

什麼是 LLM 模型?
定義與概述
AI 模型是在一組資料上經過訓練的程式,可辨識特定模式或在無需進一步人為干預的情況下做出特定決策。
大型語言模型,也稱為 法學碩士, 是在大量資料上預先訓練好的非常大型的深度學習模型。
底層轉換器是一組神經網路,由具有自我注意能力的編碼器和解碼器組成。編碼器和解碼器可從一連串的文字中抽取意義,並理解其中的單字和短語之間的關係。
哪一款是最適合您的機型?
AI 大型模型的發展非常迅速。不同的公司和研究機構每天都會推出新的研究成果,以及新的大型語言模型。
因此,我們無法明確告訴您哪一款是最好的。
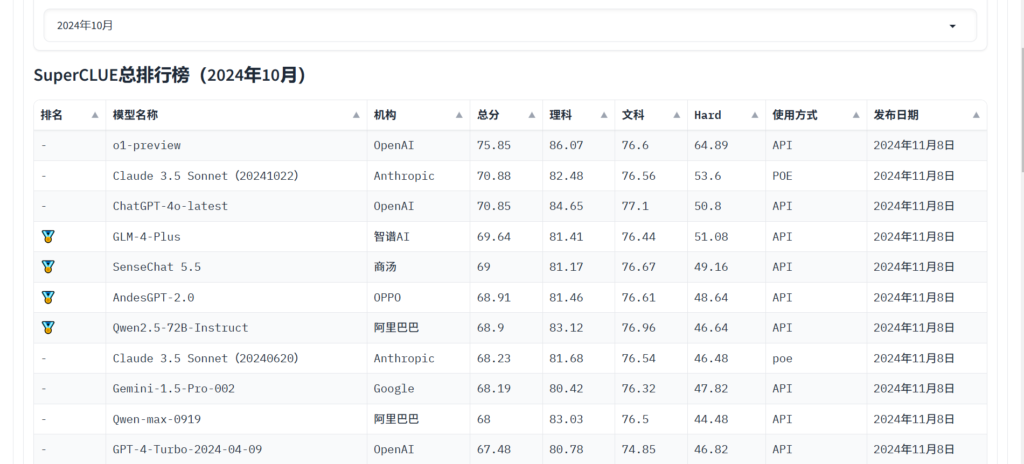
不過,也有頂尖的公司和模型,例如 OpenAI。現在有一套標準和測試題來評估模型。
您可以參考 鬥呎クッ 以檢視模型在各種任務中的得分,並選擇適合您的模型。此外,您也可以追蹤最新消息,進一步瞭解 LLM 模型的能力。
渾源-大圖由騰訊科技提供
機型介紹
在 11 月 5 日 騰訊 釋出開放原始碼 MoE 大型語言模型 Hunyuan-large,共有 398 億個參數,是業界最大的語言模型,擁有 520 億個活化參數。
公開評測結果顯示,騰訊的 「渾元大模 」在各個項目中全面領先。

技術優勢
- 高品質的合成資料:透過合成資料加強訓練、 渾源-大 可以學習到更豐富的表徵、處理長內容輸入,並且對未見過的資料有更好的泛化能力。
- KV 快取壓縮:利用 Grouped Query Attention (GQA) 和 Cross-Layer Attention (CLA) 策略,大幅降低 KV 快取記憶體使用量和計算開銷,提高推理吞吐量。
- 專家特定的學習率調整:為不同的專家設定不同的學習率,以確保每個子模型都能有效地從資料中學習,並對整體效能有所貢獻。
- 長內容處理能力:預訓模型支援高達 256K 的文字序列,而 Instruct 模型則支援高達 128K 的文字序列,大幅提升處理長內容任務的能力。
- 廣泛的基準測試:在各種語言和任務中進行廣泛的實驗,以驗證 "Hunyuan-Large "的實際有效性和安全性。
推論架構與訓練架構
此開放原始碼版本提供兩個專為 渾源-大型號:流行的 vLLM 後端 和 TensorRT-LLM 後端。這兩種解決方案都包含可提升效能的最佳化功能。
Hunyuan-Large 開源模型與 Hugging Face 格式完全相容,讓研究人員和開發人員可以使用 hf-deepspeed 框架執行模型微調。此外,我們還透過使用快閃注意力來支援訓練加速。
如何進一步使用此模型
這是一個開放源碼的模式。您可以在 GitHub,他們提供詳細的說明和使用指南。您可以進一步探索和研究,創造更多可能性。
Moonshot(Kimi) by Moonshot AI
摘要介紹
Moonshot 是 Dark Side of the Moon 開發的大型語言模型。以下是其功能概述:
- 技術突破:Moonshot 在長文字處理方面取得顯著進展,其智慧助理產品 Kimichat 支援多達 200 萬個中文字的無損上下文輸入。
- 模型架構:透過運用創新的網路結構和工程優化,它可以達到長距離的注意力,而不需依賴「捷徑」解決方案,例如滑動視窗、降取樣或較小的模型,這些方案通常會降低效能。因此,即使有數千億個參數,也能全面理解超長文本。
- 應用導向:以實際應用為開發重點,Moonshot 的目標是成為使用者不可或缺的日常工具,並根據真實使用者的回饋而演進,以產生實際價值。

主要功能
- 長文字處理能力:能夠處理廣泛的文字,例如小說或完整的財務報告,為使用者提供深入、全面的洞察力,以及長篇文件的摘要。
- 多模式融合:整合多種模式,結合文字與影像資料,強化分析與產生能力。
- 高語言理解和生成能力:表現出優異的多語言能力,能準確解讀使用者的輸入,並產生高品質、連貫且語義恰當的回覆。
- 彈性擴充能力:提供強大的擴充性,可根據不同的應用程式情境和需求進行客製化和最佳化,為開發人員和企業提供顯著的彈性和自主性。
使用方法
- API 整合:使用者可以在 Dark Side of the Moon 官方平台註冊帳號,申請 API 金鑰,然後使用 API 搭配相容的程式語言,將 Moonshot 的功能整合到自己的應用程式中。
- 使用官方產品和工具:直接使用基於 Moonshot 模型的智慧助理產品 Kimichat,或利用 Dark Side of Moon 提供的相關工具和平台。
- 與其他框架和工具整合:Moonshot 可與流行的 AI 開發框架 (如 LangChain) 整合,以建立更強大的語言模型應用程式。
GLM-4-Plus by zhipu.ai
摘要介紹
由智璞人工智能開發的 GLM-4-Plus 是完全自主開發的 GLM 基礎模型的最新迭代,在語言理解、指令遵循和長文本處理方面有顯著提升。
主要功能與優勢
- 強大的語言理解能力:GLM-4-Plus 以廣泛的資料集和最佳化演算法為訓練基礎,擅長處理複雜的語意,準確詮釋各種文字的意義和上下文。
- 出色的長文本處理:GLM-4-Plus 擁有創新的記憶體機制與分割處理技術,能有效處理長達 128ktoken 的長文本,使其在資料處理與資訊擷取方面有極佳的表現。
- 增強推理能力:結合近端策略最佳化 (PPO),在探索最佳解決方案的同時,維持穩定性和效率,大幅提升模型在數學和程式設計等複雜推理任務中的效能。
- 指令跟蹤準確度高:準確理解並遵守使用者指示,根據使用者需求產生高品質、符合期望的文字。
使用說明
- 註冊帳號並取得 API 金鑰:首先,在 Zhipu 的官網註冊一個帳號,並取得 API 金鑰。
- 檢閱正式文件:有關詳細參數和使用說明,請參閱 GLM-4 系列的正式說明文件。
SenseChat 5.5 by SenceTime
摘要介紹
SenseChat5.5由SenseTime開發,是其大型語言模型的5.5版本,基於InternLM-123b,這是中國最早的大型語言模型之一,建立在數萬億的參數上,並持續更新。

主要功能與優勢
- 強大的綜合效能:在各種評估任務中都名列前茅,在人文和科學的基本能力以及先進的 "Hard "任務中都表現優異。它在人文學科的語言理解和安全性方面表現優異,在科學領域的邏輯和編碼方面也很出色。
- 高效邊緣應用:SenseTime 發佈了 SenseChat Lite-5.5 版本,將初始載入時間縮短至僅 0.19 秒,與 4 月份發佈的 SenseChat Lite-5.0 相比提升了 40%,推理速度達到每秒 90.2 個字元,每台設備的年成本低至 9.9 元。
- 卓越的語言能力:作為一個自然語言應用程式,它能有效地處理大量的文字資料,展現出強大的自然語言對話能力、邏輯推理能力、廣泛的知識以及頻繁的更新。它支援簡體中文、繁體中文、英文和常見的程式語言。
用途與應用產品
- 直接使用:使用者可以在 [SenseTime 網站] 註冊,透過網頁或行動應用程式存取 SenseChat,並與模型互動。
- API 整合:SenseTime 為企業和開發人員提供 API 存取權,讓他們可以將 SenseChat 5.5 整合到他們的產品或應用程式中。
Qwen2.5-72B-阿里雲Qwen團隊指導
模型導入
Qwen2.5 是 Qwen 大型語言模型的最新系列。適用於 Qwen2.5, 該團隊發佈了一些基礎語言模型和指令調諧語言模型,參數範圍從 0.5 到 720 億。
主要功能
- 密集、易於使用、僅限於解碼器的語言模型,可用於 0.5B, 1.5B, 3B, 7B, 14B, 32B以及 72B 尺寸,以及基本和指示變體。
- 在我們最新的大規模資料集上進行預訓,包含高達 18T 代幣。
- 在遵循指令、產生長文本(超過 8K 文字詞組)、理解結構化資料(例如表格)和產生結構化輸出(特別是 JSON)方面有顯著改進。
- 對系統提示的多樣性更有彈性,加強聊天機器人的角色扮演實施和條件設定。
- 上下文長度最多支援 128K 代幣,最多可產生 8K 代幣。
- 多語言支援超過 29 語言,包括中文、英文、法文、西班牙文、葡萄牙文、德文、義大利文、俄文、日文、韓文、越南文、泰文、阿拉伯文等。
如何快速啟動?
您可以在 Github 和抱抱臉上找到使用大型模型的教學。根據這些教學,您可以有效地執行模型,並實現您的功能和想法。
豆寶-pro 由豆寶團隊、ByteDance 提供
摘要介紹
Doubao-pro 是 ByteDance 獨立開發的大型語言模型,於 2024 年 5 月 15 日正式發行。在 Flageval 大型模型評測平台中,Doubao-pro 以 75.96 的高分在閉源模型中排名第二。
- 版本:Doubao-pro 包括具有 4k、32k 和 128k 上下文視窗的版本,每個版本都支援不同的上下文長度以進行推理和微調。
- 績效改善:根據 ByteDance 的內部測試,Doubao-pro-4k 在 11 項業界標準的公開基準中取得 76.8 的總分。
主要功能與優勢
- 強大的綜合能力:Doubao-pro 在數學、知識應用和解決問題等方面的表現優於客觀和主觀評估。
- 廣泛的應用範圍:作為國內應用最廣泛、功能最齊全的機型之一,豆寶的人工智能助手 「豆寶 」在蘋果App Store和各大安卓應用市場的下載量在AIGC應用中排名第一。
- 高成本效益:Doubao-pro-32k 的推理輸入成本僅為每千個 token 0.0008 元。例如,處理 哈利波特 (274 萬字元)的成本僅為 1.5 元。
- 出色的語言理解和生成Doubao-pro 能準確地理解多樣化的自然語言輸入,並產生高品質、連貫且合乎邏輯的回應,滿足使用者在簡單問答、複雜文字創作、專業領域解釋等方面的需求。
- 高效推理速度:透過廣泛的資料訓練與最佳化,豆寶-pro 在推論速度上具有優勢,尤其在處理大量文字或複雜任務時,可提供快速的回應時間並提昇使用者體驗。
使用方法
- 透過火山引擎:透過呼叫模型的 API 來使用 Doubao-pro,代碼範例可在 Volcano Engine 的官方文件中找到。
- 針對特定產品:Doubao-pro 透過 Volcano Engine 提供給企業市場,讓企業可以將它整合到自己的產品或服務中。您也可以透過豆寶應用程式體驗豆寶模式。
360gpt2-pro by 360
摘要介紹
- 型號名稱:360GPT2-Pro是360公司開發的360 Zhibrain大型機型系列的一部分。
- 技術基礎:360利用20年的安全數據、10年的人工智能經驗,以及80位人工智能專家和100位安全專家的專業知識,在200天內使用了5000個GPU資源來訓練和優化Zhibrain模型,360GPT2-Pro是其進階版本之一。

主要功能與優勢
- 強大的語言生成:擅長語言創造任務,尤其是人文科學,能創造高品質、有創意且邏輯連貫的內容,例如故事和文案。
- 強大的知識理解與應用:具備廣泛的知識基礎,能準確地解讀和應用資訊,有效地回答問題和解決問題。
- 基於檢索的增強生成:擅長檢索增強生成,特別是針對中文,使模型能夠生成符合使用者需求和真實世界資料的回應,降低產生幻覺的可能性。
- 增強的安全功能:360GPT2-Pro受益於360長期以來在安全領域的專業技術,提供了一定程度的安全性和可靠性,有效地應對了各種安全風險。
使用方法與相關產品
- 360AI 搜尋:整合 360GPT2-Pro 的搜尋功能,提供使用者更全面深入的搜尋體驗。
- 360AI 瀏覽器:將 360GPT2-Pro 納入 360AI 瀏覽器,使用者可透過特定介面或語音輸入與模型互動,以取得資訊和建議。
Step-2-16k by stepfun
摘要介紹
- 開發人員:StepStar 發佈正式版 STEP-2 萬億個參數的語言模型 在 2024 年,step-2-16k 指的是其支援 16k 上下文視窗的變體。
- 模型架構:建基於創新的 MoE (Mixture of Experts) 架構,可根據任務和資料分佈動態啟動不同的專家模型,同時提升效能和效率。
- 參數刻度:透過數兆個參數,該模型可以捕捉廣泛的語言知識和語義資訊,在各種自然語言處理任務中展示出強大的能力。

主要功能與優勢
- 強大的語言理解和生成能力:準確詮釋輸入的文字,並產生高品質的自然回應,以準確性和價值支援回答問題、內容產生和會話交換等工作。
- 多領域知識覆蓋:該模型在大量資料集上進行訓練,包含數學、邏輯、程式設計、知識和創意寫作等領域的廣泛知識,使其成為跨領域回應和應用的多面手。
- 長序列處理能力:本機型具有 16k 上下文視窗,擅長處理長文字序列,有助於理解和處理長篇文章和複雜文件。
- 性能接近 GPT-4:該模型在多種語言任務中的表現接近 GPT-4,展現了高層次的綜合語言處理能力。
用法與應用
StepStar 提供開放平台,讓企業和開發人員申請存取 Step-2-16K 機型.
使用者可透過 API 呼叫將模型整合至應用程式或開發專案中,使用平台提供的文件和開發工具來實作各種自然語言處理功能。
DeepSeek-V2.5 by deepseek
摘要介紹
DeepSeek-V2.5由 DeepSeek 團隊開發,是一個功能強大的開放原始碼語言模型,整合了 DeepSeek-V2-Chat 和 DeepSeek-Coder-V2-Instruct 的功能,是之前模型進步的結晶。主要細節如下:
- 發展歷史:2024 年 9 月,他們正式推出結合聊天與編碼功能的 DeepSeek-V2.5。這個版本同時增強了一般語言能力和編碼功能。
- 開放原始碼:為了貫徹開放原始碼開發的承諾,DeepSeek-V2.5 現已在 Hugging Face 上提供,讓開發人員可以根據需要調整和優化模型。

主要功能與優勢
- 結合語言與編碼能力DeepSeek-V2.5 保留了聊天模型的會話能力和編碼器模型的編碼優勢,使其成為真正的「多合一」解決方案,能夠處理日常會話、複雜指令跟蹤、代碼生成和完成。
- 人類偏好對齊:根據人類偏好進行微調,模型已針對書寫品質和教學遵循進行最佳化,在多項任務中的表現更自然、更智慧,以更好地瞭解和滿足使用者需求。
- 傑出表現: DeepSeek-V2.5 在各種基準上超越先前的版本,並在 humaneval python 和 live code bench 等編碼基準上取得最佳成績,展現其在指令遵循和代碼產生方面的優勢。
- 延伸情境支援:DeepSeek-V2.5 的最大上下文長度為 128k tokens,可有效處理長篇文本和多回合對話。
- 高成本效益:與頂尖的封閉源碼模式相比,例如 克勞德 3.5 詩篇 和 GPT-4o、DeepSeek-V2.5 提供了顯著的成本優勢。
使用方法
- 透過網路平台:透過網路平台存取 DeepSeek-V2.5,例如 SiliconCloud 的 DeepSeek-V2.5 遊戲場。
- 透過 API:用戶可建立帳號以取得API金鑰,然後透過API將DeepSeek-V2.5整合到自己的系統中,進行二次開發與應用。
- 本地部署:需要 8 個 GPU,每個 80GB,使用 Hugging Face 的 Transformers 進行推理。具體步驟請參閱說明文件和範例程式碼。
- 特定產品內:
- 游標:這個以VSCode為基礎的AI程式碼編輯器,可讓使用者配置DeepSeek-V2.5模型,透過捷徑連接SiliconCloud的API進行頁面程式碼生成,提升編碼效率。
- 其他開發工具或平台:理論上,任何支援外部語言模型 API 的開發工具或平台,都可以透過取得 API 金鑰來整合 DeepSeek-V2.5,啟用語言生成與程式碼撰寫功能。
Ernie-4.0-turbo-8k-preview by Baidu
摘要介紹
Ernie-4.0-turbo-8k-preview 是百度 ERNIE 4.0 Turbo 系列的一部分,於 2024 年 6 月 28 日正式發佈,並於 2024 年 7 月 5 日全面開放給企業客戶。
主要功能與優勢
- 績效改善:作為 ERNIE 4.0 的升級版本,此模型將上下文輸入的長度從 2k tokens 延長到 8k tokens,使其能夠處理更大的資料集、讀取更多的文件或 URL,並在涉及長文本的任務中有更好的表現。
- 降低成本:ERNIE 4.0-turbo-8k-preview 的輸入和輸出成本低至每 1,000 代幣 0.03 元人民幣和每 1,000 代幣 0.06 元人民幣,比一般版本的 ERNIE 4.0 降價 70%。
- 技術優化:藉由渦輪增壓技術的強化,此機型在訓練速度與效能上達到雙重改善,讓模型訓練與部署的速度更快。
- 廣泛應用:由於其性能和成本優勢,該模型可廣泛應用於智能客服、虛擬助理、教育和娛樂等各個領域,提供流暢自然的對話體驗。其強大的生成能力也使其高度適用於內容創作和資料分析。
使用方式
ERNIE 4.0-turbo-8k-preview 主要面向企業客戶,企業客戶可以通過百度智慧雲上的千帆大模型平台進行訪問。
中國公司創造的十大人工智能模型
| 模型 | 開發人員 | 主要特點和優勢 | 如何使用 |
| 渾源-大 | 騰訊 | 開源,3980億個參數 | 下載模型 |
| Moonshot(君) | 登月計畫人工智慧 | 長文本處理能力、高語言理解能力 | API、官方App及工具 |
| GLM-4-Plus | 智撲網 | 語言理解、指令遵循和長文本處理。 | API |
| SenseChat 5.5 | 時間 | 綜合性能強大,語言能力卓越 | 商湯科技網站、API |
| Qwen2.5-72B | 阿里雲 | 上下文長度最大支援128K,支援超過29種語言 | 下載模型,官網 |
| 豆寶 | 位元組跳動 | 綜合能力強,性價比高,聊天機器人, | 淘寶APP,API |
| 360gpt2-pro | 360 | 增強的安全功能,強大的語言生成 | Lobechat、360AI瀏覽器 |
| 步驟-2-16k | 繼子樂趣 | 兆元參數語言模型,多領域知識覆蓋,效能接近GPT-4 | API |
| DeepSeek-V2.5 | 深度搜尋 | 結合語言和編碼能力,符合人類偏好 | Web平台、API、本機部署 |
| 厄尼-4.0-渦輪-8k | 百度 | 廣泛應用,降低成本, | 限企業客戶 |


