

Qu'est-ce que le modèle LLM ?
Définition et aperçu
Un modèle d’IA est un programme qui a été formé sur un ensemble de données pour reconnaître certains modèles ou prendre certaines décisions sans autre intervention humaine.
Grands modèles de langage, également appelés Masters de LLM, sont de très grands modèles d’apprentissage profond qui sont pré-entraînés sur de vastes quantités de données.
Le transformateur sous-jacent est un ensemble de réseaux neuronaux constitués d'un encodeur et d'un décodeur dotés de capacités d'auto-attention. L'encodeur et le décodeur extraient le sens d'une séquence de texte et comprennent les relations entre les mots et les phrases qu'elle contient.
Quel est le meilleur modèle pour vous ?
Les grands modèles d'IA se développent très rapidement. Différentes entreprises et institutions de recherche présentent chaque jour de nouvelles avancées scientifiques, ainsi que de nouveaux grands modèles linguistiques.
Nous ne pouvons donc pas vous dire avec certitude lequel est le meilleur.
Il existe cependant des entreprises et des modèles de premier plan, comme OpenAI. Il existe désormais un ensemble de normes et de questions de test pour évaluer les modèles.
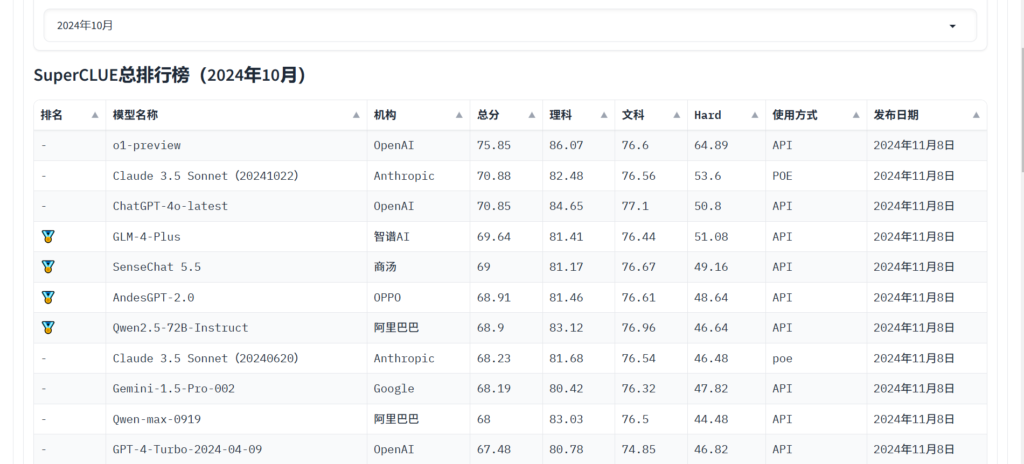
Vous pouvez vous référer à superindice pour visualiser les scores du modèle dans différentes tâches et choisir celle qui vous convient. Vous pouvez également suivre les dernières actualités pour en savoir plus sur les capacités du modèle LLM.
Hunyuan-Large par Tencent
Présentation du modèle
Le 5 novembre, Tencent publie le modèle de langage large MoE Open Source Hunyuan-large avec un total de 398 milliards de paramètres, ce qui en fait le plus grand du secteur, avec 52 milliards de paramètres d'activation.
Les résultats de l'évaluation publique montrent que le modèle Hunyuan Large de Tencent est leader dans de nombreux projets.

Avantages techniques
- Données synthétiques de haute qualité:En améliorant la formation avec des données synthétiques, Hunyuan-Grand peut apprendre des représentations plus riches, gérer des entrées à long contexte et mieux généraliser à des données invisibles.
- Compression du cache KV:Utilise les stratégies d'attention de requête groupée (GQA) et d'attention inter-couches (CLA) pour réduire considérablement l'utilisation de la mémoire et la surcharge de calcul des caches KV, améliorant ainsi le débit d'inférence.
- Mise à l'échelle du taux d'apprentissage spécifique à chaque expert: Définit des taux d'apprentissage différents pour différents experts afin de garantir que chaque sous-modèle apprend efficacement à partir des données et contribue aux performances globales.
- Capacité de traitement à long contexte:Le modèle pré-entraîné prend en charge des séquences de texte jusqu'à 256 Ko, et le modèle Instruct prend en charge jusqu'à 128 Ko, améliorant considérablement la capacité à gérer des tâches à contexte long.
- Analyse comparative approfondie:Mène des expériences approfondies dans différentes langues et tâches pour valider l'efficacité pratique et la sécurité du Hunyuan-Large.
Cadre d'inférence et cadre de formation
Cette version open source propose deux options de backend d'inférence adaptées à Hunyuan-Grand modèle: le populaire backend vLLM et le TensorRT-LLM Backend. Les deux solutions incluent des optimisations pour des performances améliorées.
Le modèle open source Hunyuan-Large est entièrement compatible avec le format Hugging Face, ce qui permet aux chercheurs et aux développeurs d'effectuer des réglages précis du modèle à l'aide du framework hf-deepspeed. De plus, nous prenons en charge l'accélération de la formation grâce à l'utilisation de l'attention flash.
Comment continuer à utiliser ce modèle
Il s'agit d'un modèle open source. Vous pouvez trouver « tencent-hunyuan » sur GitHub, où ils fournissent des instructions détaillées et des guides d'utilisation. Vous pouvez l'explorer et le rechercher davantage pour créer plus de possibilités.
Tir sur la lune (Kimi) par Moonshot AI
Sommaire Introduction
Moonshot est un modèle de langage à grande échelle développé par Dark Side of the Moon. Voici un aperçu de ses fonctionnalités :
- Percée technologique:Moonshot réalise des avancées remarquables dans le traitement de textes longs, avec son produit d'assistant intelligent, Kimichat, prenant en charge jusqu'à 2 millions de caractères chinois en saisie contextuelle sans perte.
- Architecture du modèle:En utilisant une structure de réseau innovante et des optimisations techniques, il permet d'obtenir une attention à longue portée sans avoir recours à des solutions de « raccourci » telles que des fenêtres coulissantes, un sous-échantillonnage ou des modèles plus petits qui dégradent souvent les performances. Cela permet une compréhension complète de textes ultra-longs, même avec des centaines de milliards de paramètres.
- Orienté vers les applications:Développé en mettant l'accent sur l'application pratique, Moonshot vise à devenir un outil quotidien indispensable pour les utilisateurs, évoluant en fonction des retours réels des utilisateurs pour générer une valeur tangible.

Caractéristiques principales
- Capacité de traitement de texte long:Capable de gérer des textes volumineux tels que des romans ou des rapports financiers complets, offrant aux utilisateurs des informations et des résumés approfondis et complets de longs documents.
- Fusion multimodale:Intègre plusieurs modalités, combinant du texte avec des données d'image pour améliorer les capacités d'analyse et de génération.
- Capacité élevée de compréhension et de génération de langage:Démontre d’excellentes performances multilingues, en interprétant avec précision les entrées des utilisateurs et en générant des réponses de haute qualité, cohérentes et sémantiquement appropriées.
- Évolutivité flexible:Offre une forte évolutivité, permettant la personnalisation et l'optimisation en fonction de différents scénarios et besoins d'application, offrant aux développeurs et aux entreprises une flexibilité et une autonomie importantes.
Méthodes d'utilisation
- Intégration API:Les utilisateurs peuvent créer un compte sur la plateforme officielle Dark Side of the Moon, demander une clé API, puis intégrer les capacités de Moonshot dans leurs applications à l'aide de l'API avec des langages de programmation compatibles.
- Utilisation des produits et outils officiels:Utilisez directement Kimichat, le produit d'assistant intelligent basé sur le modèle Moonshot, ou exploitez les outils et plateformes associés proposés par Dark Side of the Moon.
- Intégration avec d'autres frameworks et outils:Moonshot peut être intégré à des frameworks de développement d'IA populaires comme LangChain pour créer des applications de modèles de langage plus robustes.
GLM-4-Plus par zhipu.ai
Sommaire Introduction
GLM-4-Plus, développé par Zhipu AI, est la dernière itération du modèle de base GLM entièrement développé par nos soins, avec des améliorations significatives dans la compréhension du langage, le suivi des instructions et le traitement de textes longs.
Principales caractéristiques et avantages
- Forte compréhension de la langue:Formé sur des ensembles de données étendus et des algorithmes optimisés, GLM-4-Plus excelle dans la gestion d'une sémantique complexe, interprétant avec précision le sens et le contexte de divers textes.
- Traitement exceptionnel de textes longs:Avec un mécanisme de mémoire innovant et une technique de traitement segmentée, GLM-4-Plus peut gérer efficacement des textes longs jusqu'à 128 000 jetons, ce qui le rend très compétent dans le traitement des données et l'extraction d'informations.
- Capacités de raisonnement améliorées:Incorpore l'optimisation des politiques proximales (PPO) pour maintenir la stabilité et l'efficacité tout en explorant des solutions optimales, améliorant considérablement les performances du modèle dans des tâches de raisonnement complexes comme les mathématiques et la programmation.
- Haute précision de suivi des instructions:Comprend et adhère avec précision aux instructions de l'utilisateur, générant un texte de haute qualité, conforme aux attentes, en fonction des besoins de l'utilisateur.
Instructions d'utilisation
- Créez un compte et obtenez une clé API:Tout d'abord, créez un compte sur le site officiel de Zhipu et obtenez une clé API.
- Consulter la documentation officielle:Reportez-vous à la documentation officielle de la série GLM-4 pour obtenir des paramètres détaillés et des instructions d'utilisation.
SenseChat 5.5 de SenceTime
Sommaire Introduction
SenseChat 5.5, développé par SenseTime, est la version 5.5 de son grand modèle linguistique, basé sur l'InternLM-123b, l'un des premiers grands modèles linguistiques de Chine construit sur des milliards de paramètres et continuellement mis à jour.

Principales caractéristiques et avantages
- Performances complètes et puissantes:Se classe régulièrement parmi les meilleurs dans une variété de tâches d'évaluation, excellant dans les compétences fondamentales en sciences humaines et en sciences ainsi que dans les tâches avancées « difficiles ». Il démontre des performances supérieures en compréhension et en sécurité du langage dans les sciences humaines, et excelle en logique et en codage dans les sciences.
- Applications Edge efficaces:SenseTime a publié la version SenseChat Lite-5.5, qui réduit le temps de chargement initial à seulement 0,19 seconde, une amélioration de 40% par rapport à SenseChat Lite-5.0 sorti en avril, avec une vitesse d'inférence atteignant 90,2 caractères par seconde et un coût annuel par appareil aussi bas que 9,9 yuans.
- Des capacités linguistiques exceptionnelles:En tant qu'application en langage naturel, elle gère efficacement de vastes données textuelles, démontrant un dialogue en langage naturel robuste, des capacités de raisonnement logique, de vastes connaissances et des mises à jour fréquentes. Elle prend en charge le chinois simplifié, le chinois traditionnel, l'anglais et les langages de programmation courants.
Utilisation et application des produits
- Utilisation directe:Les utilisateurs peuvent s'inscrire sur le [site Web SenseTime] pour accéder à SenseChat via l'application Web ou mobile et interagir avec le modèle.
- Intégration API:SenseTime offre un accès API aux entreprises et aux développeurs, leur permettant d'intégrer SenseChat 5.5 dans leurs produits ou applications.
Qwen2.5-72B-Instruct par l'équipe Qwen, Alibaba Cloud
Introduction au modèle
Qwen2.5 est la dernière série de grands modèles de langage Qwen. Qwen2.5, l'équipe a publié un certain nombre de modèles de langage de base et de modèles de langage optimisés pour les instructions, allant de 0,5 à 72 milliards de paramètres.
Caractéristiques principales
- Modèles de langage denses, faciles à utiliser et uniquement accessibles par décodeur, disponibles en 0,5 milliard, 1,5 milliard, 3B, 7B, 14B, 32Bet 72B tailles, variantes de base et d'instructions.
- Pré-entraîné sur notre dernier ensemble de données à grande échelle, englobant jusqu'à 18T jetons.
- Améliorations significatives dans le suivi des instructions, la génération de textes longs (plus de 8 000 jetons), la compréhension des données structurées (par exemple, des tableaux) et la génération de sorties structurées, en particulier JSON.
- Plus résilient à la diversité des invites du système, améliorant la mise en œuvre du jeu de rôle et la définition des conditions pour les chatbots.
- La longueur du contexte prend en charge jusqu'à 128 000 jetons et peut générer jusqu'à 8K jetons.
- Support multilingue pour plus de 29 langues, dont le chinois, l'anglais, le français, l'espagnol, le portugais, l'allemand, l'italien, le russe, le japonais, le coréen, le vietnamien, le thaï, l'arabe, et bien d'autres encore.
Comment démarrer rapidement ?
Vous pouvez trouver des tutoriels sur l'utilisation de grands modèles sur Github et Hugging face. Sur la base de ces tutoriels, vous pouvez exécuter efficacement le modèle et concrétiser vos fonctions et vos idées.
Doubao-pro par l'équipe Doubao, ByteDance
Sommaire Introduction
Doubao-pro est un grand modèle de langage développé indépendamment par ByteDance, officiellement publié le 15 mai 2024. Dans la plateforme d'évaluation Flageval pour les grands modèles, Doubao-pro s'est classé deuxième parmi les modèles à source fermée avec un score de 75,96.
- Versions:Doubao-pro inclut des versions avec des fenêtres de contexte de 4 k, 32 k et 128 k, chacune prenant en charge différentes longueurs de contexte pour l'inférence et le réglage fin.
- Amélioration des performances:Selon les tests internes de ByteDance, Doubao-pro-4k a obtenu un score total de 76,8 sur 11 benchmarks publics standard du secteur.
Principales caractéristiques et avantages
- Excellentes capacités globales:Doubao-pro excelle en mathématiques, en application des connaissances et en résolution de problèmes à travers des évaluations objectives et subjectives.
- Large gamme d'applications:En tant que l'un des modèles domestiques les plus utilisés et les plus polyvalents, l'assistant IA de Doubao, « Doubao », se classe au premier rang des téléchargements parmi les applications AIGC sur l'App Store d'Apple et les principaux marchés d'applications Android.
- Rentabilité élevée: Le coût d'entrée d'inférence de Doubao-pro-32k n'est que de 0,0008 yuan par millier de jetons. Par exemple, le traitement de la version chinoise de Harry Potter (2,74 millions de caractères) ne coûte que 1,5 yuan.
- Excellente compréhension et génération de langage:Doubao-pro comprend avec précision diverses entrées en langage naturel et génère des réponses de haute qualité, cohérentes et logiques, répondant aux besoins des utilisateurs en matière de questions-réponses simples, de création de textes complexes et d'explications dans des domaines spécialisés.
- Vitesse d'inférence efficace:Avec une formation et une optimisation approfondies des données, Doubao-pro offre un avantage en termes de vitesse d'inférence, permettant des temps de réponse rapides et une expérience utilisateur améliorée, en particulier lors du traitement de gros volumes de texte ou de tâches complexes.
Méthodes d'utilisation
- Grâce au moteur Volcano:Utilisez Doubao-pro en appelant l'API du modèle, avec des exemples de code disponibles dans la documentation officielle de Volcano Engine.
- Pour des produits spécifiques:Doubao-pro est disponible sur le marché des entreprises via Volcano Engine, ce qui permet aux entreprises de l'intégrer à leurs produits ou services. Vous pouvez également découvrir le modèle Doubao via l'application Doubao.
360gpt2-pro par 360
Sommaire Introduction
- Nom du modèle:360GPT2-Pro fait partie de la série de grands modèles 360 Zhibrain développée par 360.
- Fondements techniques:En s'appuyant sur 20 ans de données de sécurité, 10 ans d'expérience en IA et l'expertise de 80 experts en IA et 100 experts en sécurité, 360 a utilisé 5 000 ressources GPU sur 200 jours pour former et optimiser le modèle Zhibrain, 360GPT2-Pro étant l'une de ses versions avancées.

Principales caractéristiques et avantages
- Génération de langage fort:Excelle dans les tâches de génération de langage, en particulier dans les sciences humaines, en créant du contenu de haute qualité, créatif et logiquement cohérent, comme des histoires et de la rédaction.
- Compréhension et application solides des connaissances:Doté d’une large base de connaissances, il interprète et applique avec précision les informations pour répondre aux questions et résoudre les problèmes efficacement.
- Génération basée sur la récupération améliorée:Compétent en génération augmentée de récupération, en particulier pour le chinois, permettant au modèle de générer des réponses alignées sur les besoins des utilisateurs et les données du monde réel, réduisant ainsi la probabilité d'hallucination.
- Fonctionnalités de sécurité améliorées:Bénéficiant de l'expertise de longue date de 360 en matière de sécurité, 360GPT2-Pro offre un niveau de sécurité et de fiabilité, répondant efficacement à divers risques de sécurité.
Méthodes d'utilisation et produits associés
- Recherche 360AI:Intègre 360GPT2-Pro à la fonctionnalité de recherche pour offrir aux utilisateurs une expérience de recherche plus complète et plus approfondie.
- Navigateur 360AI:Incorpore 360GPT2-Pro dans le navigateur 360AI, permettant aux utilisateurs d'interagir avec le modèle via des interfaces spécifiques ou via une saisie vocale pour obtenir des informations et des suggestions.
Étape 2-16k par stepfun
Sommaire Introduction
- Promoteur:StepStar a publié la version officielle du Modèle de langage STEP-2 à 2 milliards de paramètres en 2024, avec l'étape 2-16k faisant référence à sa variante prenant en charge une fenêtre de contexte de 16 000.
- Architecture du modèle:Construit sur une architecture MoE (Mixture of Experts) innovante, qui active dynamiquement différents modèles d'experts en fonction des tâches et de la distribution des données, améliorant à la fois les performances et l'efficacité.
- Échelle des paramètres:Avec un billion de paramètres, le modèle capture de vastes connaissances linguistiques et des informations sémantiques, affichant de puissantes capacités dans diverses tâches de traitement du langage naturel.

Principales caractéristiques et avantages
- Compréhension et génération de langage puissantes:Interprète avec précision le texte saisi et génère des réponses naturelles de haute qualité, prenant en charge des tâches telles que répondre à des questions, générer du contenu et échanger des conversations avec précision et valeur.
- Couverture des connaissances multi-domaines:Formé sur des ensembles de données massifs, le modèle englobe de vastes connaissances dans des domaines tels que les mathématiques, la logique, la programmation, la connaissance et l'écriture créative, ce qui le rend polyvalent pour les réponses et applications inter-domaines.
- Capacité de traitement de séquences longues:Avec une fenêtre de contexte de 16 000, le modèle excelle dans la gestion de longues séquences de texte, facilitant la compréhension et le traitement d'articles longs et de documents complexes.
- Performances proches de celles du GPT-4:Atteignant des performances proches de celles de GPT-4 dans de multiples tâches linguistiques, ce modèle présente des capacités de traitement linguistique complètes de haut niveau.
Utilisation et applications
StepStar fournit une plate-forme ouverte aux entreprises et aux développeurs pour demander l'accès au modèle étape 2-16k.
Les utilisateurs peuvent intégrer le modèle dans des applications ou des projets de développement via des appels d'API, en utilisant la documentation fournie par la plateforme et les outils de développement pour implémenter diverses fonctionnalités de traitement du langage naturel.
DeepSeek-V2.5 par deepseek
Sommaire Introduction
DeepSeek-V2.5, développé par l'équipe DeepSeek, est un puissant modèle de langage open source qui intègre les capacités de DeepSeek-V2-Chat et de DeepSeek-Coder-V2-Instruct, représentant l'aboutissement des avancées précédentes du modèle. Les principaux détails sont les suivants :
- Historique du développement:En septembre 2024, ils ont officiellement publié DeepSeek-V2.5, combinant des fonctionnalités de chat et de codage. Cette version améliore à la fois la maîtrise générale de la langue et les fonctionnalités de codage.
- Nature Open Source:Conformément à un engagement envers le développement open source, DeepSeek-V2.5 est désormais disponible sur Hugging Face, permettant aux développeurs d'ajuster et d'optimiser le modèle selon les besoins.

Principales caractéristiques et avantages
- Compétences combinées en langage et en codage:DeepSeek-V2.5 conserve les capacités conversationnelles d'un modèle de chat et les atouts de codage d'un modèle de codeur, ce qui en fait une véritable solution « tout-en-un » capable de gérer les conversations quotidiennes, le suivi d'instructions complexes, la génération de code et l'achèvement.
- Alignement des préférences humaines:Ajusté pour s'aligner sur les préférences humaines, le modèle a été optimisé pour la qualité de l'écriture et le respect des instructions, fonctionnant de manière plus naturelle et plus intelligente sur plusieurs tâches pour mieux comprendre et répondre aux besoins des utilisateurs.
- Des performances exceptionnelles: DeepSeek-V2.5 surpasse les versions précédentes sur divers benchmarks et obtient les meilleurs résultats dans les benchmarks de codage comme humaneval python et live code bench, démontrant sa force dans le respect des instructions et la génération de code.
- Prise en charge étendue du contexte:Avec une longueur de contexte maximale de 128 000 jetons, DeepSeek-V2.5 gère efficacement les textes longs et les dialogues à plusieurs tours.
- Rentabilité élevée:Par rapport aux modèles à source fermée de premier plan comme Claude 3.5 Sonnet et GPT-4o, DeepSeek-V2.5 offre un avantage de coût significatif.
Méthodes d'utilisation
- Via la plateforme Web:Accédez à DeepSeek-V2.5 via des plateformes Web telles que le terrain de jeu DeepSeek-V2.5 de SiliconCloud.
- Via API:Les utilisateurs peuvent créer un compte pour obtenir une clé API, puis intégrer DeepSeek-V2.5 dans leurs systèmes via l'API pour le développement secondaire et les applications.
- Déploiement local:Nécessite 8 GPU de 80 Go chacun, utilisant les transformateurs de Hugging Face pour l'inférence. Reportez-vous à la documentation et à l'exemple de code pour connaître les étapes spécifiques.
- Au sein de produits spécifiques:
- Curseur:Cet éditeur de code AI, basé sur VSCode, permet aux utilisateurs de configurer le modèle DeepSeek-V2.5, en se connectant à l'API de SiliconCloud pour la génération de code sur la page via des raccourcis, améliorant ainsi l'efficacité du codage.
- Autres outils ou plateformes de développement:Tout outil ou plateforme de développement prenant en charge les API de modèle de langage externe peut théoriquement intégrer DeepSeek-V2.5 en obtenant une clé API, permettant ainsi des capacités de génération de langage et d'écriture de code.
Aperçu de l'Ernie 4.0 turbo 8k par Baidu
Sommaire Introduction
Aperçu du moteur Ernie 4.0 turbo 8k fait partie de la série ERNIE 4.0 Turbo de Baidu, officiellement lancée le 28 juin 2024 et entièrement ouverte aux clients d'entreprise le 5 juillet 2024.
Principales caractéristiques et avantages
- Amélioration des performances:En tant que version améliorée d'ERNIE 4.0, ce modèle étend la longueur d'entrée de contexte de 2 000 jetons à 8 000 jetons, ce qui lui permet de gérer des ensembles de données plus volumineux, de lire plus de documents ou d'URL et d'obtenir de meilleures performances sur les tâches impliquant de longs textes.
- Réduction des coûts:Les coûts d'entrée et de sortie d'ERNIE 4.0-turbo-8k-preview sont aussi bas que 0,03 CNY pour 1 000 jetons et 0,06 CNY pour 1 000 jetons, soit une réduction de prix de 70% par rapport à la version générale d'ERNIE 4.0.
- Optimisation technique:Amélioré par la technologie turbo, ce modèle réalise une double amélioration de la vitesse d'entraînement et des performances, permettant un entraînement et un déploiement plus rapides du modèle.
- Large application:En raison de ses avantages en termes de performances et de coût, le modèle est largement applicable dans des domaines tels que le service client intelligent, les assistants virtuels, l'éducation et le divertissement, offrant une expérience de conversation fluide et naturelle. Ses solides capacités de génération le rendent également particulièrement adapté à la création de contenu et à l'analyse de données.
Usage
L'aperçu ERNIE 4.0-turbo-8k est principalement disponible pour les clients d'entreprise, qui peuvent y accéder via la plate-forme Qianfan Large Model de Baidu sur Baidu Intelligent Cloud.
Top 10 des modèles d'IA créés par une entreprise chinoise
| Modèle | Promoteur | Caractéristiques principales et force | Comment utiliser |
| Hunyuan-Grand | Tencent | Open source, 398 milliards de paramètres | Télécharger le modèle |
| Tir de lune (kimi) | IA de Moonshot | Capacité de traitement de texte long, compréhension linguistique élevée | API, application officielle et outils |
| GLM-4-Plus | Zhipu.ai | compréhension du langage, suivi des instructions et traitement de textes longs. | API |
| SenseChat 5.5 | SensTime | Des performances complètes et puissantes, des capacités linguistiques exceptionnelles | Site Web Sensetime, API |
| Qwen2.5-72B | Nuage Alibaba | La longueur du contexte prend en charge jusqu'à 128 K, prise en charge multilingue de plus de 29 langues | Télécharger le modèle, site officiel |
| Doubao-pro | ByteDance | Fortes capacités globales, rentabilité élevée, chatbot, | Application Daobao, API |
| 360gpt2-pro | 360 | Fonctionnalités de sécurité améliorées, génération de langage fort | Lobechat, navigateur 360AI |
| Étape 2-16k | pas amusant | Modèle de langage à mille milliards de paramètres, couverture des connaissances multi-domaines, performances proches de GPT-4 | API |
| DeepSeek-V2.5 | recherche profonde | Compétences combinées en langage et en codage, alignement des préférences humaines | Plateforme Web, API, déploiement local |
| Moteur Ernie 4.0 turbo 8 000 tr/min | Baidu | Large application, réduction des coûts, | Uniquement les clients d'entreprise |


