
CogView3-chinese text-to-image Model 還不賴
文字到影像產生的最新進展是由擴散模型所推動,但單階段模型在計算效率和影像細節精細度方面面臨挑戰。為了解決這個問題,作者提出了 CogView3,這是一個串聯框架,可先建立低解析度影像,然後應用基於中繼的超解析度來增強文字到影像的擴散。此方法可產生具有競爭力的文字到影像輸出,同時...
文字到影像產生的最新進展是由擴散模型所推動,但單階段模型在計算效率和影像細節精細度方面面臨挑戰。為了解決這個問題,作者提出了 CogView3,這是一個串聯框架,可先建立低解析度影像,然後應用基於中繼的超解析度來增強文字到影像的擴散。此方法可產生具有競爭力的文字到影像輸出,同時...
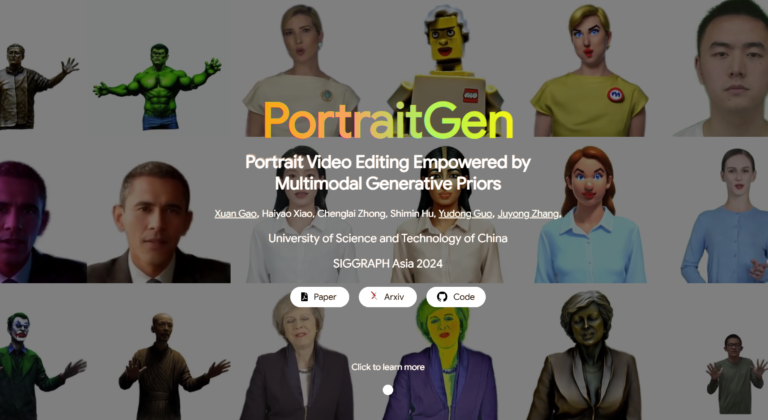
傳統的人像視訊編輯方法常有 3D 效果和時間一致性的問題,而且在渲染品質和效率方面表現不佳。為了解決這些問題,PortraitGen 將人像視訊的每一格提升為統一的動態 3D 高斯場,以確保結構與時間上的一致性。

ByteDance 最新發布 AI 視頻模型 - 再見 Sora,你的時代已經過去。剛才,ByteDance 的 Volcano Engine 發佈會基本上已經結束了,我現在有點興奮過頭了,雖然發佈會結束了,但我覺得,一個顛覆產業的全新開始,在這一刻,正式來臨了。ByteDance 正式發佈了...

統一千千Qwen下載量突破4000萬,「催生 」5萬多個兒童模型。無BS讓首測Qwen在這裡:雲計算 「春晚 」雲栖大會開幕,通益Qwen大模型再次引爆全場!智事9月19日杭州報道,今天,阿里雲推出全球最強大模型開源...

使用 NotebookLLM-Goolge 以自己的方式學習 李笑來曾說過,學習英文最好的方法就是使用英文。NotebookLLM-Goolge可以自己製作播客,自己製作的播客是練習英語聽力的最佳材料之一,可以一邊學習一邊練習聽力。但英文...

線上試用 Flux.1 DEV 由 Flux AI 所產生的免費圖片 FLUX.1 [dev] 介紹 您知道 FLUX.1 [dev] 嗎?由 Black Forest Labs 最新的 AI 奇蹟所創造,是一個 120 億個參數的模型,絕對重新定義了文字到圖片產生的可能性。這個 SOTA 模型不僅是技術上的躍進,也顯示了文字轉圖像的速度有多快。
關鍵要點 功能描述 技術 AI 驅動的影像處理 使用者輸入 上傳模特和服裝的影像 自訂功能 允許選擇服裝和調整設定 輸出品質 高度真實感,但有少許失真 可觸及性 可自由使用 跨性別服裝處理 表現各異,有時不太精確 Kolors 虛擬試穿簡介 現今,虛擬試穿的概念已不再是單純的...
InstantID贏得了第一眼提示:熙熙攘攘的市場充滿了五顏六色的攤位。穿著休閒的服裝,帶有波希米亞風情,卷曲的紅色頭髮用頭巾裝飾,熱鬧的背景是人們和異國情調的商品,拿著一籃子水果。