
Редактирование портретного видео с помощью
Мультимодальные генеративные априорные данные
Традиционные методы редактирования портретного видео часто имеют проблемы с 3D-эффектами и временной согласованностью, а также плохо работают с точки зрения качества рендеринга и эффективности. Для решения этих проблем PortraitGen поднимает каждый кадр портретного видео в единое динамическое 3D-гауссово поле, что обеспечивает структурную и временную согласованность от кадра к кадру.PortraitGen — это мощный метод редактирования портретного видео, который позволяет добиться последовательной и выразительной стилизации с помощью многомодальных сигналов.
Кроме того, PortraitGen разработал новый нейронный механизм гауссовского текстурирования, который не только позволяет выполнять сложное стилистическое редактирование, но и обеспечивает скорость рендеринга свыше 100 кадров в секунду.PortraitGen объединяет широкий спектр входных данных, которые улучшены знаниями, полученными из крупномасштабных 2D-генеративных моделей. Он также вводит руководство по схожести выражений и модуль редактирования портретов распознавания лиц, эффективно уменьшая проблемы, которые могут возникнуть при итеративном обновлении набора данных. (Ссылка внизу статьи)
01 Содержание заголовка
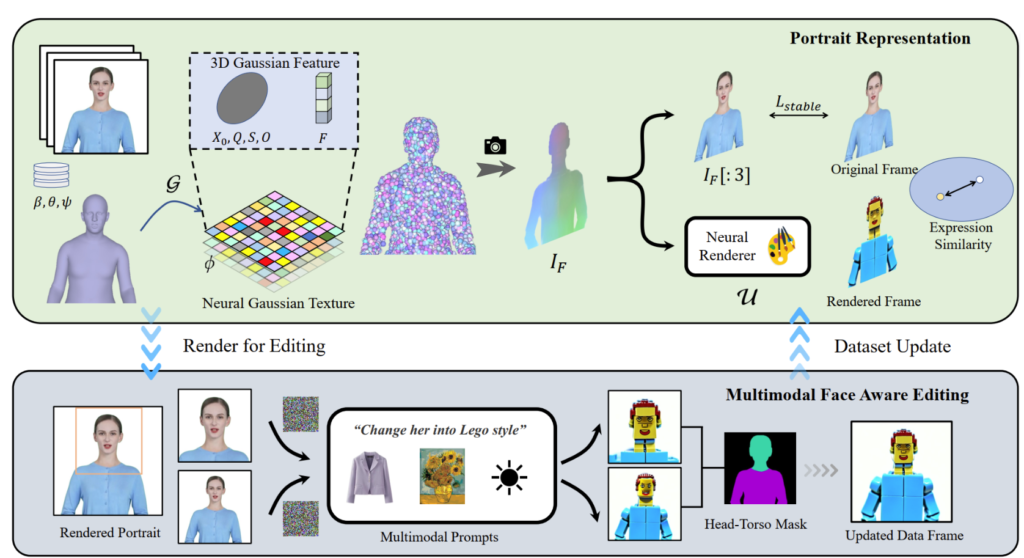
PortraitGen всего за 30 минут преобразует 2D-портретные видео в 4D-гауссово поле для мультимодального редактирования портретов. Отредактированный 3D-портрет может быть отрисован со скоростью 100 кадров в секунду. Сначала отслеживаются коэффициенты SMPL-X в монокулярном видео, а затем генерируется 3D-гауссово поле признаков с использованием механизма нейро-гауссовской текстуры.
Эти нейрогауссовские данные дополнительно обрабатываются для визуализации портретного изображения. PortraitGen также использует стратегию итеративного обновления набора данных для редактирования портретов и предлагает модуль редактирования распознавания лиц для повышения качества выражений и сохранения индивидуальной структуры лица.
02 Практическое использование
Решение PortraitGen — это унифицированная структура для редактирования портретных видео. Любая модель редактирования изображений, которая сохраняет структуру, может использоваться для создания 3D-согласованных и временно согласованных портретных видео.
Текстовое редактирование: InstructPix2Pix используется как модель 2D-редактирования. Его UNet требует три входа: входное изображение RGB, текстовую команду и скрытый шум. Добавляет шум к визуализированному изображению и редактирует его на основе входного исходного изображения и инструкций.
Редактирование на основе изображений: фокусируется на двух типах редактирования, основанных на подсказках изображений. Один из них заключается в извлечении глобального стиля эталонного изображения, а другой — в настройке изображения путем размещения объектов в определенных местах. Эти методы используются экспериментально для миграции стиля и виртуальной подгонки. Стиль эталонного изображения был перенесен в кадры набора данных с помощью алгоритма Neural Style Migration, а одежда субъекта была изменена с помощью AnyDoor.
Relighting: использование IC-Light для управления освещением видеокадров. При наличии текстового описания в качестве условия освещения метод PortraitGen гармонично регулирует освещение портретного видео
03 Эксперименты по контрастированию и абляции
Метод PortraitGen сравнивается с современными методами редактирования видео, включая TokenFlow, Rerender A Video, CoDeF и AnyV2V. Метод PortraitGen значительно превосходит другие методы с точки зрения сохранения «точно в срок», сохранения идентичности и временной согласованности.
Продолжительность 00:47
Вдохновленный нейронной текстурой, предложенной в «Delayed Neural Rendering», PortraitGen предлагает нейронную гауссову текстуру. Этот подход сохраняет изучаемые признаки для каждого гауссиана вместо хранения сферических гармонических коэффициентов. Затем используется 2D нейронный рендерер для преобразования обработанных карт признаков в сигналы RGB. Этот метод предоставляет более богатую информацию, чем сферические гармонические коэффициенты, и позволяет лучше объединять обработанные признаки, что упрощает редактирование сложных стилей, таких как Lego и пиксельная графика.
При редактировании изображения верхней части тела, если лицо занимает небольшую область, редактирование модели может быть недостаточно адаптировано к позе головы и структуре лица. Редактирование портрета с учетом черт лица (FA) может улучшить результаты, выполнив два редактирования для усиления фокуса на структуре лица.
Сопоставляя визуализированное изображение и входное исходное изображение с пространством скрытых выражений EMOCA и оптимизируя сходство выражений, мы можем гарантировать, что выражения останутся естественными и будут соответствовать исходным видеокадрам.
Технология PortraitGen
Ссылка
Более подробную информацию о PotraitGen можно найти здесь: https://ustc3dv.github.io/PortraitGen/
