

Hva er LLM-modell?
Definisjon og oversikt
En AI-modell er et program som har blitt trent på et sett med data for å gjenkjenne bestemte mønstre eller ta bestemte avgjørelser uten ytterligere menneskelig innblanding.
Store språkmodeller, også kjent som LLM-er, er veldig store dyplæringsmodeller som er forhåndstrent på enorme mengder data.
Den underliggende transformatoren er et sett med nevrale nettverk som består av en koder og en dekoder med selvoppmerksomhet. Koderen og dekoderen trekker ut betydninger fra en tekstsekvens og forstår relasjonene mellom ord og uttrykk i den.
Hvilken er den beste modellen for deg?
Store AI-modeller utvikler seg veldig raskt. Ulike bedrifter og forskningsinstitusjoner presenterer daglig nye forskningsresultater, sammen med nye store språkmodeller.
Derfor kan vi ikke definitivt fortelle deg hvilken som er best.
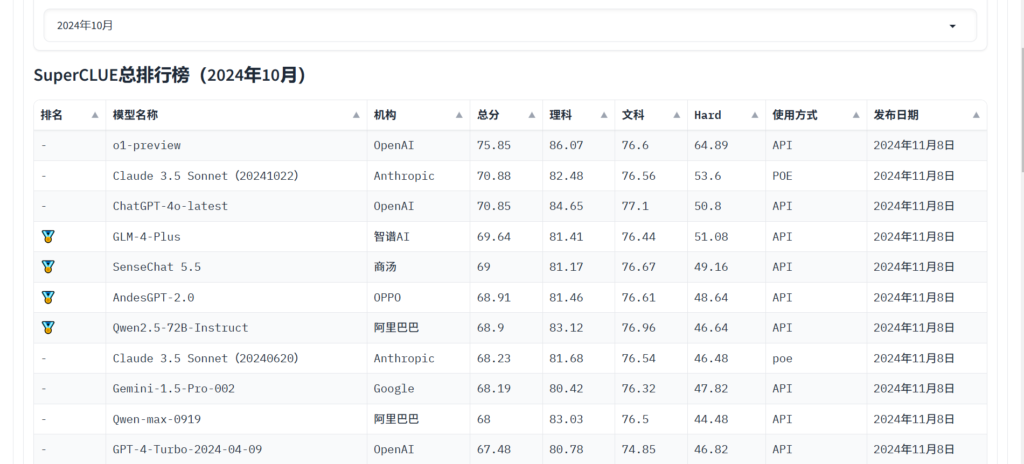
Det er imidlertid topp-tier selskaper og modeller, for eksempel OpenAI. Det er nå et sett med standarder og testspørsmål for å evaluere modeller.
Du kan henvise til superclueai for å se modellens score i ulike oppgaver og velge den som passer deg. Du kan også følge de siste nyhetene for å vite mer om evnen til LLM-modellen.
Hunyuan-Large av Tencent
Modellintroduksjon
Den 5. november, Tencent lanserer åpen kildekode MoE Large Language Model Hunyuan-stor med totalt 398 milliarder parametere, noe som gjør den til den største i bransjen, med 52 milliarder aktiveringsparametere.
Offentlige evalueringsresultater viser at Tencents Hunyuan Large-modell leder omfattende i ulike prosjekter.

Tekniske fordeler
- Syntetiske data av høy kvalitet: Ved å forbedre treningen med syntetiske data, Hunyuan-Large kan lære rikere representasjoner, håndtere inndata med lang kontekst og generalisere bedre til usynlige data.
- KV Cache-komprimering: Bruker strategier for Grouped Query Attention (GQA) og Cross-Layer Attention (CLA) for å redusere minnebruk og beregningsmessige overhead for KV-cacher betydelig, og forbedre inferensgjennomstrømming.
- Ekspertspesifikk læringshastighetskalering: Angir ulike læringsrater for ulike eksperter for å sikre at hver undermodell effektivt lærer av dataene og bidrar til den generelle ytelsen.
- Langkontekstbehandlingsevne: Den forhåndstrente modellen støtter tekstsekvenser opp til 256K, og Instruct-modellen støtter opptil 128K, noe som forbedrer evnen til å håndtere langkontekstoppgaver betydelig.
- Omfattende benchmarking: Gjennomfører omfattende eksperimenter på tvers av ulike språk og oppgaver for å validere den praktiske effektiviteten og sikkerheten til Hunyuan-Large.
Inferensramme og opplæringsramme
Denne åpen kildekode-utgivelsen tilbyr to slutningsalternativer skreddersydd for Hunyuan-Large modell: den populære vLLM-backend og den TensorRT-LLM Backend. Begge løsningene inkluderer optimaliseringer for forbedret ytelse.
Hunyuan-Large åpen kildekode-modellen er fullt kompatibel med Hugging Face-formatet, noe som gjør det mulig for forskere og utviklere å utføre modellfinjustering ved hjelp av hf-deepspeed-rammeverket. I tillegg støtter vi treningsakselerasjon gjennom bruk av blitsoppmerksomhet.
Hvordan bruke denne modellen videre
Dette er en åpen kildekode-modell. Du kan finne "tencent-hunyuan" på GitHub, der de gir detaljerte instruksjoner og bruksveiledninger. Du kan utforske og undersøke det videre for å skape flere muligheter.
Måneskudd(Kimi) av Moonshot AI
Sammendrag Introduksjon
Moonshot er en storstilt språkmodell utviklet av Dark Side of the Moon. Her er en oversikt over funksjonene:
- Teknologisk gjennombrudd: Moonshot oppnår bemerkelsesverdige fremskritt innen lang tekstbehandling, med sitt smarte assistentprodukt, Kimichat, som støtter opptil 2 millioner kinesiske tegn i tapsfri kontekstinntasting.
- Modellarkitektur: Ved å bruke en innovativ nettverksstruktur og tekniske optimaliseringer, oppnår den langsiktig oppmerksomhet uten å stole på "snarveis"-løsninger som skyvevinduer, nedsampling eller mindre modeller som ofte forringer ytelsen. Dette muliggjør omfattende forståelse av ultralange tekster selv med hundrevis av milliarder av parametere.
- Applikasjonsorientert: Moonshot er utviklet med fokus på praktisk anvendelse, og har som mål å bli et uunnværlig daglig verktøy for brukere, som utvikler seg basert på reell tilbakemelding fra brukere for å generere konkret verdi.

Nøkkelfunksjoner
- Lang tekstbehandlingsevne: Kan håndtere omfattende tekster som romaner eller komplette økonomiske rapporter, og tilbyr brukerne dybdegående, omfattende innsikt og sammendrag av lange dokumenter.
- Multimodal fusjon: Integrerer flere modaliteter, og kombinerer tekst med bildedata for å forbedre analyse- og genereringsmuligheter.
- Høy språkforståelse og generasjonsevne: Demonstrerer utmerket flerspråklig ytelse, tolker brukerinndata nøyaktig og genererer høykvalitets, sammenhengende og semantisk passende svar.
- Fleksibel skalerbarhet: Tilbyr sterk skalerbarhet, som tillater tilpasning og optimalisering basert på ulike applikasjonsscenarier og behov, og gir utviklere og bedrifter betydelig fleksibilitet og autonomi.
Bruksmetoder
- API-integrasjon: Brukere kan registrere seg for en konto på den offisielle Dark Side of the Moon-plattformen, søke om en API-nøkkel og deretter integrere Moonshots muligheter i applikasjonene sine ved å bruke API med kompatible programmeringsspråk.
- Bruk av offisielle produkter og verktøy: Bruk Kimichat direkte, det smarte assistentproduktet basert på Moonshot-modellen, eller bruk tilknyttede verktøy og plattformer som tilbys av Dark Side of the Moon.
- Integrasjon med andre rammer og verktøy: Moonshot kan integreres med populære AI-utviklingsrammeverk som LangChain for å bygge mer robuste språkmodellapplikasjoner.
GLM-4-Plus av zhipu.ai
Sammendrag Introduksjon
GLM-4-Plus, utviklet av Zhipu AI, er den siste iterasjonen av den fullt egenutviklede GLM-grunnmodellen, med betydelige forbedringer i språkforståelse, instruksjonsfølging og lang tekstbehandling.
Nøkkelfunksjoner og fordeler
- Sterk språkforståelse: Opplært på omfattende datasett og optimaliserte algoritmer, GLM-4-Plus utmerker seg ved å håndtere kompleks semantikk, og tolke betydningen og konteksten til ulike tekster nøyaktig.
- Enestående langtekstbehandling: Med en innovativ minnemekanisme og segmentert prosesseringsteknikk kan GLM-4-Plus effektivt håndtere lange tekster på opptil 128k tokens, noe som gjør den svært dyktig i databehandling og informasjonsutvinning.
- Forbedrede resonneringsevner: Inkorporerer proksimal policyoptimalisering (PPO) for å opprettholde stabilitet og effektivitet mens du utforsker optimale løsninger, noe som forbedrer modellens ytelse betydelig i komplekse resonneringsoppgaver som matematikk og programmering.
- Høy instruksjonsfølgende nøyaktighet: Forstår og følger brukerinstruksjonene nøyaktig, og genererer høykvalitets, forventningsjustert tekst basert på brukerkrav.
Bruksanvisning
- Registrer en konto og få en API-nøkkel: Først registrerer du en konto på Zhipus offisielle nettsted og skaffer deg en API-nøkkel.
- Gjennomgå offisiell dokumentasjon: Se den offisielle GLM-4-seriens dokumentasjon for detaljerte parametere og bruksinstruksjoner.
SenseChat 5.5 av SenceTime
Sammendrag Introduksjon
SenseChat 5.5, utviklet av SenseTime, er 5.5-versjonen av dens store språkmodell, basert på InternLM-123b, en av Kinas tidligste store språkmodeller bygget på billioner av parametere og kontinuerlig oppdatert.

Nøkkelfunksjoner og fordeler
- Kraftig omfattende ytelse: Rangerer konsekvent blant toppsjiktet i en rekke evalueringsoppgaver, og utmerker seg på tvers av grunnleggende kompetanse innen humaniora og vitenskaper samt avanserte "harde" oppgaver. Den demonstrerer overlegen ytelse i språkforståelse og sikkerhet innen humaniora, og utmerker seg i logikk og koding i naturvitenskap.
- Effektive Edge-applikasjoner: SenseTime har sluppet SenseChat Lite-5.5-versjonen, som reduserer den første lastetiden til bare 0,19 sekunder, en 40%-forbedring i forhold til SenseChat Lite-5.0 utgitt i april, med slutningshastighet på 90,2 tegn per sekund og en årlig kostnad per enhet så lav som 9,9 yuan.
- Eksepsjonelle språkegenskaper: Som en naturlig språkapplikasjon håndterer den effektivt omfattende tekstdata, og demonstrerer robust naturlig språkdialog, logiske resonneringsevner, bred kunnskap og hyppige oppdateringer. Den støtter forenklet kinesisk, tradisjonell kinesisk, engelsk og vanlige programmeringsspråk.
Bruks- og bruksprodukter
- Direkte bruk: Brukere kan registrere seg på [SenseTime-nettstedet] for å få tilgang til SenseChat via nettet eller mobilappen og samhandle med modellen.
- API-integrasjon: SenseTime tilbyr API-tilgang for bedrifter og utviklere, slik at de kan integrere SenseChat 5.5 i sine produkter eller applikasjoner.
Qwen2.5-72B-Instruksjon av Qwen-teamet, Alibaba Cloud
Modellintroduksjon
Qwen2.5 er den nyeste serien av Qwen store språkmodeller. Til Qwen2.5, ga teamet ut en rekke basisspråkmodeller og instruksjonstilpassede språkmodeller fra 0,5 til 72 milliarder parametere.
Nøkkelfunksjoner
- Tette, brukervennlige språkmodeller som kun er dekoder, tilgjengelig i 0,5B, 1,5B, 3B, 7B, 14B, 32B, og 72B størrelser, og base- og instruksvarianter.
- Forhåndsutdannet på vårt nyeste store datasett, som omfatter opptil 18T tokens.
- Betydelige forbedringer i instruksjonsfølging, generering av lange tekster (over 8K-tokens), forståelse av strukturerte data (f.eks. tabeller) og generering av strukturerte utdata, spesielt JSON.
- Mer motstandsdyktig mot mangfoldet av systemforespørsler, forbedrer implementering av rollespill og betingelsessetting for chatbots.
- Kontekstlengde støtter opp til 128K tokens og kan generere opptil 8K tokens.
- Flerspråklig støtte for over 29 språk, inkludert kinesisk, engelsk, fransk, spansk, portugisisk, tysk, italiensk, russisk, japansk, koreansk, vietnamesisk, thai, arabisk og mer.
Hvordan starte raskt?
Du kan finne veiledninger for bruk av store modeller på Github og Hugging face. Basert på disse veiledningene kan du effektivt kjøre modellen og realisere funksjonene og ideene dine.
Doubao-pro av Doubao Team, ByteDance
Sammendrag Introduksjon
Doubao-pro er en stor språkmodell uavhengig utviklet av ByteDance, offisielt utgitt 15. mai 2024. I Flageval-evalueringsplattformen for store modeller ble Doubao-pro rangert som nummer to blant lukkede kildemodeller med en score på 75,96.
- Versjoner: Doubao-pro inkluderer versjoner med 4k, 32k og 128k kontekstvinduer, som hver støtter forskjellige kontekstlengder for inferens og finjustering.
- Ytelsesforbedring: I følge ByteDances interne testing oppnådde Doubao-pro-4k en total poengsum på 76,8 på tvers av 11 industristandard offentlige benchmarks.
Nøkkelfunksjoner og fordeler
- Sterke omfattende evner: Doubao-pro utmerker seg i matematikk, kunnskapsapplikasjon og problemløsning på tvers av objektive og subjektive evalueringer.
- Bredt spekter av applikasjoner: Som en av de mest brukte og allsidige innenlandsmodellene, rangerer Doubaos AI-assistent, "Doubao," først i nedlastinger blant AIGC-applikasjoner på Apple App Store og store Android-appmarkeder.
- Høy kostnadseffektivitet: Doubao-pro-32k sin slutningskostnad er bare 0,0008 yuan per tusen tokens. For eksempel å behandle den kinesiske versjonen av Harry Potter (2,74 millioner tegn) koster bare 1,5 yuan.
- Fremragende språkforståelse og generering: Doubao-pro forstår nøyaktig forskjellige naturlige språkinndata og genererer høykvalitets, sammenhengende og logiske svar, og møter brukerbehov i enkle spørsmål og svar, kompleks tekstoppretting og forklaringer innen spesialiserte felt.
- Effektiv inferenshastighet: Med omfattende dataopplæring og -optimalisering tilbyr Doubao-pro en fordel med inferenshastighet, noe som gir raske responstider og forbedret brukeropplevelse, spesielt når du håndterer store mengder tekst eller komplekse oppgaver.
Bruksmetoder
- Gjennom Volcano Engine: Bruk Doubao-pro ved å ringe modellens API, med kodeeksempler tilgjengelig i Volcano Engines offisielle dokumentasjon.
- For spesifikke produkter: Doubao-pro er tilgjengelig for bedriftsmarkedet gjennom Volcano Engine, slik at bedrifter kan integrere den i sine produkter eller tjenester. Du kan også oppleve Doubao-modellen gjennom Doubao-appen.
360gpt2-pro med 360
Sammendrag Introduksjon
- Modellnavn: 360GPT2-Pro er en del av 360 Zhibrain store modellserie utviklet av 360.
- Teknisk grunnlag: Ved å utnytte 20 års sikkerhetsdata, 10 års AI-erfaring og ekspertisen til 80 AI og 100 sikkerhetseksperter, brukte 360 5000 GPU-ressurser over 200 dager for å trene og optimalisere Zhibrain-modellen, med 360GPT2-Pro som en av de avanserte versjonene.

Nøkkelfunksjoner og fordeler
- Sterk språkgenerering: Utmerker seg i språkgenereringsoppgaver, spesielt innen humaniora, ved å skape høykvalitets, kreativt og logisk sammenhengende innhold, som historier og tekstforfatting.
- Robust kunnskapsforståelse og anvendelse: Utstyrt med en bred kunnskapsbase, tolker og anvender den informasjon nøyaktig for å svare på spørsmål og løse problemer effektivt.
- Forbedret gjenfinningsbasert generasjon: Kompetent i gjenvinningsutvidet generasjon, spesielt for kinesisk, noe som gjør at modellen kan generere svar som er tilpasset brukerbehov og virkelige data, noe som reduserer hallusinasjonssannsynligheten.
- Forbedrede sikkerhetsfunksjoner: Ved å dra nytte av 360s langvarige ekspertise innen sikkerhet, gir 360GPT2-Pro et nivå av sikkerhet og pålitelighet, og effektivt adresserer ulike sikkerhetsrisikoer.
Bruksmetoder og relaterte produkter
- 360AI-søk: Integrerer 360GPT2-Pro med søkefunksjonalitet for å gi brukerne en mer omfattende og dyptgående søkeopplevelse.
- 360AI nettleser: Inkorporerer 360GPT2-Pro i 360AI-nettleseren, slik at brukere kan samhandle med modellen via spesifikke grensesnitt eller gjennom stemmeinndata for å få informasjon og forslag.
Step-2-16k av stepfun
Sammendrag Introduksjon
- Utvikler: StepStar ga ut den offisielle versjonen av TRINN-2 billioner-parameter språkmodell i 2024, med trinn-2-16k som refererer til varianten som støtter et 16k kontekstvindu.
- Modellarkitektur: Bygget på en innovativ MoE (Mixture of Experts)-arkitektur, som dynamisk aktiverer ulike ekspertmodeller basert på oppgaver og datadistribusjon, og forbedrer både ytelse og effektivitet.
- Parameterskala: Med en billion parametere fanger modellen opp omfattende språkkunnskap og semantisk informasjon, og viser kraftige funksjoner på tvers av ulike naturlige språkbehandlingsoppgaver.

Nøkkelfunksjoner og fordeler
- Kraftig språkforståelse og generering: Tolker inndatatekst nøyaktig og genererer naturlige svar av høy kvalitet, støtteoppgaver som å svare på spørsmål, innholdsgenerering og samtaleutveksling med nøyaktighet og verdi.
- Multi-domene kunnskapsdekning: Modellen er trent på massive datasett og omfatter bred kunnskap innen områder som matematikk, logikk, programmering, kunnskap og kreativ skriving, noe som gjør den allsidig for svar og applikasjoner på tvers av domener.
- Lang sekvensbehandlingsevne: Med et 16k kontekstvindu utmerker modellen seg ved å håndtere lange tekstsekvenser, noe som gjør det lettere å forstå og behandle lange artikler og komplekse dokumenter.
- Ytelse nær GPT-4: Denne modellen oppnår nesten GPT-4-ytelse i flere språkoppgaver, og viser omfattende språkbehandlingsevner på høyt nivå.
Bruk og applikasjoner
StepStar tilbyr en åpen plattform for bedrifter og utviklere å søke om tilgang til trinn-2-16k modell.
Brukere kan integrere modellen i applikasjoner eller utviklingsprosjekter gjennom API-kall, ved å bruke plattform-tilveiebrakt dokumentasjon og utviklingsverktøy for å implementere ulike naturlig språkbehandlingsfunksjoner.
DeepSeek-V2.5 av deepseek
Sammendrag Introduksjon
DeepSeek-V2.5, utviklet av DeepSeek-teamet, er en kraftig åpen kildekode-språkmodell som integrerer egenskapene til DeepSeek-V2-Chat og DeepSeek-Coder-V2-Instruct, som representerer kulminasjonen av tidligere modellfremskritt. Nøkkeldetaljer er som følger:
- Utviklingshistorie: I september 2024 ga de offisielt ut DeepSeek-V2.5, som kombinerer chat- og kodefunksjoner. Denne versjonen forbedrer både generelle språkkunnskaper og kodefunksjonalitet.
- Open Source Nature: I tråd med en forpliktelse til åpen kildekode-utvikling, er DeepSeek-V2.5 nå tilgjengelig på Hugging Face, slik at utviklere kan justere og optimalisere modellen etter behov.

Nøkkelfunksjoner og fordeler
- Kombinerte språk- og kodingsevner: DeepSeek-V2.5 beholder samtaleevnene til en chat-modell og kodingsstyrken til en kodemodell, noe som gjør den til en ekte "alt-i-ett"-løsning som kan håndtere hverdagslige samtaler, kompleks instruksjonsfølging, kodegenerering og fullføring.
- Human Preference Alignment: Modellen er finjustert for å samsvare med menneskelige preferanser, og har blitt optimalisert for skrivekvalitet og instruksjonsoverholdelse, og utfører mer naturlig og intelligent på tvers av flere oppgaver for å bedre forstå og møte brukerbehov.
- Enestående ytelse: DeepSeek-V2.5 overgår tidligere versjoner på forskjellige benchmarks, og oppnår toppresultater i koding av benchmarks som humaneval python og live code bench, og viser styrken i instruksjonsoverholdelse og kodegenerering.
- Utvidet kontekststøtte: Med en maksimal kontekstlengde på 128 000 tokens, håndterer DeepSeek-V2.5 effektivt langformede tekster og dialoger med flere svinger.
- Høy kostnadseffektivitet: Sammenlignet med topplags lukkede kildemodeller som Claude 3.5 sonett og GPT-4o, DeepSeek-V2.5 gir en betydelig kostnadsfordel.
Bruksmetoder
- Via nettplattform: Få tilgang til DeepSeek-V2.5 gjennom nettplattformer som SiliconClouds DeepSeek-V2.5-lekeplass.
- Via API: Brukere kan opprette en konto for å få en API-nøkkel, og deretter integrere DeepSeek-V2.5 i systemene sine gjennom API for sekundær utvikling og applikasjoner.
- Lokal distribusjon: Krever 8 GPUer på 80 GB hver, og bruker Hugging Face's Transformers for slutninger. Se dokumentasjon og eksempelkode for spesifikke trinn.
- Innen spesifikke produkter:
- Markør: Denne AI-kodeeditoren, basert på VSCode, lar brukere konfigurere DeepSeek-V2.5-modellen, koble til SiliconClouds API for generering av kode på siden via snarveier, noe som forbedrer kodingseffektiviteten.
- Andre utviklingsverktøy eller plattformer: Ethvert utviklingsverktøy eller plattform som støtter eksterne språkmodell-APIer, kan teoretisk integrere DeepSeek-V2.5 ved å skaffe en API-nøkkel, som muliggjør språkgenerering og kodeskriving.
Ernie-4.0-turbo-8k-forhåndsvisning av Baidu
Sammendrag Introduksjon
Ernie-4.0-turbo-8k-forhåndsvisning er en del av Baidus ERNIE 4.0 Turbo-serie, offisielt utgitt 28. juni 2024, og åpnet fullt ut for bedriftskunder 5. juli 2024.
Nøkkelfunksjoner og fordeler
- Ytelsesforbedring: Som en oppgradert versjon av ERNIE 4.0, utvider denne modellen kontekstinndatalengden fra 2k tokens til 8k tokens, noe som gjør den i stand til å håndtere større datasett, lese flere dokumenter eller URL-er og yte bedre på oppgaver som involverer lange tekster.
- Kostnadsreduksjon: Inngangs- og utgangskostnadene til ERNIE 4.0-turbo-8k-preview er så lave som 0,03 CNY per 1000 tokens og 0,06 CNY per 1000 tokens, en 70%-prisreduksjon fra den generelle versjonen av ERNIE 4.0.
- Teknisk optimalisering: Forbedret av turboteknologi, oppnår denne modellen doble forbedringer i treningshastighet og ytelse, noe som muliggjør raskere modelltrening og utplassering.
- Bred applikasjon: På grunn av ytelsen og kostnadsfordelene er modellen allment anvendelig på tvers av felt som intelligent kundeservice, virtuelle assistenter, utdanning og underholdning, og gir en jevn og naturlig samtaleopplevelse. Dens robuste generasjonsevner gjør den også svært egnet for innholdsskaping og dataanalyse.
Bruk
ERNIE 4.0-turbo-8k-forhåndsvisningen er først og fremst tilgjengelig for bedriftskunder, som kan få tilgang til den via Baidus Qianfan Large Model Platform på Baidu Intelligent Cloud.
Topp 10 AI-modeller laget av Chinese Company
| Modell | Utvikler | Nøkkelfunksjon &Styrke | Hvordan bruke |
| Hunyuan-Large | Tencent | Åpen kildekode, 398 milliarder parametere | Last ned modellen |
| Moonshot (kimi) | Moonshot AI | Lang tekstbehandlingsevne, høy språkforståelse | API, offisiell app og verktøy |
| GLM-4-Plus | zhipu.ai | språkforståelse, instruksjonsfølging og lang tekstbehandling. | API |
| SenseChat 5.5 | Sensetid | Kraftig omfattende ytelse, eksepsjonelle språkegenskaper | Sensetime-nettsted, API |
| Qwen2.5-72B | Alibaba Cloud | Kontekstlengde støtter opptil 128K, flerspråklig støtte for over 29 språk | Last ned modell offisiell nettside |
| Doubao-pro | ByteDance | Sterke omfattende evner, høy kostnadseffektivitet, chatbot, | Daobao App, API |
| 360gpt2-pro | 360 | Forbedrede sikkerhetsfunksjoner, sterk språkgenerering | Lobechat, 360AI nettleser |
| Trinn-2-16k | stepmoro | språkmodell med trillioner parametere, Kunnskapsdekning med flere domener, Ytelse nær GPT-4 | API |
| DeepSeek-V2.5 | deepseek | Kombinerte språk- og kodingsevner, menneskelig preferansejustering | Nettplattform, API, lokal distribusjon |
| Ernie-4.0-turbo-8k | Baidu | Bred applikasjon, kostnadsreduksjon, | Kun bedriftskunder |


