
ポートレートビデオ編集の強化
マルチモーダル生成事前分布
従来のポートレート ビデオ編集方法では、3D 効果や時間的一貫性に問題が生じることが多く、レンダリング品質や効率の面でもパフォーマンスが低下します。これらの問題に対処するために、PortraitGen はポートレート ビデオの各フレームを統合された動的 3D ガウス フィールドに昇格させ、フレーム間の構造的および時間的一貫性を確保します。PortraitGen は、マルチモーダル キューを使用して一貫性のある表現力豊かなスタイル設定を可能にする強力なポートレート ビデオ編集方法です。
さらに、PortraitGen は、複雑なスタイル編集を可能にするだけでなく、100 フレーム/秒を超えるレンダリング速度を可能にする新しいニューラル ガウス テクスチャリング メカニズムを考案しました。PortraitGen は、大規模な 2D 生成モデルから抽出された知識によって強化された幅広い入力を組み合わせます。また、表情の類似性ガイダンスと顔認識ポートレート編集モジュールも導入されており、データセットを繰り返し更新するときに発生する可能性のある問題を効果的に軽減します。(記事の下部にリンクがあります)
01 キャプションコンテンツ
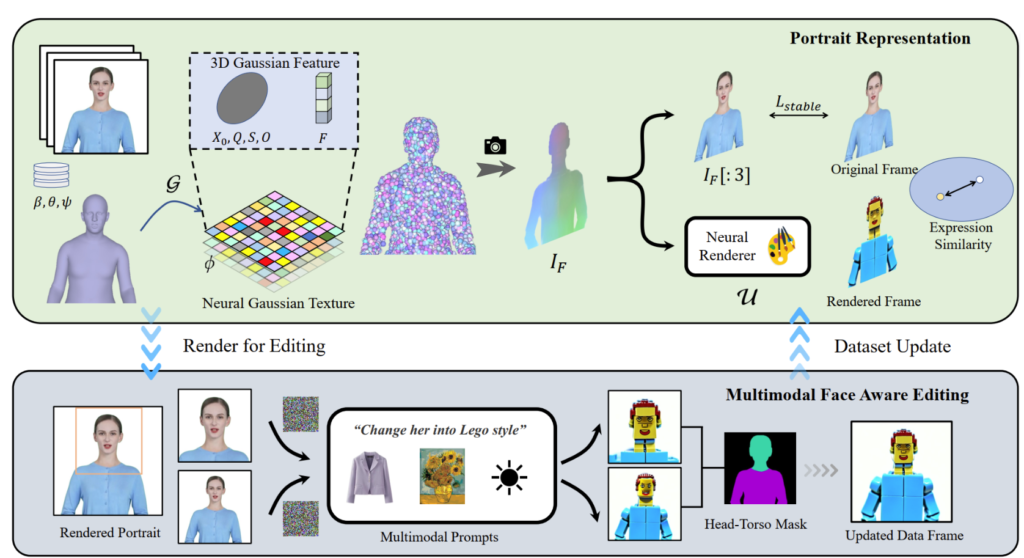
PortraitGen は、2D ポートレート ビデオを 4D ガウス フィールドにリフトし、わずか 30 分でマルチモーダル ポートレート編集を実現します。編集された 3D ポートレートは、100 フレーム/秒でレンダリングできます。最初に単眼ビデオの SMPL-X 係数が追跡され、次にニューロガウス テクスチャ メカニズムを使用して 3D ガウス特徴フィールドが生成されます。
このニューロガウスデータは、肖像画画像をレンダリングするためにさらに処理されます。PortraitGen は、肖像画編集に反復的なデータセット更新戦略も採用し、表情の質を高め、パーソナライズされた顔の構造を維持するための顔認識編集モジュールを提案します。
02 実用例
PortraitGen ソリューションは、ポートレート ビデオ編集用の統合フレームワークです。構造を保持する任意の画像編集モデルを使用して、3D の一貫性があり、時間的に一貫性のあるポートレート ビデオを作成できます。
テキスト駆動編集: InstructPix2Pix は 2D 編集モデルとして使用されます。その UNet には、入力 RGB 画像、テキスト コマンド、およびノイズ潜在の 3 つの入力が必要です。レンダリングされた画像にノイズを追加し、入力ソース画像と指示に基づいて編集します。
画像駆動型編集: 画像の手がかりに基づく 2 種類の編集に焦点を当てます。1 つは参照画像の全体的なスタイルを抽出することであり、もう 1 つは特定の場所にオブジェクトを配置して画像をカスタマイズすることです。これらの方法は、スタイルの移行と仮想フィッティングに実験的に使用されます。参照画像のスタイルは、Neural Style Migration アルゴリズムを使用してデータセット フレームに移行され、AnyDoor を使用して被験者の衣服が変更されました。
再照明: IC-Lightを使用してビデオフレームの照明を操作します。照明条件としてテキストの説明を与えると、PortraitGenメソッドはポートレートビデオの照明を調和的に調整します。
03 コントラストとアブレーション実験
PortraitGen メソッドは、TokenFlow、Rerender A Video、CoDeF、AnyV2V などの最先端のビデオ編集メソッドと比較されます。PortraitGen メソッドは、ジャストインタイムの保存、アイデンティティの保存、時間的一貫性の点で他のメソッドを大幅に上回ります。
時間 00:47
「Delayed Neural Rendering」で提案されたニューラルテクスチャにヒントを得て、PortraitGen はニューラルガウステクスチャを提案しています。このアプローチでは、球面調和係数を保存する代わりに、各ガウスの学習可能な特徴を保存します。次に、2D ニューラルレンダラーを使用して、処理された特徴マップを RGB 信号に変換します。この方法は、球面調和係数よりも豊富な情報を提供し、処理された特徴をより適切に融合できるため、レゴやピクセルアートなどの複雑なスタイルの編集が容易になります。
上半身の画像を編集する場合、顔が占める領域が小さいと、モデルの編集が頭の姿勢や顔の構造にうまく適応しない可能性があります。フェイシャル アウェアネス ポートレート編集 (FA) では、2 つの編集を実行して顔の構造に重点を置くことで、結果を向上させることができます。
レンダリングされた画像と入力ソース画像を EMOCA の潜在表現空間にマッピングし、表現の類似性を最適化することで、表現が自然で元のビデオ フレームと一貫性を保つことができます。
PortraitGenの背後にある技術
参照
PotraitGenの詳細については、こちらをご覧ください:https://ustc3dv.github.io/PortraitGen/
