

O que é o modelo LLM?
Definição e visão geral
Um modelo de IA é um programa que foi treinado em um conjunto de dados para reconhecer certos padrões ou tomar certas decisões sem intervenção humana adicional.
Grandes modelos de linguagem, também conhecidos como Mestrado em Direito, são modelos de aprendizado profundo muito grandes que são pré-treinados em grandes quantidades de dados.
O transformador subjacente é um conjunto de redes neurais que consistem em um codificador e um decodificador com capacidades de autoatenção. O codificador e o decodificador extraem significados de uma sequência de texto e entendem as relações entre palavras e frases nele.
Qual é o melhor modelo para você?
Grandes modelos de IA estão se desenvolvendo muito rapidamente. Diferentes empresas e instituições de pesquisa apresentam novas conquistas de pesquisa diariamente, junto com novos grandes modelos de linguagem.
Portanto, não podemos dizer definitivamente qual é o melhor.
No entanto, há empresas e modelos de primeira linha, como a OpenAI. Agora há um conjunto de padrões e perguntas de teste para avaliar modelos.
Você pode consultar superpista para visualizar as pontuações do modelo em várias tarefas e escolher a que mais lhe convém. Além disso, você pode acompanhar as últimas notícias para saber mais sobre a capacidade do modelo LLM.
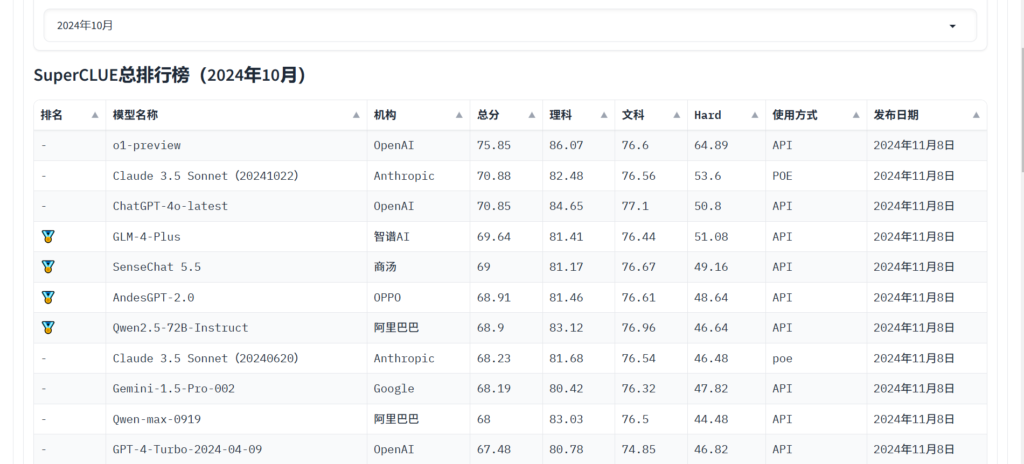
Hunyuan-Large da Tencent
Introdução do modelo
Em 5 de novembro, Tencent lança o modelo de linguagem grande MoE de código aberto Hunyuan-large com um total de 398 bilhões de parâmetros, tornando-o o maior do setor, com 52 bilhões de parâmetros de ativação.
Os resultados da avaliação pública mostram que o modelo Hunyuan Large da Tencent lidera de forma abrangente em vários projetos.

Vantagens técnicas
- Dados sintéticos de alta qualidade:Ao aprimorar o treinamento com dados sintéticos, Hunyuan-Grande pode aprender representações mais ricas, lidar com entradas de contexto longo e generalizar melhor para dados invisíveis.
- Compressão de cache KV: Utiliza estratégias de Atenção de Consulta Agrupada (GQA) e Atenção entre Camadas (CLA) para reduzir significativamente o uso de memória e a sobrecarga computacional de caches KV, melhorando o rendimento da inferência.
- Escala de taxa de aprendizagem específica para especialistas: Define diferentes taxas de aprendizado para diferentes especialistas para garantir que cada submodelo aprenda efetivamente com os dados e contribua para o desempenho geral.
- Capacidade de processamento de contexto longo: O modelo pré-treinado suporta sequências de texto de até 256K, e o modelo Instruct suporta até 128K, melhorando significativamente a capacidade de lidar com tarefas de contexto longo.
- Benchmarking extensivo: Conduz experimentos extensivos em vários idiomas e tarefas para validar a eficácia prática e a segurança do Hunyuan-Large.
Estrutura de Inferência e Estrutura de Treinamento
Esta versão de código aberto oferece duas opções de backend de inferência adaptadas para o Modelo Hunyuan-Large: o popular vLLM-backend e o TensorRT-LLM Backend. Ambas as soluções incluem otimizações para desempenho aprimorado.
O modelo de código aberto Hunyuan-Large é totalmente compatível com o formato Hugging Face, permitindo que pesquisadores e desenvolvedores realizem ajustes finos de modelos usando a estrutura hf-deepspeed. Além disso, oferecemos suporte à aceleração de treinamento por meio do uso de atenção flash.
Como usar este modelo posteriormente
Este é um modelo de código aberto. Você pode encontrar “tencent-hunyuan” em GitHub, onde eles fornecem instruções detalhadas e guias de uso. Você pode explorar e pesquisar mais para criar mais possibilidades.
Tiro à Lua(Kimi) por Moonshot AI
Resumo Introdução
Moonshot é um modelo de linguagem em larga escala desenvolvido pela Dark Side of the Moon. Aqui está uma visão geral de seus recursos:
- Avanço tecnológico: A Moonshot alcança avanços notáveis no processamento de textos longos, com seu produto de assistente inteligente, Kimichat, suportando até 2 milhões de caracteres chineses em entrada de contexto sem perdas.
- Arquitetura do modelo: Ao empregar uma estrutura de rede inovadora e otimizações de engenharia, ele alcança atenção de longo alcance sem depender de soluções de "atalho" como janelas deslizantes, downsampling ou modelos menores que frequentemente degradam o desempenho. Isso permite uma compreensão abrangente de textos ultralongos, mesmo com centenas de bilhões de parâmetros.
- Orientado para aplicação: Desenvolvido com foco na aplicação prática, o Moonshot pretende se tornar uma ferramenta diária indispensável para os usuários, evoluindo com base no feedback real dos usuários para gerar valor tangível.

Caraterísticas principais
- Capacidade de processamento de texto longo: Capaz de lidar com textos extensos, como romances ou relatórios financeiros completos, oferecendo aos usuários insights e resumos detalhados e abrangentes de documentos longos.
- Fusão multimodal: Integra múltiplas modalidades, combinando texto com dados de imagem para aprimorar os recursos de análise e geração.
- Alta capacidade de compreensão e geração de linguagem: Demonstra excelente desempenho multilíngue, interpretando com precisão a entrada do usuário e gerando respostas de alta qualidade, coerentes e semanticamente apropriadas.
- Escalabilidade flexível: Oferece alta escalabilidade, permitindo personalização e otimização com base em diferentes cenários e necessidades de aplicação, proporcionando aos desenvolvedores e empresas flexibilidade e autonomia significativas.
Métodos de uso
- Integração de API: Os usuários podem registrar uma conta na plataforma oficial Dark Side of the Moon, solicitar uma chave de API e, então, integrar os recursos do Moonshot em seus aplicativos usando a API com linguagens de programação compatíveis.
- Usando produtos e ferramentas oficiais: Use diretamente o Kimichat, o produto de assistente inteligente baseado no modelo Moonshot, ou aproveite as ferramentas e plataformas associadas oferecidas pelo Dark Side of the Moon.
- Integração com outras estruturas e ferramentas: O Moonshot pode ser integrado com estruturas populares de desenvolvimento de IA, como o LangChain, para criar aplicativos de modelo de linguagem mais robustos.
GLM-4-Plus por zhipu.ai
Resumo Introdução
O GLM-4-Plus, desenvolvido pela Zhipu AI, é a mais recente iteração do modelo de base GLM totalmente desenvolvido pela empresa, com melhorias significativas na compreensão da linguagem, no acompanhamento de instruções e no processamento de textos longos.
Principais características e vantagens
- Forte compreensão da linguagem: Treinado em conjuntos de dados extensos e algoritmos otimizados, o GLM-4-Plus se destaca no tratamento de semântica complexa, interpretando com precisão o significado e o contexto de vários textos.
- Excelente processamento de texto longo: Com um mecanismo de memória inovador e técnica de processamento segmentado, o GLM-4-Plus pode efetivamente lidar com textos longos de até 128 mil tokens, tornando-o altamente proficiente em processamento de dados e extração de informações.
- Capacidades de raciocínio aprimoradas: Incorpora Otimização de Política Proximal (PPO) para manter a estabilidade e a eficiência ao explorar soluções ideais, melhorando significativamente o desempenho do modelo em tarefas de raciocínio complexas, como matemática e programação.
- Alta precisão de seguimento de instruções: Compreende e segue com precisão as instruções do usuário, gerando texto de alta qualidade e alinhado às expectativas com base nos requisitos do usuário.
Instruções de uso
- Registre uma conta e obtenha uma chave de API: Primeiro, registre uma conta no site oficial da Zhipu e adquira uma chave de API.
- Revise a documentação oficial: Consulte a documentação oficial da série GLM-4 para obter parâmetros detalhados e instruções de uso.
SenseChat 5.5 por SenceTime
Resumo Introdução
O SenseChat 5.5, desenvolvido pela SenseTime, é a versão 5.5 do seu grande modelo de linguagem, baseado no InternLM-123b, um dos primeiros grandes modelos de linguagem da China, construído em trilhões de parâmetros e continuamente atualizado.

Principais características e vantagens
- Desempenho abrangente e poderoso: Consistentemente se classifica entre os melhores em uma variedade de tarefas de avaliação, destacando-se em competências fundamentais em humanidades e ciências, bem como em tarefas avançadas "Hard". Demonstra desempenho superior em compreensão de linguagem e segurança em humanidades, e destaca-se em lógica e codificação em ciências.
- Aplicações Edge Eficientes: A SenseTime lançou a versão SenseChat Lite-5.5, que reduz o tempo de carregamento inicial para apenas 0,19 segundos, uma melhoria de 40% em relação ao SenseChat Lite-5.0 lançado em abril, com velocidade de inferência atingindo 90,2 caracteres por segundo e um custo anual por dispositivo tão baixo quanto 9,9 yuans.
- Capacidades linguísticas excepcionais: Como um aplicativo de linguagem natural, ele efetivamente lida com dados de texto extensos, demonstrando diálogos robustos de linguagem natural, habilidades de raciocínio lógico, amplo conhecimento e atualizações frequentes. Ele suporta chinês simplificado, chinês tradicional, inglês e linguagens de programação comuns.
Produtos de uso e aplicação
- Uso direto: Os usuários podem se registrar no [site SenseTime] para acessar o SenseChat pela web ou aplicativo móvel e interagir com o modelo.
- Integração de API: O SenseTime oferece acesso à API para empresas e desenvolvedores, permitindo que eles integrem o SenseChat 5.5 em seus produtos ou aplicativos.
Qwen2.5-72B-Instrutor da equipe Qwen, Alibaba Cloud
Introdução ao modelo
Qwen2.5 é a mais recente série de modelos de linguagem grande Qwen. Para Qwen2.5, a equipe lançou uma série de modelos de linguagem base e modelos de linguagem ajustados por instruções variando de 0,5 a 72 bilhões de parâmetros.
Principais características
- Modelos de linguagem densos, fáceis de usar e somente decodificadores, disponíveis em 0,5 B, 1,5 bilhões, 3B, 7B, 14B, 32Be 72B tamanhos e variantes de base e instrução.
- Pré-treinado em nosso mais recente conjunto de dados em larga escala, abrangendo até 18T fichas.
- Melhorias significativas no acompanhamento de instruções, geração de textos longos (mais de 8 mil tokens), compreensão de dados estruturados (por exemplo, tabelas) e geração de saídas estruturadas, especialmente JSON.
- Mais resiliente à diversidade de prompts do sistema, aprimorando a implementação de dramatização e a definição de condições para chatbots.
- O comprimento do contexto suporta até 128 mil tokens e pode gerar até 8K fichas.
- Suporte multilíngue para mais de 29 idiomas, incluindo chinês, inglês, francês, espanhol, português, alemão, italiano, russo, japonês, coreano, vietnamita, tailandês, árabe e muito mais.
Como começar rapidamente?
Você pode encontrar tutoriais para usar modelos grandes no Github e no Hugging face. Com base nesses tutoriais, você pode executar o modelo de forma eficaz e realizar suas funções e ideias.
Doubao-pro da equipe Doubao, ByteDance
Resumo Introdução
Doubao-pro é um grande modelo de linguagem desenvolvido de forma independente pela ByteDance, lançado oficialmente em 15 de maio de 2024. Na plataforma de avaliação Flageval para grandes modelos, o Doubao-pro ficou em segundo lugar entre os modelos de código fechado com uma pontuação de 75,96.
- Versões: O Doubao-pro inclui versões com janelas de contexto de 4k, 32k e 128k, cada uma suportando diferentes comprimentos de contexto para inferência e ajuste fino.
- Melhoria de desempenho:De acordo com os testes internos da ByteDance, o Doubao-pro-4k alcançou uma pontuação total de 76,8 em 11 benchmarks públicos padrão do setor.
Principais características e vantagens
- Fortes habilidades abrangentes: O Doubao-pro se destaca em matemática, aplicação de conhecimento e resolução de problemas em avaliações objetivas e subjetivas.
- Ampla gama de aplicações: Como um dos modelos domésticos mais amplamente utilizados e versáteis, o assistente de IA da Doubao, “Doubao”, ocupa o primeiro lugar em downloads entre os aplicativos AIGC na Apple App Store e nos principais mercados de aplicativos Android.
- Alta relação custo-eficácia: O custo de entrada de inferência do Doubao-pro-32k é de apenas 0,0008 yuans por mil tokens. Por exemplo, processar a versão chinesa de Harry Potter (2,74 milhões de caracteres) custa apenas 1,5 yuan.
- Excelente compreensão e geração de linguagem: O Doubao-pro compreende com precisão diversas entradas de linguagem natural e gera respostas lógicas, coerentes e de alta qualidade, atendendo às necessidades do usuário em perguntas e respostas simples, criação de textos complexos e explicações em campos especializados.
- Velocidade de inferência eficiente: Com amplo treinamento e otimização de dados, o Doubao-pro oferece uma vantagem de velocidade de inferência, permitindo tempos de resposta rápidos e melhor experiência do usuário, especialmente ao lidar com grandes volumes de texto ou tarefas complexas.
Métodos de uso
- Através do motor do vulcão: Use o Doubao-pro chamando a API do modelo, com exemplos de código disponíveis na documentação oficial do Volcano Engine.
- Para produtos específicos: O Doubao-pro está disponível para o mercado corporativo por meio do Volcano Engine, permitindo que as empresas o integrem em seus produtos ou serviços. Você também pode experimentar o modelo Doubao por meio do aplicativo Doubao.
360gpt2-pro por 360
Resumo Introdução
- Nome do modelo: : 360GPT2-Pro faz parte da série de modelos grandes 360 Zhibrain desenvolvida pela 360.
- Fundação Técnica: Aproveitando 20 anos de dados de segurança, 10 anos de experiência em IA e a expertise de 80 especialistas em IA e 100 especialistas em segurança, a 360 usou 5.000 recursos de GPU ao longo de 200 dias para treinar e otimizar o modelo Zhibrain, com o 360GPT2-Pro sendo uma de suas versões avançadas.

Principais características e vantagens
- Geração de Linguagem Forte: Destaca-se em tarefas de geração de linguagem, especialmente em humanidades, criando conteúdo de alta qualidade, criativo e logicamente coerente, como histórias e textos publicitários.
- Compreensão e aplicação de conhecimento robusto: Equipado com uma ampla base de conhecimento, ele interpreta e aplica informações com precisão para responder perguntas e resolver problemas de forma eficaz.
- Geração baseada em recuperação aprimorada: Competente em geração de recuperação aumentada, especialmente para chinês, permitindo que o modelo gere respostas alinhadas às necessidades do usuário e aos dados do mundo real, reduzindo a probabilidade de alucinação.
- Recursos de segurança aprimorados: Beneficiando-se da longa experiência da 360 em segurança, o 360GPT2-Pro oferece um nível de segurança e confiabilidade, abordando efetivamente vários riscos de segurança.
Métodos de uso e produtos relacionados
- Pesquisa 360AI: Integra o 360GPT2-Pro com a funcionalidade de pesquisa para fornecer aos usuários uma experiência de pesquisa mais abrangente e aprofundada.
- Navegador 360AI: Incorpora o 360GPT2-Pro ao navegador 360AI, permitindo que os usuários interajam com o modelo por meio de interfaces específicas ou por meio de entrada de voz para obter informações e sugestões.
Passo-2-16k por stepfun
Resumo Introdução
- Desenvolvedor: StepStar lançou a versão oficial do Modelo de linguagem de trilhões de parâmetros STEP-2 em 2024, com step-2-16k se referindo à sua variante que suporta uma janela de contexto de 16k.
- Arquitetura do modelo: Construído em uma arquitetura inovadora MoE (Mixture of Experts), que ativa dinamicamente diferentes modelos de especialistas com base em tarefas e distribuição de dados, melhorando o desempenho e a eficiência.
- Escala de Parâmetros: Com um trilhão de parâmetros, o modelo captura amplo conhecimento de linguagem e informações semânticas, exibindo recursos poderosos em diversas tarefas de processamento de linguagem natural.

Principais características e vantagens
- Compreensão e geração poderosa de linguagem: Interpreta com precisão o texto de entrada e gera respostas naturais de alta qualidade, apoiando tarefas como responder perguntas, geração de conteúdo e troca de conversação com precisão e valor.
- Cobertura de conhecimento multidomínio: Treinado em grandes conjuntos de dados, o modelo abrange amplo conhecimento em áreas como matemática, lógica, programação, conhecimento e escrita criativa, tornando-o versátil para respostas e aplicações entre domínios.
- Capacidade de processamento de sequência longa: Com uma janela de contexto de 16k, o modelo se destaca no tratamento de longas sequências de texto, facilitando a compreensão e o processamento de artigos longos e documentos complexos.
- Desempenho próximo ao GPT-4: Alcançando desempenho próximo ao GPT-4 em tarefas de múltiplos idiomas, este modelo demonstra habilidades abrangentes de processamento de linguagem de alto nível.
Uso e aplicações
O StepStar fornece uma plataforma aberta para empresas e desenvolvedores solicitarem acesso ao passo-2-modelo 16k.
Os usuários podem integrar o modelo em aplicativos ou projetos de desenvolvimento por meio de chamadas de API, usando documentação fornecida pela plataforma e ferramentas de desenvolvimento para implementar diversas funcionalidades de processamento de linguagem natural.
DeepSeek-V2.5 por deepseek
Resumo Introdução
DeepSeek-V2.5, desenvolvido pela equipe DeepSeek, é um poderoso modelo de linguagem de código aberto que integra os recursos do DeepSeek-V2-Chat e do DeepSeek-Coder-V2-Instruct, representando o ápice dos avanços anteriores do modelo. Os principais detalhes são os seguintes:
- Histórico de desenvolvimento: Em setembro de 2024, eles lançaram oficialmente o DeepSeek-V2.5, combinando recursos de chat e codificação. Esta versão aprimora tanto a proficiência geral da linguagem quanto a funcionalidade de codificação.
- Natureza de código aberto: Em linha com o compromisso com o desenvolvimento de código aberto, o DeepSeek-V2.5 agora está disponível no Hugging Face, permitindo que os desenvolvedores ajustem e otimizem o modelo conforme necessário.

Principais características e vantagens
- Capacidades combinadas de linguagem e codificação: O DeepSeek-V2.5 mantém as habilidades de conversação de um modelo de bate-papo e os pontos fortes de codificação de um modelo de codificador, tornando-o uma verdadeira solução "tudo em um" capaz de lidar com conversas cotidianas, instruções complexas, geração de código e conclusão.
- Alinhamento de Preferência Humana: Ajustado para se alinhar às preferências humanas, o modelo foi otimizado para qualidade de escrita e aderência às instruções, apresentando desempenho mais natural e inteligente em diversas tarefas para entender e atender melhor às necessidades do usuário.
- Desempenho excepcional: DeepSeek-V2.5 supera versões anteriores em vários benchmarks e alcança os melhores resultados em benchmarks de codificação como humaneval python e live code bench, demonstrando sua força em aderência às instruções e geração de código.
- Suporte de contexto estendido: Com um comprimento máximo de contexto de 128 mil tokens, o DeepSeek-V2.5 lida efetivamente com textos longos e diálogos com várias voltas.
- Alta relação custo-eficácia:Comparado aos modelos de código fechado de primeira linha, como Soneto Claude 3.5 e GPT-4o, DeepSeek-V2.5 oferece uma vantagem de custo significativa.
Métodos de uso
- Via Plataforma Web: Acesse o DeepSeek-V2.5 por meio de plataformas web como o playground DeepSeek-V2.5 da SiliconCloud.
- Por meio da API: Os usuários podem criar uma conta para obter uma chave de API e, em seguida, integrar o DeepSeek-V2.5 em seus sistemas por meio da API para desenvolvimento secundário e aplicativos.
- Implantação local: Requer 8 GPUs de 80 GB cada, usando Transformers do Hugging Face para inferência. Consulte a documentação e o código de exemplo para etapas específicas.
- Dentro de produtos específicos:
- Cursor: Este editor de código de IA, baseado no VSCode, permite que os usuários configurem o modelo DeepSeek-V2.5, conectando-se à API da SiliconCloud para geração de código na página por meio de atalhos, aumentando a eficiência da codificação.
- Outras ferramentas ou plataformas de desenvolvimento: Qualquer ferramenta ou plataforma de desenvolvimento que suporte APIs de modelos de linguagem externa pode, teoricamente, integrar o DeepSeek-V2.5 obtendo uma chave de API, permitindo recursos de geração de linguagem e escrita de código.
Ernie-4.0-turbo-8k-preview por Baidu
Resumo Introdução
Ernie-4.0-turbo-8k-preview faz parte da série ERNIE 4.0 Turbo da Baidu, lançada oficialmente em 28 de junho de 2024 e totalmente aberta a clientes empresariais em 5 de julho de 2024.
Principais características e vantagens
- Melhoria de desempenho: Como uma versão atualizada do ERNIE 4.0, este modelo estende o comprimento da entrada de contexto de 2 mil tokens para 8 mil tokens, permitindo que ele manipule conjuntos de dados maiores, leia mais documentos ou URLs e tenha melhor desempenho em tarefas que envolvem textos longos.
- Redução de custos: Os custos de entrada e saída do ERNIE 4.0-turbo-8k-preview são tão baixos quanto 0,03 CNY por 1.000 tokens e 0,06 CNY por 1.000 tokens, uma redução de preço de 70% em relação à versão geral do ERNIE 4.0.
- Otimização Técnica: Aprimorado pela tecnologia turbo, este modelo alcança melhorias duplas na velocidade de treinamento e no desempenho, permitindo treinamento e implantação mais rápidos do modelo.
- Ampla aplicação: Devido às suas vantagens de desempenho e custo, o modelo é amplamente aplicável em campos como atendimento inteligente ao cliente, assistentes virtuais, educação e entretenimento, proporcionando uma experiência de conversação suave e natural. Seus recursos robustos de geração também o tornam altamente adequado para criação de conteúdo e análise de dados.
Uso
O ERNIE 4.0-turbo-8k-preview está disponível principalmente para clientes corporativos, que podem acessá-lo por meio da Qianfan Large Model Platform da Baidu no Baidu Intelligent Cloud.
Os 10 melhores modelos de IA criados por uma empresa chinesa
| Modelo | Desenvolvedor | Característica principal e força | Como usar |
| Hunyuan-Grande | Tencent | Código aberto, 398 bilhões de parâmetros | Baixe o modelo |
| Tiro na Lua (kimi) | IA de tiro na lua | Capacidade de processamento de texto longo, alta compreensão da linguagem | API, aplicativo oficial e ferramentas |
| GLM-4-Plus | zhipu.ai | compreensão da linguagem, seguimento de instruções e processamento de textos longos. | API |
| SenseChat 5.5 | Tempo de Sentença | Desempenho abrangente e poderoso, capacidades linguísticas excepcionais | Site Sensetime, API |
| Qwen2.5-72B | Nuvem Alibaba | O comprimento do contexto suporta até 128K, suporte multilíngue para mais de 29 idiomas | Baixar modelo, site oficial |
| Doubao-pro | ByteDança | Fortes habilidades abrangentes, alta relação custo-benefício, chatbot, | Aplicativo Daobao, API |
| 360gpt2-pro | 360 | Recursos de segurança aprimorados, geração de linguagem forte | Lobechat, navegador 360AI |
| Passo-2-16k | diversão de passo | modelo de linguagem de trilhões de parâmetros, cobertura de conhecimento multidomínio, desempenho próximo ao GPT-4 | API |
| DeepSeek-V2.5 | busca profunda | Habilidades combinadas de linguagem e codificação, alinhamento de preferência humana | Plataforma web, API, implantação local |
| Ernie-4.0-turbo-8k | Baidu | Ampla aplicação, redução de custos, | Somente clientes empresariais |


