

Vad är LLM-modell?
Definition och översikt
En AI-modell är ett program som har tränats på en uppsättning data för att känna igen vissa mönster eller fatta vissa beslut utan ytterligare mänsklig inblandning.
Stora språkmodeller, även kända som LLMs, är mycket stora modeller för djupinlärning som är förtränade på stora mängder data.
Den underliggande transformatorn är en uppsättning neurala nätverk som består av en kodare och en avkodare med självuppmärksamhet. Kodaren och avkodaren extraherar betydelser från en textsekvens och förstår relationerna mellan ord och fraser i den.
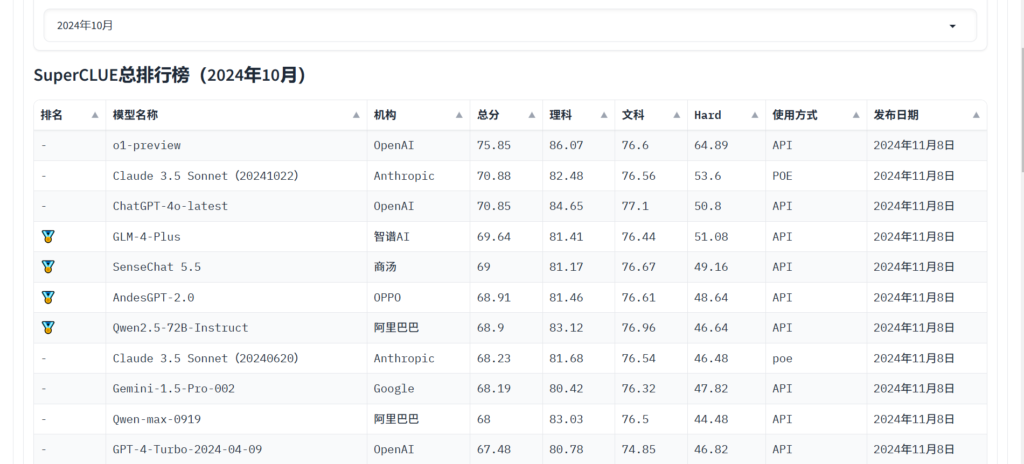
Vilken är den bästa modellen för dig?
AI stora modeller utvecklas mycket snabbt. Olika företag och forskningsinstitutioner presenterar dagligen nya forskningsresultat tillsammans med nya stora språkmodeller.
Därför kan vi inte definitivt säga vilken som är bäst.
Det finns dock företag och modeller i toppklassen, som OpenAI. Det finns nu en uppsättning standarder och testfrågor för att utvärdera modeller.
Du kan hänvisa till superclueai för att se modellens poäng i olika uppgifter och välja den som passar dig. Du kan också följa de senaste nyheterna för att veta mer om förmågan hos LLM-modellen.
Hunyuan-Large av Tencent
Modellintroduktion
Den 5 november, Tencent släpper Open-Source MoE Large Language Model Hunyuan-stor med totalt 398 miljarder parametrar, vilket gör den till den största i branschen, med 52 miljarder aktiveringsparametrar.
Offentliga utvärderingsresultat visar att Tencents Hunyuan Large-modell leder heltäckande i olika projekt.

Tekniska fördelar
- Syntetisk data av hög kvalitet: Genom att förbättra träningen med syntetiska data, Hunyuan-stor kan lära sig rikare representationer, hantera långa sammanhangsinmatningar och generalisera bättre till osynliga data.
- KV-cachekomprimering: Använder strategier för Grouped Query Attention (GQA) och Cross-Layer Attention (CLA) för att avsevärt minska minnesanvändning och beräkningsoverhead för KV-cacher, vilket förbättrar slutledningskapaciteten.
- Expertspecifik inlärningshastighetsskalning: Ställer in olika inlärningshastigheter för olika experter för att säkerställa att varje undermodell effektivt lär sig av data och bidrar till övergripande prestanda.
- Långkontextbehandlingskapacitet: Den förtränade modellen stöder textsekvenser upp till 256K, och Instruct-modellen stöder upp till 128K, vilket avsevärt förbättrar förmågan att hantera uppgifter med långa sammanhang.
- Omfattande benchmarking: Genomför omfattande experiment över olika språk och uppgifter för att validera den praktiska effektiviteten och säkerheten hos Hunyuan-Large.
Inferensramverk och utbildningsramverk
Den här versionen med öppen källkod erbjuder två slutledningsalternativ som är skräddarsydda för Hunyuan-stor modell: den populära vLLM-backend och den TensorRT-LLM Backend. Båda lösningarna inkluderar optimeringar för förbättrad prestanda.
Hunyuan-Large-modellen med öppen källkod är helt kompatibel med formatet Hugging Face, vilket gör det möjligt för forskare och utvecklare att utföra finjustering av modeller med ramverket hf-deepspeed. Dessutom stödjer vi träningsacceleration genom att använda blixtuppmärksamhet.
Hur man använder denna modell vidare
Detta är en modell med öppen källkod. Du kan hitta "tencent-hunyuan" på GitHub, där de tillhandahåller detaljerade instruktioner och bruksanvisningar. Du kan utforska och undersöka det ytterligare för att skapa fler möjligheter.
Moonshot(Kimi) av Moonshot AI
Sammanfattning Introduktion
Moonshot är en storskalig språkmodell utvecklad av Dark Side of the Moon. Här är en översikt över dess funktioner:
- Tekniskt genombrott: Moonshot uppnår anmärkningsvärda framsteg inom bearbetning av lång text, med sin smarta assistentprodukt, Kimichat, som stöder upp till 2 miljoner kinesiska tecken i förlustfri kontextinmatning.
- Modell arkitektur: Genom att använda en innovativ nätverksstruktur och tekniska optimeringar uppnår den uppmärksamhet på lång räckvidd utan att förlita sig på "genvägslösningar" som skjutbara fönster, nedsampling eller mindre modeller som ofta försämrar prestandan. Detta möjliggör omfattande förståelse av ultralånga texter även med hundratals miljarder parametrar.
- Applikationsorienterad: Moonshot har utvecklats med fokus på praktisk tillämpning och syftar till att bli ett oumbärligt dagligt verktyg för användare, som utvecklas baserat på verklig användarfeedback för att generera påtagligt värde.

Nyckelfunktioner
- Möjlighet att bearbeta lång text: Kan hantera omfattande texter som romaner eller fullständiga finansiella rapporter, erbjuda användarna djupgående, omfattande insikter och sammanfattningar av långa dokument.
- Multimodal Fusion: Integrerar flera modaliteter, kombinerar text med bilddata för att förbättra analys- och genereringsmöjligheter.
- Hög språkförståelse och generationsförmåga: Uppvisar utmärkt flerspråkig prestanda, tolkar användarinmatning korrekt och genererar högkvalitativa, sammanhängande och semantiskt lämpliga svar.
- Flexibel skalbarhet: Erbjuder stark skalbarhet, vilket möjliggör anpassning och optimering baserat på olika applikationsscenarier och behov, vilket ger utvecklare och företag betydande flexibilitet och självständighet.
Användningsmetoder
- API-integration: Användare kan registrera sig för ett konto på Dark Side of the Moons officiella plattform, ansöka om en API-nyckel och sedan integrera Moonshots funktioner i sina applikationer med hjälp av API:t med kompatibla programmeringsspråk.
- Använda officiella produkter och verktyg: Använd Kimichat direkt, den smarta assistentprodukten baserad på Moonshot-modellen, eller utnyttja associerade verktyg och plattformar som erbjuds av Dark Side of the Moon.
- Integration med andra ramverk och verktyg: Moonshot kan integreras med populära AI-utvecklingsramverk som LangChain för att bygga mer robusta språkmodellapplikationer.
GLM-4-Plus från zhipu.ai
Sammanfattning Introduktion
GLM-4-Plus, utvecklad av Zhipu AI, är den senaste iterationen av den helt egenutvecklade GLM-grundmodellen, med betydande förbättringar av språkförståelse, instruktionsföljning och långtextbehandling.
Nyckelfunktioner och fördelar
- Stark språkförståelse: Utbildad i omfattande datauppsättningar och optimerade algoritmer, GLM-4-Plus utmärker sig på att hantera komplex semantik, och korrekt tolka innebörden och sammanhanget för olika texter.
- Enastående bearbetning av lång text: Med en innovativ minnesmekanism och segmenterad bearbetningsteknik kan GLM-4-Plus effektivt hantera långa texter upp till 128 000 tokens, vilket gör den mycket skicklig i databearbetning och informationsextraktion.
- Förbättrade resonemangsmöjligheter: Inkorporerar Proximal Policy Optimization (PPO) för att bibehålla stabilitet och effektivitet samtidigt som optimala lösningar utforskas, vilket avsevärt förbättrar modellens prestanda i komplexa resonemangsuppgifter som matematik och programmering.
- Hög noggrannhet i instruktionerna: Förstår och följer användarinstruktionerna noggrant, genererar högkvalitativ, förväntningsjusterad text baserad på användarens krav.
Användningsinstruktioner
- Registrera ett konto och skaffa en API-nyckel: Registrera först ett konto på Zhipus officiella webbplats och skaffa en API-nyckel.
- Granska officiell dokumentation: Se den officiella GLM-4-seriens dokumentation för detaljerade parametrar och användningsinstruktioner.
SenseChat 5.5 av SenceTime
Sammanfattning Introduktion
SenseChat 5.5, utvecklad av SenseTime, är 5.5-versionen av dess stora språkmodell, baserad på InternLM-123b, en av Kinas tidigaste stora språkmodeller byggd på biljoner parametrar och uppdateras kontinuerligt.

Nyckelfunktioner och fördelar
- Kraftfull omfattande prestanda: rankas konsekvent i toppskiktet i en mängd olika utvärderingsuppgifter, och utmärker sig över grundläggande kompetenser inom humaniora och vetenskap samt avancerade "hårda" uppgifter. Det visar överlägsna prestationer i språkförståelse och säkerhet inom humaniora, och utmärker sig i logik och kodning inom vetenskap.
- Effektiva Edge-applikationer: SenseTime har släppt SenseChat Lite-5.5-versionen, som minskar den initiala laddningstiden till bara 0,19 sekunder, en 40%-förbättring jämfört med SenseChat Lite-5.0 som släpptes i april, med slutledningshastigheten på 90,2 tecken per sekund och en årlig kostnad per enhet så låg som 9,9 yuan.
- Exceptionella språkkunskaper: Som ett naturligt språkprogram hanterar det effektivt omfattande textdata, visar robust dialog med naturligt språk, logiska resonemangsförmåga, bred kunskap och frekventa uppdateringar. Den stöder förenklad kinesiska, traditionell kinesiska, engelska och vanliga programmeringsspråk.
Användnings- och applikationsprodukter
- Direkt användning: Användare kan registrera sig på [SenseTime-webbplatsen] för att komma åt SenseChat via webben eller mobilappen och interagera med modellen.
- API-integration: SenseTime erbjuder API-åtkomst för företag och utvecklare, vilket gör att de kan integrera SenseChat 5.5 i sina produkter eller applikationer.
Qwen2.5-72B-Instruktion av Qwen-teamet, Alibaba Cloud
Modellintroduktion
Qwen2.5 är den senaste serien av Qwen stora språkmodeller. För Qwen2,5, släppte teamet ett antal basspråksmodeller och instruktionsinställda språkmodeller från 0,5 till 72 miljarder parametrar.
Nyckelfunktioner
- Täta, lättanvända språkmodeller med endast dekoder, tillgängliga i 0,5B, 1,5B, 3B, 7B, 14B, 32B, och 72B storlekar och bas- och instruktionsvarianter.
- Förutbildad på vår senaste storskaliga dataset, som omfattar upp till 18T polletter.
- Betydande förbättringar i instruktionsföljning, generering av långa texter (över 8K tokens), förståelse av strukturerad data (t.ex. tabeller) och generering av strukturerade utdata, särskilt JSON.
- Mer motståndskraftig mot mångfalden av systemuppmaningar, förbättrar rollspelsimplementering och villkorsinställning för chatbots.
- Kontextlängd stöder upp till 128K tokens och kan generera upp till 8K polletter.
- Flerspråkigt stöd för över 29 språk, inklusive kinesiska, engelska, franska, spanska, portugisiska, tyska, italienska, ryska, japanska, koreanska, vietnamesiska, thailändska, arabiska och mer.
Hur kommer man snabbt igång?
Du kan hitta tutorials för att använda stora modeller på Github och Hugging face. Baserat på dessa handledningar kan du effektivt köra modellen och förverkliga dina funktioner och idéer.
Doubao-pro av Doubao Team, ByteDance
Sammanfattning Introduktion
Doubao-pro är en stor språkmodell oberoende utvecklad av ByteDance, officiellt släppt den 15 maj 2024. I Flagevals utvärderingsplattform för stora modeller rankades Doubao-pro på andra plats bland modeller med sluten källkod med en poäng på 75,96.
- Versioner: Doubao-pro inkluderar versioner med 4k, 32k och 128k kontextfönster, var och en stöder olika kontextlängder för slutledning och finjustering.
- Prestandaförbättring: Enligt ByteDances interna tester uppnådde Doubao-pro-4k ett totalpoäng på 76,8 över 11 offentliga riktmärken enligt branschstandard.
Nyckelfunktioner och fördelar
- Starka övergripande förmågor: Doubao-pro utmärker sig i matematik, kunskapstillämpning och problemlösning över objektiva och subjektiva utvärderingar.
- Brett utbud av applikationer: Som en av de mest använda och mångsidiga inhemska modellerna, rankas Doubaos AI-assistent, "Doubao", först i nedladdningar bland AIGC-applikationer på Apple App Store och stora Android-appmarknader.
- Hög kostnadseffektivitet: Doubao-pro-32k:s slutledningskostnad är endast 0,0008 yuan per tusen tokens. Till exempel att bearbeta den kinesiska versionen av Harry Potter (2,74 miljoner tecken) kostar bara 1,5 yuan.
- Enastående språkförståelse och generering: Doubao-pro förstår noggrant olika naturliga språkinmatningar och genererar högkvalitativa, sammanhängande och logiska svar, möter användarnas behov i enkla frågor och svar, komplex textskapande och förklaringar inom specialiserade områden.
- Effektiv slutledningshastighet: Med omfattande dataträning och optimering erbjuder Doubao-pro en fördel med inferenshastighet, vilket möjliggör snabba svarstider och förbättrad användarupplevelse, särskilt när du hanterar stora volymer text eller komplexa uppgifter.
Användningsmetoder
- Genom Volcano Engine: Använd Doubao-pro genom att anropa modellens API, med kodexempel tillgängliga i Volcano Engines officiella dokumentation.
- För specifika produkter: Doubao-pro är tillgängligt för företagsmarknaden genom Volcano Engine, vilket gör att företag kan integrera det i sina produkter eller tjänster. Du kan också uppleva Doubao-modellen genom Doubao-appen.
360gpt2-pro med 360
Sammanfattning Introduktion
- Modellnamn: 360GPT2-Pro är en del av 360 Zhibrain stora modellserie utvecklad av 360.
- Tekniska stiftelsen: Med hjälp av 20 års säkerhetsdata, 10 års erfarenhet av AI och expertis från 80 AI och 100 säkerhetsexperter använde 360 5 000 GPU-resurser under 200 dagar för att träna och optimera Zhibrain-modellen, med 360GPT2-Pro som en av dess avancerade versioner.

Nyckelfunktioner och fördelar
- Stark språkgenerering: Utmärker sig i språkgenereringsuppgifter, särskilt inom humaniora, genom att skapa högkvalitativt, kreativt och logiskt sammanhängande innehåll, såsom berättelser och copywriting.
- Robust kunskapsförståelse och tillämpning: Utrustad med en bred kunskapsbas, tolkar och tillämpar den information korrekt för att svara på frågor och lösa problem effektivt.
- Förbättrad hämtning-baserad generation: Kompetent i återvinningsförstärkt generation, särskilt för kinesiska, vilket gör att modellen kan generera svar som är anpassade till användarnas behov och verkliga data, vilket minskar sannolikheten för hallucinationer.
- Förbättrade säkerhetsfunktioner: 360GPT2-Pro drar nytta av 360:s mångåriga expertis inom säkerhet och ger en nivå av säkerhet och tillförlitlighet, som effektivt hanterar olika säkerhetsrisker.
Användningsmetoder och relaterade produkter
- 360AI Sök: Integrerar 360GPT2-Pro med sökfunktionalitet för att ge användarna en mer omfattande och djupgående sökupplevelse.
- 360AI webbläsare: Inkorporerar 360GPT2-Pro i webbläsaren 360AI, så att användare kan interagera med modellen via specifika gränssnitt eller genom röstinmatning för att få information och förslag.
Step-2-16k av stepfun
Sammanfattning Introduktion
- Framkallare: StepStar släppte den officiella versionen av STEG-2 biljoner-parameter språkmodell 2024, med steg-2-16k som hänvisar till dess variant som stöder ett 16k kontextfönster.
- Modell arkitektur: Byggd på en innovativ MoE-arkitektur (Mixture of Experts), som dynamiskt aktiverar olika expertmodeller baserat på uppgifter och datadistribution, vilket förbättrar både prestanda och effektivitet.
- Parameterskala: Med en biljon parametrar fångar modellen omfattande språkkunskaper och semantisk information, och visar kraftfulla funktioner för olika bearbetningsuppgifter för naturligt språk.

Nyckelfunktioner och fördelar
- Kraftfull språkförståelse och generering: Tolkar inmatad text noggrant och genererar naturliga svar av hög kvalitet, stödjande uppgifter som att svara på frågor, generera innehåll och utbyte av samtal med noggrannhet och värde.
- Kunskapstäckning för flera domäner: Modellen är utbildad i massiva datamängder och omfattar bred kunskap inom områden som matematik, logik, programmering, kunskap och kreativt skrivande, vilket gör den mångsidig för svar och applikationer över flera domäner.
- Långsekvensbearbetningsförmåga: Med ett 16k kontextfönster utmärker modellen sig på att hantera långa textsekvenser, vilket underlättar förståelsen och bearbetningen av långa artiklar och komplexa dokument.
- Prestanda nära GPT-4: Den här modellen uppnår nästan GPT-4-prestanda i flera språkuppgifter och visar upp omfattande språkbehandlingsförmåga på hög nivå.
Användning och applikationer
StepStar tillhandahåller en öppen plattform för företag och utvecklare att ansöka om tillgång till steg-2-16k modell.
Användare kan integrera modellen i applikationer eller utvecklingsprojekt genom API-anrop, med hjälp av plattformsförsedd dokumentation och utvecklingsverktyg för att implementera olika bearbetningsfunktioner för naturligt språk.
DeepSeek-V2.5 av deepseek
Sammanfattning Introduktion
DeepSeek-V2.5, utvecklad av DeepSeek-teamet, är en kraftfull språkmodell med öppen källkod som integrerar funktionerna i DeepSeek-V2-Chat och DeepSeek-Coder-V2-Instruct, vilket representerar kulmen på tidigare modellframsteg. Viktiga detaljer är följande:
- Utvecklingshistoria: I september 2024 släppte de officiellt DeepSeek-V2.5, som kombinerar chatt- och kodningsmöjligheter. Denna version förbättrar både allmänna språkkunskaper och kodningsfunktioner.
- Open Source Nature: I linje med ett engagemang för utveckling med öppen källkod är DeepSeek-V2.5 nu tillgänglig på Hugging Face, vilket gör att utvecklare kan justera och optimera modellen efter behov.

Nyckelfunktioner och fördelar
- Kombinerade språk- och kodningsförmåga: DeepSeek-V2.5 behåller konversationsförmågan hos en chattmodell och kodningsstyrkorna hos en kodarmodell, vilket gör den till en verklig "allt-i-ett"-lösning som kan hantera vardagliga konversationer, komplexa instruktionsföljande, kodgenerering och komplettering.
- Human Preference Alignment: Modellen är finjusterad för att anpassas till mänskliga preferenser och har optimerats för skrivkvalitet och instruktionsefterlevnad, och presterar mer naturligt och intelligent över flera uppgifter för att bättre förstå och möta användarnas behov.
- Enastående prestanda: DeepSeek-V2.5 överträffar tidigare versioner på olika riktmärken, och uppnår toppresultat i kodningsriktmärken som humant python och live code bench, vilket visar sin styrka i instruktionsefterlevnad och kodgenerering.
- Utökat kontextstöd: Med en maximal kontextlängd på 128 000 tokens, hanterar DeepSeek-V2.5 effektivt långa texter och dialoger med flera svängar.
- Hög kostnadseffektivitet: Jämfört med toppklassiga modeller med sluten källkod som Claude 3.5 sonett och GPT-4o, DeepSeek-V2.5 ger en betydande kostnadsfördel.
Användningsmetoder
- Via webbplattform: Få åtkomst till DeepSeek-V2.5 via webbplattformar som SiliconClouds DeepSeek-V2.5-lekplats.
- Via API: Användare kan skapa ett konto för att få en API-nyckel och sedan integrera DeepSeek-V2.5 i sina system via API:et för sekundär utveckling och applikationer.
- Lokal distribution: Kräver 8 grafikprocessorer på 80 GB vardera, med hjälp av Hugging Face's Transformers för slutledning. Se dokumentation och exempelkod för specifika steg.
- Inom specifika produkter:
- Markör: Denna AI-kodredigerare, baserad på VSCode, tillåter användare att konfigurera DeepSeek-V2.5-modellen, ansluta till SiliconClouds API för kodgenerering på sidan via genvägar, vilket förbättrar kodningseffektiviteten.
- Andra utvecklingsverktyg eller plattformar: Alla utvecklingsverktyg eller plattformar som stöder externa språkmodell-API:er kan teoretiskt integrera DeepSeek-V2.5 genom att erhålla en API-nyckel, vilket möjliggör språkgenerering och kodskrivningsmöjligheter.
Ernie-4.0-turbo-8k-förhandsvisning av Baidu
Sammanfattning Introduktion
Ernie-4.0-turbo-8k-förhandsvisning är en del av Baidus ERNIE 4.0 Turbo-serie, som släpptes officiellt den 28 juni 2024 och öppnades helt för företagskunder den 5 juli 2024.
Nyckelfunktioner och fördelar
- Prestandaförbättring: Som en uppgraderad version av ERNIE 4.0 utökar den här modellen kontextinmatningslängden från 2 000 tokens till 8 000 tokens, vilket gör att den kan hantera större datamängder, läsa fler dokument eller webbadresser och prestera bättre på uppgifter som involverar långa texter.
- Kostnadsminskning: In- och utkostnaderna för ERNIE 4.0-turbo-8k-preview är så låga som 0,03 CNY per 1 000 tokens och 0,06 CNY per 1 000 tokens, en 70%-prissänkning från den allmänna versionen av ERNIE 4.0.
- Teknisk optimering: Förbättrad av turboteknologi, uppnår denna modell dubbla förbättringar i träningshastighet och prestanda, vilket möjliggör snabbare modellträning och användning.
- Bred applikation: På grund av dess prestanda och kostnadsfördelar är modellen allmänt användbar inom områden som intelligent kundservice, virtuella assistenter, utbildning och underhållning, vilket ger en smidig och naturlig konversationsupplevelse. Dess robusta genereringsmöjligheter gör den också mycket lämplig för innehållsskapande och dataanalys.
Användande
ERNIE 4.0-turbo-8k-förhandsvisningen är i första hand tillgänglig för företagskunder, som kan komma åt den via Baidus Qianfan Large Model Platform på Baidu Intelligent Cloud.
Topp 10 AI-modell skapad av kinesiskt företag
| Modell | Framkallare | Nyckelfunktion & Styrka | Hur man använder |
| Hunyuan-stor | Tencent | Öppen källkod, 398 miljarder parametrar | Ladda ner modellen |
| Moonshot (kimi) | Moonshot AI | Lång textbearbetningsförmåga, hög språkförståelse | API, officiell app och verktyg |
| GLM-4-Plus | zhipu.ai | språkförståelse, instruktionsföljande och lång textbearbetning. | API |
| SenseChat 5.5 | SenceTime | Kraftfull omfattande prestanda, exceptionella språkegenskaper | Sensetime-webbplats, API |
| Qwen2.5-72B | Alibaba moln | Kontextlängd stöder upp till 128K, flerspråkigt stöd för över 29 språk | Ladda ner modell, officiella webbplats |
| Doubao-pro | ByteDance | Starka omfattande förmågor, hög kostnadseffektivitet, chatbot, | Daobao App, API |
| 360gpt2-pro | 360 | Förbättrade säkerhetsfunktioner, stark språkgenerering | Lobechat, webbläsare 360AI |
| Steg-2-16k | stegkul | språkmodell med biljoner parametrar, kunskapstäckning för flera domäner, prestanda nära GPT-4 | API |
| DeepSeek-V2.5 | deepseek | Kombinerade språk- och kodningsförmåga, anpassning av mänskliga preferenser | Webbplattform, API, lokal distribution |
| Ernie-4.0-turbo-8k | Baidu | Bred applikation, kostnadsreduktion, | Endast företagskunder |


