

¿Qué es el modelo LLM?
Definición y descripción general
Un modelo de IA es un programa que ha sido entrenado con un conjunto de datos para reconocer ciertos patrones o tomar ciertas decisiones sin intervención humana adicional.
Modelos de lenguaje grandes, también conocidos como LLM (Máster en Derecho)Son modelos de aprendizaje profundo muy grandes que están entrenados previamente con grandes cantidades de datos.
El transformador subyacente es un conjunto de redes neuronales que consisten en un codificador y un decodificador con capacidades de autoatención. El codificador y el decodificador extraen significados de una secuencia de texto y comprenden las relaciones entre las palabras y frases que contiene.
¿Cual es el mejor modelo para ti?
Los modelos de IA a gran escala se están desarrollando muy rápidamente. Diferentes empresas e instituciones de investigación presentan diariamente nuevos resultados de investigación, junto con nuevos modelos de lenguaje a gran escala.
Por lo tanto, no podemos decirte definitivamente cuál es el mejor.
Sin embargo, existen empresas y modelos de primer nivel, como OpenAI. Actualmente, existe un conjunto de estándares y preguntas de prueba para evaluar los modelos.
Puedes consultar superpista para ver las puntuaciones del modelo en varias tareas y elegir la que más te convenga. Además, puedes seguir las últimas noticias para saber más sobre la capacidad del modelo LLM.
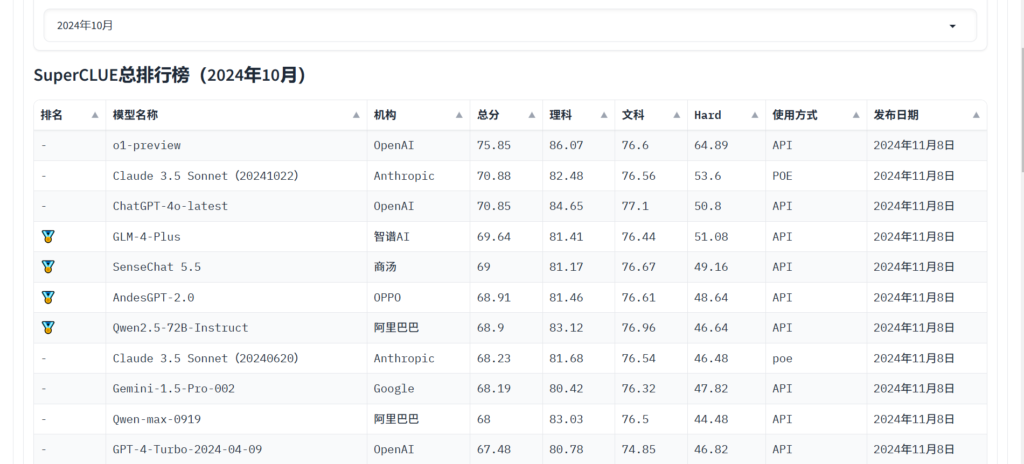
Hunyuan-Grande de Tencent
Introducción del modelo
El 5 de noviembre, Tencent lanza el modelo de lenguaje grande MoE de código abierto Hunyuan-large con un total de 398 mil millones de parámetros, lo que lo convierte en el más grande de la industria, con 52 mil millones de parámetros de activación.
Los resultados de la evaluación pública muestran que el modelo Hunyuan Large de Tencent lidera ampliamente en varios proyectos.

Ventajas técnicas
- Datos sintéticos de alta calidad:Al mejorar el entrenamiento con datos sintéticos, Hunyuan-Grande Puede aprender representaciones más ricas, manejar entradas de contexto largo y generalizar mejor datos no vistos.
- Compresión de caché KV:Utiliza estrategias de atención de consultas agrupadas (GQA) y atención entre capas (CLA) para reducir significativamente el uso de memoria y la sobrecarga computacional de los cachés KV, mejorando el rendimiento de la inferencia.
- Escala de tasa de aprendizaje específica para cada experto:Establece diferentes tasas de aprendizaje para diferentes expertos para garantizar que cada submodelo aprenda eficazmente de los datos y contribuya al rendimiento general.
- Capacidad de procesamiento de contexto largo:El modelo entrenado previamente admite secuencias de texto de hasta 256 K, y el modelo Instruct admite hasta 128 K, lo que mejora significativamente la capacidad de manejar tareas de contexto largo.
- Evaluación comparativa exhaustiva:Realiza experimentos exhaustivos en varios idiomas y tareas para validar la eficacia práctica y la seguridad de Hunyuan-Large.
Marco de inferencia y marco de entrenamiento
Esta versión de código abierto ofrece dos opciones de backend de inferencia diseñadas para Hunyuan-Modelo grande:el popular backend de vLLM y el TensorRT-LLM Backend. Ambas soluciones incluyen optimizaciones para un mejor rendimiento.
El modelo de código abierto Hunyuan-Large es totalmente compatible con el formato Hugging Face, lo que permite a los investigadores y desarrolladores realizar ajustes finos del modelo utilizando el marco hf-deepspeed. Además, admitimos la aceleración del entrenamiento mediante el uso de la atención flash.
Cómo seguir utilizando este modelo
Este es un modelo de código abierto. Puede encontrar “tencent-hunyuan” en GitHub, donde se proporcionan instrucciones detalladas y guías de uso. Puedes explorar e investigar más sobre el tema para crear más posibilidades.
Disparo a la luna(Kimi) por Moonshot AI
Resumen Introducción
Moonshot es un modelo de lenguaje a gran escala desarrollado por Dark Side of the Moon. A continuación, se ofrece una descripción general de sus características:
- Avance tecnológico:Moonshot logra avances notables en el procesamiento de textos largos con su producto asistente inteligente, Kimichat, que admite hasta 2 millones de caracteres chinos en una entrada de contexto sin pérdida.
- Arquitectura del modelo:Al emplear una estructura de red innovadora y optimizaciones de ingeniería, logra una atención de largo alcance sin depender de soluciones de “atajo” como ventanas deslizantes, reducción de resolución o modelos más pequeños que a menudo degradan el rendimiento. Esto permite una comprensión integral de textos ultralargos incluso con cientos de miles de millones de parámetros.
- Orientado a la aplicaciónDesarrollado con un enfoque en la aplicación práctica, Moonshot tiene como objetivo convertirse en una herramienta diaria indispensable para los usuarios, evolucionando en función de los comentarios reales de los usuarios para generar valor tangible.

Características principales
- Capacidad de procesamiento de textos largos:Capaz de manejar textos extensos como novelas o informes financieros completos, ofreciendo a los usuarios información detallada y resúmenes de documentos largos.
- Fusión multimodal:Integra múltiples modalidades, combinando texto con datos de imágenes para mejorar las capacidades de análisis y generación.
- Alta capacidad de comprensión y generación de lenguaje:Demuestra un excelente desempeño multilingüe, interpretando con precisión la entrada del usuario y generando respuestas de alta calidad, coherentes y semánticamente apropiadas.
- Escalabilidad flexible:Ofrece una fuerte escalabilidad, lo que permite la personalización y optimización en función de diferentes escenarios y necesidades de aplicación, proporcionando a los desarrolladores y empresas una flexibilidad y autonomía significativas.
Métodos de uso
- Integración API:Los usuarios pueden registrarse para obtener una cuenta en la plataforma oficial de Dark Side of the Moon, solicitar una clave API y luego integrar las capacidades de Moonshot en sus aplicaciones utilizando la API con lenguajes de programación compatibles.
- Uso de productos y herramientas oficiales:Utilice directamente Kimichat, el producto de asistente inteligente basado en el modelo Moonshot, o aproveche las herramientas y plataformas asociadas que ofrece Dark Side of the Moon.
- Integración con otros marcos y herramientas:Moonshot se puede integrar con marcos de desarrollo de IA populares como LangChain para crear aplicaciones de modelos de lenguaje más sólidas.
GLM-4-Plus de zhipu.ai
Resumen Introducción
GLM-4-Plus, desarrollado por Zhipu AI, es la última iteración del modelo básico GLM totalmente desarrollado por nosotros, con mejoras significativas en la comprensión del lenguaje, el seguimiento de instrucciones y el procesamiento de textos largos.
Principales características y ventajas
- Fuerte comprensión del lenguaje:GLM-4-Plus, entrenado en amplios conjuntos de datos y algoritmos optimizados, se destaca en el manejo de semántica compleja, interpretando con precisión el significado y el contexto de varios textos.
- Excelente procesamiento de textos largos:Con un mecanismo de memoria innovador y una técnica de procesamiento segmentado, GLM-4-Plus puede manejar eficazmente textos largos de hasta 128k tokens, lo que lo hace altamente competente en el procesamiento de datos y la extracción de información.
- Capacidades de razonamiento mejoradas:Incorpora Optimización de Políticas Proximales (PPO) para mantener la estabilidad y la eficiencia mientras se exploran soluciones óptimas, mejorando significativamente el rendimiento del modelo en tareas de razonamiento complejas como matemáticas y programación.
- Alta precisión en el seguimiento de instrucciones:Comprende y cumple con precisión las instrucciones del usuario, generando texto de alta calidad y alineado con las expectativas según los requisitos del usuario.
Instrucciones de uso
- Registre una cuenta y obtenga una clave API:Primero, registre una cuenta en el sitio web oficial de Zhipu y adquiera una clave API.
- Revisar Documentación Oficial:Consulte la documentación oficial de la serie GLM-4 para obtener parámetros detallados e instrucciones de uso.
SenseChat 5.5 de SenceTime
Resumen Introducción
SenseChat 5.5, desarrollado por SenseTime, es la versión 5.5 de su gran modelo de lenguaje, basado en InternLM-123b, uno de los primeros grandes modelos de lenguaje de China construido sobre billones de parámetros y actualizado continuamente.

Principales características y ventajas
- Rendimiento potente e integral:Se ubica constantemente entre los primeros puestos en una variedad de tareas de evaluación, sobresaliendo en competencias fundamentales en humanidades y ciencias, así como en tareas avanzadas "difíciles". Demuestra un desempeño superior en comprensión y seguridad del lenguaje en humanidades, y se destaca en lógica y codificación en ciencias.
- Aplicaciones de borde eficientes:SenseTime ha lanzado la versión SenseChat Lite-5.5, que reduce el tiempo de carga inicial a solo 0,19 segundos, una mejora de 40% sobre SenseChat Lite-5.0 lanzado en abril, con una velocidad de inferencia que alcanza los 90,2 caracteres por segundo y un costo anual por dispositivo tan bajo como 9,9 yuanes.
- Capacidades lingüísticas excepcionales:Como aplicación de lenguaje natural, maneja eficazmente una gran cantidad de datos de texto, lo que demuestra un sólido diálogo en lenguaje natural, capacidades de razonamiento lógico, amplios conocimientos y actualizaciones frecuentes. Admite chino simplificado, chino tradicional, inglés y lenguajes de programación comunes.
Uso y aplicación de los productos
- Uso directo:Los usuarios pueden registrarse en el [sitio web de SenseTime] para acceder a SenseChat a través de la web o la aplicación móvil e interactuar con el modelo.
- Integración API:SenseTime ofrece acceso API para empresas y desarrolladores, lo que les permite integrar SenseChat 5.5 en sus productos o aplicaciones.
Qwen2.5-72B: instrucciones del equipo Qwen, Alibaba Cloud
Intruducción de modelos
Qwen2.5 es la última serie de modelos de lenguaje grandes de Qwen. Qwen2.5El equipo publicó una serie de modelos de lenguaje base y modelos de lenguaje ajustados a las instrucciones que van desde 0,5 a 72 mil millones de parámetros.
Características principales
- Modelos de lenguaje densos, fáciles de usar y solo con decodificador, disponibles en 0,5 mil millones, 1.5B, 3B, 7B, 14B, 32B, y 72B tamaños y variantes base e instructivas.
- Preentrenado en nuestro último conjunto de datos a gran escala, que abarca hasta 18T fichas.
- Mejoras significativas en el seguimiento de instrucciones, la generación de textos largos (más de 8K tokens), la comprensión de datos estructurados (por ejemplo, tablas) y la generación de salidas estructuradas, especialmente JSON.
- Más resistente a la diversidad de indicaciones del sistema, mejorando la implementación del juego de roles y el establecimiento de condiciones para los chatbots.
- La longitud del contexto admite hasta 128K tokens y pueden generar hasta 8K fichas.
- Soporte multilingüe para más de 29 idiomas, incluidos chino, inglés, francés, español, portugués, alemán, italiano, ruso, japonés, coreano, vietnamita, tailandés, árabe y más.
¿Cómo empezar rápidamente?
Puedes encontrar tutoriales para usar modelos grandes en Github y Hugging face. Con base en estos tutoriales, puedes ejecutar el modelo de manera efectiva y hacer realidad tus funciones e ideas.
Doubao-pro por el equipo Doubao, ByteDance
Resumen Introducción
Doubao-pro es un modelo de lenguaje grande desarrollado independientemente por ByteDance, lanzado oficialmente el 15 de mayo de 2024. En la plataforma de evaluación Flageval para modelos grandes, Doubao-pro ocupó el segundo lugar entre los modelos de código cerrado con una puntuación de 75,96.
- Versiones:Doubao-pro incluye versiones con ventanas de contexto de 4k, 32k y 128k, cada una de las cuales admite diferentes longitudes de contexto para inferencia y ajuste.
- Mejora del rendimiento:Según las pruebas internas de ByteDance, Doubao-pro-4k logró una puntuación total de 76,8 en 11 puntos de referencia públicos estándar de la industria.
Principales características y ventajas
- Fuertes habilidades integrales:Doubao-pro se destaca en matemáticas, aplicación de conocimientos y resolución de problemas en evaluaciones objetivas y subjetivas.
- Amplia gama de aplicaciones:Como uno de los modelos domésticos más utilizados y versátiles, el asistente de inteligencia artificial de Doubao, “Doubao”, ocupa el primer lugar en descargas entre las aplicaciones de AIGC en la App Store de Apple y los principales mercados de aplicaciones de Android.
- Alta relación costo-beneficio:El costo de entrada de inferencia de Doubao-pro-32k es de solo 0,0008 yuanes por cada mil tokens. Por ejemplo, procesar la versión china de Harry Potter (2,74 millones de caracteres) cuesta sólo 1,5 yuanes.
- Comprensión y generación de lenguaje excepcional:Doubao-pro comprende con precisión diversas entradas de lenguaje natural y genera respuestas coherentes, lógicas y de alta calidad, satisfaciendo las necesidades de los usuarios en preguntas y respuestas simples, creación de textos complejos y explicaciones en campos especializados.
- Velocidad de inferencia eficiente:Con un amplio entrenamiento y optimización de datos, Doubao-pro ofrece una ventaja en velocidad de inferencia, lo que permite tiempos de respuesta rápidos y una mejor experiencia de usuario, especialmente al manejar grandes volúmenes de texto o tareas complejas.
Métodos de uso
- A través del motor Volcán:Utilice Doubao-pro llamando a la API del modelo, con ejemplos de código disponibles en la documentación oficial de Volcano Engine.
- Para productos específicos:Doubao-pro está disponible para el mercado empresarial a través de Volcano Engine, lo que permite a las empresas integrarlo en sus productos o servicios. También puede experimentar el modelo Doubao a través de la aplicación Doubao.
360gpt2-pro de 360
Resumen Introducción
- Nombre del modelo:360GPT2-Pro es parte de la serie de modelos grandes 360 Zhibrain desarrollada por 360.
- Fundación técnicaAprovechando 20 años de datos de seguridad, 10 años de experiencia en IA y la experiencia de 80 expertos en IA y 100 expertos en seguridad, 360 utilizó 5000 recursos de GPU durante 200 días para entrenar y optimizar el modelo Zhibrain, siendo 360GPT2-Pro una de sus versiones avanzadas.

Principales características y ventajas
- Generación de lenguaje fuerte:Se destaca en tareas de generación de lenguaje, especialmente en humanidades, al crear contenido creativo, de alta calidad y lógicamente coherente, como historias y redacción de textos publicitarios.
- Comprensión y aplicación sólidas del conocimiento:Equipado con una amplia base de conocimientos, interpreta y aplica con precisión la información para responder preguntas y resolver problemas de manera eficaz.
- Generación basada en recuperación mejorada:Competente en generación aumentada de recuperación, particularmente para chino, lo que permite que el modelo genere respuestas alineadas con las necesidades del usuario y los datos del mundo real, reduciendo la probabilidad de alucinaciones.
- Funciones de seguridad mejoradas:Al beneficiarse de la amplia experiencia de 360 en seguridad, 360GPT2-Pro proporciona un nivel de seguridad y confiabilidad que aborda de manera eficaz diversos riesgos de seguridad.
Métodos de uso y productos relacionados
- Búsqueda 360AI:Integra 360GPT2-Pro con la funcionalidad de búsqueda para brindar a los usuarios una experiencia de búsqueda más completa y profunda.
- Navegador 360AI:Incorpora 360GPT2-Pro al navegador 360AI, lo que permite a los usuarios interactuar con el modelo a través de interfaces específicas o mediante entrada de voz para obtener información y sugerencias.
Paso 2-16k de stepfun
Resumen Introducción
- Revelador:StepStar lanzó la versión oficial del Modelo de lenguaje de dos billones de parámetros STEP en 2024, con step-2-16k haciendo referencia a su variante que admite una ventana de contexto de 16k.
- Arquitectura del modelo:Construido sobre una innovadora arquitectura MoE (Mixture of Experts), que activa dinámicamente diferentes modelos expertos en función de las tareas y la distribución de datos, mejorando tanto el rendimiento como la eficiencia.
- Escala de parámetros:Con un billón de parámetros, el modelo captura un amplio conocimiento del lenguaje e información semántica, mostrando capacidades poderosas en diversas tareas de procesamiento del lenguaje natural.

Principales características y ventajas
- Comprensión y generación de lenguaje potente:Interpreta con precisión el texto de entrada y genera respuestas naturales de alta calidad, respaldando tareas como responder preguntas, generación de contenido e intercambio conversacional con precisión y valor.
- Cobertura de conocimiento multidominioEntrenado en conjuntos de datos masivos, el modelo abarca un amplio conocimiento en áreas como matemáticas, lógica, programación, conocimiento y escritura creativa, lo que lo hace versátil para respuestas y aplicaciones de dominios cruzados.
- Capacidad de procesamiento de secuencias largasCon una ventana de contexto de 16k, el modelo se destaca en el manejo de secuencias de texto largas, facilitando la comprensión y el procesamiento de artículos extensos y documentos complejos.
- Rendimiento cercano a GPT-4Al lograr un rendimiento cercano a GPT-4 en múltiples tareas de lenguaje, este modelo muestra capacidades integrales de procesamiento del lenguaje de alto nivel.
Uso y aplicaciones
StepStar ofrece una plataforma abierta para que las empresas y los desarrolladores soliciten acceso a la modelo paso 2-16k.
Los usuarios pueden integrar el modelo en aplicaciones o proyectos de desarrollo a través de llamadas API, utilizando documentación proporcionada por la plataforma y herramientas de desarrollo para implementar diversas funcionalidades de procesamiento de lenguaje natural.
DeepSeek-V2.5 de deepseek
Resumen Introducción
DeepSeek-V2.5, desarrollado por el equipo de DeepSeek, es un potente modelo de lenguaje de código abierto que integra las capacidades de DeepSeek-V2-Chat y DeepSeek-Coder-V2-Instruct, lo que representa la culminación de los avances de modelos anteriores. Los detalles clave son los siguientes:
- Historial de desarrollo:En septiembre de 2024, lanzaron oficialmente DeepSeek-V2.5, que combina capacidades de chat y codificación. Esta versión mejora tanto el dominio general del lenguaje como la funcionalidad de codificación.
- Naturaleza de código abierto:En línea con el compromiso con el desarrollo de código abierto, DeepSeek-V2.5 ahora está disponible en Hugging Face, lo que permite a los desarrolladores ajustar y optimizar el modelo según sea necesario.

Principales características y ventajas
- Habilidades combinadas de lenguaje y codificación:DeepSeek-V2.5 conserva las capacidades conversacionales de un modelo de chat y las fortalezas de codificación de un modelo de codificador, lo que lo convierte en una verdadera solución "todo en uno" capaz de manejar conversaciones cotidianas, seguimiento de instrucciones complejas, generación y finalización de código.
- Alineación de preferencias humanas:Afinado para alinearse con las preferencias humanas, el modelo ha sido optimizado para la calidad de escritura y el cumplimiento de las instrucciones, funcionando de manera más natural e inteligente en múltiples tareas para comprender y satisfacer mejor las necesidades del usuario.
- Rendimiento excepcional: DeepSeek-V2.5 supera versiones anteriores en varios puntos de referencia y logra los mejores resultados en puntos de referencia de codificación como humaneval python y live code bench, lo que demuestra su fortaleza en la adherencia a las instrucciones y la generación de código.
- Soporte de contexto extendido:Con una longitud de contexto máxima de 128 000 tokens, DeepSeek-V2.5 maneja de manera eficaz textos largos y diálogos de varios turnos.
- Alta relación costo-beneficio:En comparación con los modelos de código cerrado de primer nivel como Soneto Claude 3.5 y GPT-4o, DeepSeek-V2.5 ofrece una ventaja de coste significativa.
Métodos de uso
- A través de la plataforma web:Acceda a DeepSeek-V2.5 a través de plataformas web como el patio de juegos DeepSeek-V2.5 de SiliconCloud.
- A través de API:Los usuarios pueden crear una cuenta para obtener una clave API y luego integrar DeepSeek-V2.5 en sus sistemas a través de la API para desarrollo secundario y aplicaciones.
- Implementación local: Requiere 8 GPU de 80 GB cada una y utiliza los Transformers de Hugging Face para la inferencia. Consulta la documentación y el código de muestra para conocer los pasos específicos.
- Dentro de productos específicos:
- Cursor:Este editor de código de IA, basado en VSCode, permite a los usuarios configurar el modelo DeepSeek-V2.5, conectándose a la API de SiliconCloud para la generación de código en la página a través de atajos, mejorando la eficiencia de la codificación.
- Otras herramientas o plataformas de desarrollo:Cualquier herramienta o plataforma de desarrollo que admita API de modelos de lenguaje externos puede, teóricamente, integrar DeepSeek-V2.5 obteniendo una clave API, lo que permite generar lenguaje y capacidades de escritura de código.
Vista previa del Ernie-4.0-turbo-8k de Baidu
Resumen Introducción
Vista previa del Ernie 4.0 Turbo 8k es parte de la serie ERNIE 4.0 Turbo de Baidu, lanzada oficialmente el 28 de junio de 2024 y completamente abierta a clientes empresariales el 5 de julio de 2024.
Principales características y ventajas
- Mejora del rendimiento:Como versión mejorada de ERNIE 4.0, este modelo extiende la longitud de entrada de contexto de 2k tokens a 8k tokens, lo que le permite manejar conjuntos de datos más grandes, leer más documentos o URL y desempeñarse mejor en tareas que involucran textos largos.
- Reducción de costos:Los costos de entrada y salida de ERNIE 4.0-turbo-8k-preview son tan bajos como 0,03 CNY por 1.000 tokens y 0,06 CNY por 1.000 tokens, una reducción de precio de 70% respecto de la versión general de ERNIE 4.0.
- Optimización técnica:Mejorado por la tecnología turbo, este modelo logra mejoras duales en velocidad de entrenamiento y rendimiento, lo que permite un entrenamiento y una implementación del modelo más rápidos.
- Amplia aplicación:Debido a sus ventajas de rendimiento y costo, el modelo es ampliamente aplicable en campos como el servicio de atención al cliente inteligente, los asistentes virtuales, la educación y el entretenimiento, y brinda una experiencia de conversación fluida y natural. Sus sólidas capacidades de generación también lo hacen muy adecuado para la creación de contenido y el análisis de datos.
Uso
La versión preliminar de ERNIE 4.0-turbo-8k está disponible principalmente para clientes empresariales, que pueden acceder a ella a través de la plataforma de modelos grandes Qianfan de Baidu en Baidu Intelligent Cloud.
Los 10 mejores modelos de IA creados por una empresa china
| Modelo | Revelador | Característica clave y fortaleza | Cómo utilizar |
| Hunyuan-Grande | Tencent | Código abierto, 398 mil millones de parámetros | Descargar el modelo |
| Disparo a la luna (kimi) | Inteligencia artificial para el lanzamiento de la luna | Capacidad de procesamiento de textos largos, alto nivel de comprensión del lenguaje | API, App oficial y herramientas |
| GLM-4-Plus | zhipu.ai | comprensión del lenguaje, seguimiento de instrucciones y procesamiento de textos largos. | API |
| SenseChat 5.5 | Tiempo de Sentido | Potente rendimiento integral, capacidades lingüísticas excepcionales | Sitio web de Sensetime, API |
| Qwen2.5-72B | Nube de Alibaba | La longitud del contexto admite hasta 128 K y soporte multilingüe para más de 29 idiomas. | Descargar modelo, sitio web oficial |
| Doubao-pro | ByteDanza | Fuertes capacidades integrales, alta relación costo-beneficio, chatbot, | Aplicación Daobao, API |
| 360gpt2-pro | 360 | Funciones de seguridad mejoradas, generación de lenguaje fuerte | Lobechat, el navegador 360AI |
| Paso 2-16k | Diversión para los pies | Modelo de lenguaje de billones de parámetros, cobertura de conocimiento multidominio, rendimiento cercano a GPT-4 | API |
| DeepSeek-V2.5 | búsqueda profunda | Habilidades combinadas de lenguaje y codificación, alineación de preferencias humanas | Plataforma web, API, implementación local |
| Ernie-4.0-turbo-8k | Baidu | Amplia aplicación, reducción de costos, | Sólo clientes empresariales |


