree quali la matematica, la logica, la programmazione, la conoscenza e la scrittura creativa, rendendolo versatile per risposte e applicazioni trasversali.
- Capacità di elaborazione di sequenze lunghe: Con una finestra contestuale da 16k, il modello eccelle nella gestione di lunghe sequenze di testo, facilitando la comprensione e l'elaborazione di articoli lunghi e documenti complessi.
- Prestazioni vicine al GPT-4: Con prestazioni vicine al GPT-4 in diversi compiti linguistici, questo modello mostra capacità di elaborazione linguistica completa di alto livello.
Uso e applicazioni
StepStar fornisce una piattaforma aperta per le imprese e gli sviluppatori per richiedere l'accesso alla modello step-2-16k.
Gli utenti possono integrare il modello in applicazioni o progetti di sviluppo tramite chiamate API, utilizzando la documentazione e gli strumenti di sviluppo forniti dalla piattaforma per implementare varie funzionalità di elaborazione del linguaggio naturale.
DeepSeek-V2.5 da deepseek
Introduzione sintetica
DeepSeek-V2.5, sviluppato dal team di DeepSeek, è un potente modello linguistico open-source che integra le funzionalità di DeepSeek-V2-Chat e DeepSeek-Coder-V2-Instruct, rappresentando il culmine dei precedenti progressi del modello. I dettagli principali sono i seguenti:
- Storia dello sviluppo: Nel settembre 2024 è stato rilasciato ufficialmente DeepSeek-V2.5, che combina le funzionalità di chat e codifica. Questa versione migliora sia le competenze linguistiche generali che le funzionalità di codifica.
- Natura open source: In linea con l'impegno per lo sviluppo open-source, DeepSeek-V2.5 è ora disponibile su Hugging Face, consentendo agli sviluppatori di regolare e ottimizzare il modello secondo le necessità.

Caratteristiche e vantaggi principali
- Abilità linguistiche e di codifica combinate: DeepSeek-V2.5 mantiene le capacità di conversazione di un modello di chat e i punti di forza di codifica di un modello di codificatore, rendendolo una vera e propria soluzione "all-in-one" in grado di gestire le conversazioni quotidiane, di seguire istruzioni complesse, di generare codice e di completarlo.
- Allineamento delle preferenze umane: Ottimizzato per allinearsi alle preferenze umane, il modello è stato ottimizzato per la qualità della scrittura e l'aderenza alle istruzioni, con prestazioni più naturali e intelligenti in più attività per comprendere meglio e soddisfare le esigenze degli utenti.
- Prestazioni eccezionali: DeepSeek-V2.5 supera le versioni precedenti in vari benchmark e ottiene i migliori risultati in benchmark di codifica come humaneval python e live code bench, dimostrando la sua forza nell'aderenza alle istruzioni e nella generazione di codice.
- Supporto contestuale esteso: Con una lunghezza massima del contesto di 128k token, DeepSeek-V2.5 è in grado di gestire efficacemente testi lunghi e dialoghi a più voci.
- Alto rapporto costo-efficacia: Rispetto ai modelli closed-source di alto livello come Claude 3.5 Sonetto e GPT-4o, DeepSeek-V2.5 offre un vantaggio significativo in termini di costi.
Metodi di utilizzo
- Tramite la piattaforma web: Accedere a DeepSeek-V2.5 attraverso piattaforme web come il parco giochi DeepSeek-V2.5 di SiliconCloud.
- Tramite API: Gli utenti possono creare un account per ottenere una chiave API, quindi integrare DeepSeek-V2.5 nei loro sistemi attraverso l'API per lo sviluppo e le applicazioni secondarie.
- Distribuzione locale: Richiede 8 GPU da 80 GB ciascuna, utilizzando i Transformers di Hugging Face per l'inferenza. Fare riferimento alla documentazione e al codice di esempio per i passaggi specifici.
- All'interno di prodotti specifici:
- Cursore: Questo editor di codice AI, basato su VSCode, consente agli utenti di configurare il modello DeepSeek-V2.5, collegandosi all'API di SiliconCloud per la generazione di codice on-page tramite scorciatoie, migliorando l'efficienza della codifica.
- Altri strumenti o piattaforme di sviluppo: Qualsiasi strumento o piattaforma di sviluppo che supporti API di modelli linguistici esterni può teoricamente integrare DeepSeek-V2.5 ottenendo una chiave API, abilitando la generazione del linguaggio e le capacità di scrittura del codice.
Ernie-4.0-turbo-8k-preview da Baidu
Introduzione sintetica
Ernie-4.0-turbo-8k-preview fa parte della serie ERNIE 4.0 Turbo di Baidu, rilasciata ufficialmente il 28 giugno 2024 e aperta completamente ai clienti aziendali il 5 luglio 2024.
Caratteristiche e vantaggi principali
- Miglioramento delle prestazioni: Come versione aggiornata di ERNIE 4.0, questo modello estende la lunghezza dell'input contestuale da 2k token a 8k token, consentendo di gestire insiemi di dati più grandi, di leggere un maggior numero di documenti o URL e di ottenere migliori prestazioni in compiti che coinvolgono testi lunghi.
- Riduzione dei costi: I costi di input e output di ERNIE 4.0-turbo-8k-preview sono pari a 0,03 CNY per 1.000 gettoni e 0,06 CNY per 1.000 gettoni, con una riduzione di prezzo di 70% rispetto alla versione generale di ERNIE 4.0.
- Ottimizzazione tecnica: Potenziato dalla tecnologia turbo, questo modello ottiene un duplice miglioramento della velocità di addestramento e delle prestazioni, consentendo un addestramento e una distribuzione più rapidi dei modelli.
- Ampia applicazione: Grazie ai suoi vantaggi in termini di prestazioni e di costi, il modello è ampiamente applicabile in campi quali il servizio clienti intelligente, gli assistenti virtuali, l'istruzione e l'intrattenimento, offrendo un'esperienza di conversazione fluida e naturale. Le sue solide capacità di generazione lo rendono inoltre molto adatto alla creazione di contenuti e all'analisi dei dati.
Utilizzo
L'ERNIE 4.0-turbo-8k-preview è disponibile principalmente per i clienti aziendali, che possono accedervi tramite la piattaforma Qianfan Large Model di Baidu su Baidu Intelligent Cloud.
Top 10 dei modelli di intelligenza artificiale creati da un'azienda cinese
| Modello | Sviluppatore | Caratteristica principale e forza | Come usare |
| Hunyuan-Grande | Tencent | Open source, 398 miliardi di parametri | Scarica il modello |
| Colpo di luna (Kimi) | Intelligenza artificiale Moonshot | Capacità di elaborazione di testi lunghi, elevata comprensione della lingua | API, App ufficiale e strumenti |
| GLM-4-Più | zhipu.ai | comprensione linguistica, capacità di seguire istruzioni ed elaborazione di testi lunghi. | API |
| SenseChat 5.5 | Tempo di Senso | Prestazioni potenti e complete, capacità linguistiche eccezionali | Sito web Sensetime, API |
| Qwen2.5-72B | Nuvola di Alibaba | La lunghezza del contesto supporta fino a 128K, supporto multilingue per oltre 29 lingue | Scarica il modello, sito ufficiale |
| Doubao-pro | ByteDanza | Forti capacità complete, elevata redditività, chatbot, | App Daobao, API |
| 360gpt2-pro | 360 | Funzionalità di sicurezza avanzate, generazione di linguaggio avanzato | Lobechat, browser 360AI |
| Passo 2-16k | divertimento graduale | modello linguistico da trilioni di parametri, copertura della conoscenza multi-dominio, prestazioni vicine a GPT-4 | API |
| DeepSeek-V2.5 | ricerca profonda | Abilità linguistiche e di codifica combinate, allineamento delle preferenze umane | Piattaforma web, API, distribuzione locale |
| Ernie-4.0-turbo-8k | Baidu | Ampia applicazione, riduzione dei costi, | Solo clienti aziendali |


