

Was ist das LLM-Modell??
Definition und Überblick
Ein KI-Modell ist ein Programm, das auf einen Datensatz trainiert wurde, um bestimmte Muster zu erkennen oder bestimmte Entscheidungen ohne weitere menschliche Eingriffe zu treffen.
Große Sprachmodelle, auch bekannt als LLMssind sehr große Deep-Learning-Modelle, die mit riesigen Datenmengen trainiert wurden.
Der zugrunde liegende Transformator ist eine Reihe neuronaler Netze, die aus einem Encoder und einem Decoder mit Selbstbeobachtungsfähigkeiten bestehen. Der Kodierer und der Dekodierer extrahieren Bedeutungen aus einer Textsequenz und verstehen die Beziehungen zwischen Wörtern und Sätzen darin.
Welches ist das beste Modell für Sie?
Große KI-Modelle entwickeln sich sehr schnell. Verschiedene Unternehmen und Forschungseinrichtungen präsentieren täglich neue Forschungsergebnisse und neue große Sprachmodelle.
Daher können wir Ihnen nicht mit Sicherheit sagen, welche die beste ist.
Es gibt jedoch Spitzenunternehmen und -modelle, wie OpenAI. Es gibt jetzt eine Reihe von Standards und Testfragen zur Bewertung von Modellen.
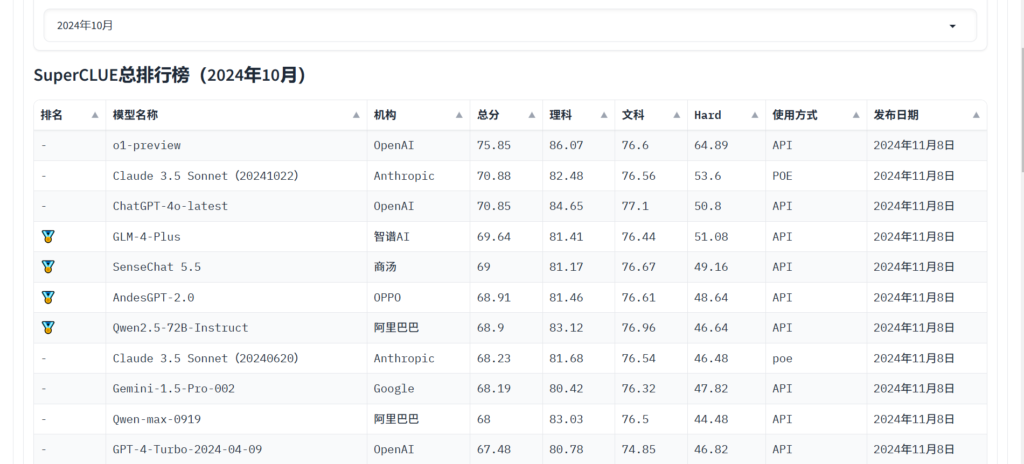
Sie können sich beziehen auf superclueai können Sie die Ergebnisse des Modells in verschiedenen Aufgaben einsehen und die für Sie passende auswählen. Außerdem können Sie die neuesten Nachrichten verfolgen, um mehr über die Fähigkeiten des LLM-Modells zu erfahren.
Hunyuan-Large von Tencent
Modell Einführung
Am 5. November, Tencent veröffentlicht Open-Source MoE Large Language Model Hunyuan-large mit insgesamt 398 Milliarden Parametern, was es zum größten in der Branche macht, mit 52 Milliarden Aktivierungsparametern.
Die Ergebnisse der öffentlichen Evaluierung zeigen, dass Tencents Hunyuan Large-Modell bei verschiedenen Projekten umfassend führend ist.

Technische Vorteile
- Synthetische Daten von hoher Qualität: Durch Verbesserung des Trainings mit synthetischen Daten, Hunyuan-Groß können umfassendere Repräsentationen lernen, Eingaben mit langem Kontext verarbeiten und besser auf ungesehene Daten verallgemeinern.
- KV-Cache-Komprimierung: Nutzt Grouped Query Attention (GQA) und Cross-Layer Attention (CLA) Strategien, um die Speichernutzung und den Rechenaufwand von KV-Caches deutlich zu reduzieren und den Inferenzdurchsatz zu verbessern.
- Experten-spezifische Skalierung der Lernrate: Legt unterschiedliche Lernraten für verschiedene Experten fest, um sicherzustellen, dass jedes Teilmodell effektiv aus den Daten lernt und zur Gesamtleistung beiträgt.
- Fähigkeit zur Verarbeitung langer Kontexte: Das vortrainierte Modell unterstützt Textsequenzen bis zu 256K und das Instruct-Modell bis zu 128K, was die Fähigkeit zur Bearbeitung von Aufgaben mit langem Kontext erheblich verbessert.
- Umfassendes Benchmarking: Durchführung umfangreicher Experimente mit verschiedenen Sprachen und Aufgaben, um die praktische Wirksamkeit und Sicherheit von Hunyuan-Large zu überprüfen.
Inferenzrahmen und Trainingsrahmen
Diese Open-Source-Version bietet zwei Inferenz-Backend-Optionen, die auf die Hunyuan - großes Modell: Die beliebte vLLM-Backend und die TensorRT-LLM Backend. Beide Lösungen beinhalten Optimierungen für eine verbesserte Leistung.
Das Open-Source-Modell von Hunyuan-Large ist vollständig kompatibel mit dem Hugging-Face-Format und ermöglicht Forschern und Entwicklern die Feinabstimmung des Modells mithilfe des hf-deepspeed-Frameworks. Zusätzlich unterstützen wir die Beschleunigung des Trainings durch die Verwendung von Flash Attention.
Wie man dieses Modell weiter verwendet
Dies ist ein Open-Source-Modell. Sie können "tencent-hunyuan" finden auf GitHubwo sie ausführliche Anleitungen und Gebrauchsanweisungen bereitstellen. Sie können sie weiter erkunden und erforschen, um mehr Möglichkeiten zu schaffen.
Moonshot(Kimi) von Moonshot AI
Zusammenfassung Einleitung
Moonshot ist ein umfangreiches Sprachmodell, das von Dark Side of the Moon entwickelt wurde. Hier finden Sie einen Überblick über seine Funktionen:
- Technologischer Durchbruch: Moonshot erzielt bemerkenswerte Fortschritte bei der Verarbeitung von Langtexten. Sein intelligentes Assistenzprodukt Kimichat unterstützt bis zu 2 Millionen chinesische Zeichen bei verlustfreier Kontexteingabe.
- Modell der Architektur: Durch den Einsatz einer innovativen Netzwerkstruktur und technischer Optimierungen wird eine weitreichende Aufmerksamkeit erreicht, ohne auf "Shortcut"-Lösungen wie gleitende Fenster, Downsampling oder kleinere Modelle zurückzugreifen, die häufig die Leistung beeinträchtigen. Dies ermöglicht ein umfassendes Verständnis ultralanger Texte, selbst bei Hunderten von Milliarden von Parametern.
- Anwendungsorientiert: Moonshot wurde mit dem Ziel entwickelt, ein unverzichtbares Werkzeug für die tägliche Arbeit der Nutzer zu werden, das auf der Grundlage des Feedbacks der Nutzer weiterentwickelt wird, um einen greifbaren Mehrwert zu schaffen.

Wesentliche Merkmale
- Fähigkeit zur Verarbeitung langer Texte: Sie sind in der Lage, umfangreiche Texte wie Romane oder komplette Finanzberichte zu bearbeiten und bieten den Nutzern tiefe, umfassende Einblicke und Zusammenfassungen langer Dokumente.
- Multimodale Fusion: Integriert mehrere Modalitäten und kombiniert Text mit Bilddaten, um die Analyse- und Generierungsmöglichkeiten zu verbessern.
- Hohe Sprachverständlichkeit und Generierungsfähigkeit: Hervorragende mehrsprachige Leistungen, genaue Interpretation der Benutzereingaben und Erstellung hochwertiger, kohärenter und semantisch angemessener Antworten.
- Flexible Skalierbarkeit: Bietet eine hohe Skalierbarkeit, die eine Anpassung und Optimierung auf der Grundlage verschiedener Anwendungsszenarien und -anforderungen ermöglicht und Entwicklern und Unternehmen ein hohes Maß an Flexibilität und Autonomie bietet.
Verwendungsmethoden
- API-Integration: Nutzer können sich auf der offiziellen Dark Side of the Moon-Plattform registrieren, einen API-Schlüssel beantragen und dann die Funktionen von Moonshot in ihre Anwendungen integrieren, indem sie die API mit kompatiblen Programmiersprachen nutzen.
- Verwendung offizieller Produkte und Tools: Nutzen Sie Kimichat, den intelligenten Assistenten, der auf dem Moonshot-Modell basiert, direkt oder nutzen Sie die damit verbundenen Tools und Plattformen, die von Dark Side of the Moon angeboten werden.
- Integration mit anderen Frameworks und Tools: Moonshot kann in gängige KI-Entwicklungsframeworks wie LangChain integriert werden, um robustere Sprachmodellanwendungen zu erstellen.
GLM-4-Plus von zhipu.ai
Zusammenfassung Einleitung
GLM-4-Plus, entwickelt von Zhipu AI, ist die neueste Iteration des vollständig selbst entwickelten GLM-Basismodells mit erheblichen Verbesserungen in den Bereichen Sprachverständnis, Befolgung von Anweisungen und Verarbeitung langer Texte.
Hauptmerkmale und Vorteile
- Ausgeprägtes Sprachverständnis: GLM-4-Plus wurde auf der Grundlage umfangreicher Datensätze und optimierter Algorithmen trainiert und zeichnet sich durch seine Fähigkeit aus, komplexe Semantik zu verarbeiten und die Bedeutung und den Kontext verschiedener Texte genau zu interpretieren.
- Hervorragende Langtextverarbeitung: Mit einem innovativen Speichermechanismus und einer segmentierten Verarbeitungstechnik kann GLM-4-Plus lange Texte mit bis zu 128k Token effektiv verarbeiten und ist damit sehr leistungsfähig in der Datenverarbeitung und Informationsextraktion.
- Erweiterte Reasoning-Fähigkeiten: Die Proximal Policy Optimization (PPO) sorgt für Stabilität und Effizienz bei der Suche nach optimalen Lösungen und verbessert die Leistung des Modells bei komplexen Denkaufgaben wie Mathematik und Programmierung erheblich.
- Hohe Genauigkeit bei der Befolgung von Anweisungen: Versteht die Anweisungen der Benutzer genau und hält sich an sie, indem er qualitativ hochwertige, erwartungsgerechte Texte auf der Grundlage der Benutzeranforderungen erstellt.
Gebrauchsanweisung
- Registrieren Sie ein Konto und erhalten Sie einen API-Schlüssel: Registrieren Sie zunächst ein Konto auf der offiziellen Website von Zhipu und erwerben Sie einen API-Schlüssel.
- Überprüfung der offiziellen Dokumentation: Detaillierte Parameter und Gebrauchsanweisungen finden Sie in der offiziellen Dokumentation der GLM-4-Serie.
SenseChat 5.5 von SenceTime
Zusammenfassung Einleitung
SenseChat 5.5, entwickelt von SenseTime, ist die Version 5.5 seines großen Sprachmodells, das auf dem InternLM-123b basiert, einem der ersten großen Sprachmodelle Chinas, das auf Billionen von Parametern basiert und ständig aktualisiert wird.

Hauptmerkmale und Vorteile
- Leistungsstarke, umfassende Performance: Bei einer Vielzahl von Bewertungsaufgaben belegt er durchgängig einen der vorderen Plätze, wobei er sowohl bei den grundlegenden Kompetenzen in den Geistes- und Naturwissenschaften als auch bei den fortgeschrittenen "harten" Aufgaben brilliert. Er zeigt überragende Leistungen in den Bereichen Sprachverständnis und Sicherheit in den Geisteswissenschaften und glänzt in Logik und Codierung in den Naturwissenschaften.
- Effiziente Edge-Anwendungen: SenseTime hat die Version SenseChat Lite-5.5 veröffentlicht, die die anfängliche Ladezeit auf nur 0,19 Sekunden reduziert, was eine Verbesserung von 40% gegenüber der im April veröffentlichten Version SenseChat Lite-5.0 darstellt, wobei die Inferenzgeschwindigkeit 90,2 Zeichen pro Sekunde erreicht und die jährlichen Kosten pro Gerät nur 9,9 Yuan betragen.
- Außergewöhnliche Sprachfähigkeiten: Als natürlichsprachliche Anwendung verarbeitet sie effektiv umfangreiche Textdaten und zeichnet sich durch einen robusten natürlichsprachlichen Dialog, logische Schlussfolgerungen, umfassende Kenntnisse und häufige Aktualisierungen aus. Sie unterstützt vereinfachtes Chinesisch, traditionelles Chinesisch, Englisch und gängige Programmiersprachen.
Verwendung und Anwendung Produkte
- Direkte Verwendung: Nutzer können sich auf der [SenseTime-Website] registrieren, um über das Web oder die mobile App auf SenseChat zuzugreifen und mit dem Modell zu interagieren.
- API-Integration: SenseTime bietet Unternehmen und Entwicklern einen API-Zugang, der es ihnen ermöglicht, SenseChat 5.5 in ihre Produkte oder Anwendungen zu integrieren.
Qwen2.5-72B-Instruct vom Qwen-Team, Alibaba Cloud
Modell Inturduktion
Qwen2.5 ist die neueste Serie der großen Sprachmodelle von Qwen. Für Qwen2.5veröffentlichte das Team eine Reihe von Basissprachmodellen und auf Anweisungen abgestimmte Sprachmodelle mit 0,5 bis 72 Milliarden Parametern.
Wesentliche Merkmale
- Dichte, einfach zu verwendende, reine Decoder-Sprachmodelle, verfügbar in 0.5B, 1.5B, 3B, 7B, 14B, 32Bund 72B Größen sowie Basis- und Anweisungsvarianten.
- Trainiert mit unserem neuesten großen Datensatz, der bis zu 18T Spielsteine.
- Erhebliche Verbesserungen bei der Befolgung von Anweisungen, der Erzeugung langer Texte (über 8K Token), dem Verständnis strukturierter Daten (z.B. Tabellen) und der Erzeugung strukturierter Ausgaben, insbesondere JSON.
- Sie sind widerstandsfähiger gegenüber der Vielfalt der Systemaufforderungen und verbessern die Umsetzung von Rollenspielen und die Festlegung von Bedingungen für Chatbots.
- Die Kontextlänge unterstützt bis zu 128K Token und kann bis zu 8K Spielsteine.
- Mehrsprachige Unterstützung für über 29 Sprachen, darunter Chinesisch, Englisch, Französisch, Spanisch, Portugiesisch, Deutsch, Italienisch, Russisch, Japanisch, Koreanisch, Vietnamesisch, Thailändisch, Arabisch und mehr.
Wie kann man schnell anfangen?
Tutorials zur Verwendung großer Modelle finden Sie auf Github und Hugging Face. Anhand dieser Tutorials können Sie das Modell effektiv ausführen und Ihre Funktionen und Ideen umsetzen.
Doubao-pro von Doubao Team, ByteDance
Zusammenfassung Einleitung
Doubao-pro ist ein großes Sprachmodell, das von ByteDance unabhängig entwickelt und am 15. Mai 2024 offiziell veröffentlicht wurde. Auf der Flageval-Bewertungsplattform für große Modelle belegte Doubao-pro mit einer Punktzahl von 75,96 den zweiten Platz unter den Closed-Source-Modellen.
- Versionen: Doubao-pro umfasst Versionen mit 4k, 32k und 128k Kontextfenstern, die jeweils unterschiedliche Kontextlängen für Inferenz und Feinabstimmung unterstützen.
- Leistungsverbesserung: Nach den internen Tests von ByteDance erreichte Doubao-pro-4k eine Gesamtpunktzahl von 76,8 bei 11 öffentlichen Benchmarks nach Industriestandard.
Hauptmerkmale und Vorteile
- Umfassende Fähigkeiten: Doubao-pro zeichnet sich in den Bereichen Mathematik, Wissensanwendung und Problemlösung durch objektive und subjektive Bewertungen aus.
- Breite Palette von Anwendungen: Als eines der meistgenutzten und vielseitigsten Haushaltsmodelle steht Doubaos KI-Assistent "Doubao" an erster Stelle der Downloads unter den AIGC-Anwendungen im Apple App Store und den wichtigsten Android-App-Märkten.
- Hohe Kosten-Wirksamkeit: Die Kosten für die Inferenz-Inputs von Doubao-pro-32k betragen nur 0,0008 Yuan pro tausend Token. Zum Beispiel die Verarbeitung der chinesischen Version von Harry Potter (2,74 Millionen Zeichen) kostet nur 1,5 Yuan.
- Hervorragendes Sprachverständnis und -erzeugung: Doubao-pro versteht verschiedene natürlichsprachliche Eingaben und generiert qualitativ hochwertige, kohärente und logische Antworten, die die Bedürfnisse der Benutzer bei einfachen Fragen und Antworten, bei der Erstellung komplexer Texte und bei Erklärungen in speziellen Bereichen erfüllen.
- Effiziente Inferenzgeschwindigkeit: Durch umfangreiches Datentraining und -optimierung bietet Doubao-pro einen Geschwindigkeitsvorteil bei der Inferenz, der schnelle Reaktionszeiten und eine verbesserte Benutzererfahrung ermöglicht, insbesondere bei der Bearbeitung großer Textmengen oder komplexer Aufgaben.
Verwendungsmethoden
- Durch Volcano Engine: Verwenden Sie Doubao-pro, indem Sie die API des Modells aufrufen. Codebeispiele finden Sie in der offiziellen Dokumentation der Volcano Engine.
- Für spezifische Produkte: Doubao-pro ist für den Unternehmensmarkt über die Volcano Engine verfügbar, so dass Unternehmen es in ihre Produkte oder Dienstleistungen integrieren können. Sie können das Doubao-Modell auch über die Doubao-App erleben.
360gpt2-pro von 360
Zusammenfassung Einleitung
- Name des Modells: 360GPT2-Pro ist Teil der von 360 entwickelten großen Modellreihe 360 Zhibrain.
- Technische Stiftung: Auf der Grundlage von 20 Jahren Sicherheitsdaten, 10 Jahren KI-Erfahrung und der Expertise von 80 KI- und 100 Sicherheitsexperten hat 360 in 200 Tagen 5.000 GPU-Ressourcen eingesetzt, um das Zhibrain-Modell zu trainieren und zu optimieren, wobei 360GPT2-Pro eine seiner fortgeschrittenen Versionen ist.

Hauptmerkmale und Vorteile
- Starke Sprache erzeugen: Hervorragende Leistungen bei der Erstellung von Sprache, insbesondere in den Geisteswissenschaften, durch die Erstellung hochwertiger, kreativer und logisch kohärenter Inhalte, z. B. Geschichten und Texte.
- Robustes Wissen Verstehen und Anwenden: Ausgestattet mit einer breiten Wissensbasis, interpretiert er Informationen genau und wendet sie an, um Fragen zu beantworten und Probleme effektiv zu lösen.
- Erweiterte Retrieval-basierte Generierung: Kompetente Retrieval-unterstützte Generierung, insbesondere für Chinesisch, die es dem Modell ermöglicht, Antworten zu generieren, die auf die Bedürfnisse des Nutzers und die realen Daten abgestimmt sind und die Wahrscheinlichkeit von Halluzinationen verringern.
- Verbesserte Sicherheitsmerkmale: 360GPT2-Pro profitiert von 360's langjähriger Erfahrung im Bereich der Sicherheit und bietet ein hohes Maß an Sicherheit und Zuverlässigkeit, um verschiedene Sicherheitsrisiken wirksam zu bekämpfen.
Verwendungsmethoden und verwandte Produkte
- 360AI Suche: Integriert 360GPT2-Pro in die Suchfunktionalität, um den Nutzern eine umfassendere und tiefgreifendere Suche zu ermöglichen.
- 360AI-Browser: Integriert 360GPT2-Pro in den 360AI-Browser, so dass Benutzer über spezifische Schnittstellen oder durch Spracheingabe mit dem Modell interagieren können, um Informationen und Vorschläge zu erhalten.
Schritt-2-16k von stepfun
Zusammenfassung Einleitung
- Entwickler: StepStar hat die offizielle Version des STEP-2 Sprachmodell mit Billionen Parametern im Jahr 2024, wobei sich step-2-16k auf seine Variante bezieht, die ein 16k-Kontextfenster unterstützt.
- Modell der Architektur: Aufbauend auf einer innovativen MoE-Architektur (Mixture of Experts), die dynamisch verschiedene Expertenmodelle auf der Grundlage von Aufgaben und Datenverteilung aktiviert und damit sowohl die Leistung als auch die Effizienz verbessert.
- Parameter Skala: Mit einer Billion Parametern erfasst das Modell umfangreiches Sprachwissen und semantische Informationen und bietet leistungsstarke Funktionen für verschiedene Aufgaben der natürlichen Sprachverarbeitung.

Hauptmerkmale und Vorteile
- Leistungsstarkes Sprachverständnis und -erzeugung: Interpretiert Eingabetexte genau und generiert qualitativ hochwertige, natürliche Antworten, die Aufgaben wie die Beantwortung von Fragen, die Erstellung von Inhalten und den Austausch von Gesprächen mit Genauigkeit und Wert unterstützen.
- Wissensabdeckung in mehreren Bereichen: Das Modell wurde anhand umfangreicher Datensätze trainiert und umfasst ein breites Wissen in Bereichen wie Mathematik, Logik, Programmierung, Wissen und kreatives Schreiben, was es vielseitig für bereichsübergreifende Antworten und Anwendungen macht.
- Fähigkeit zur Verarbeitung langer Sequenzen: Mit einem 16k-Kontextfenster zeichnet sich das Modell bei der Bearbeitung langer Textsequenzen aus und erleichtert das Verständnis und die Verarbeitung langer Artikel und komplexer Dokumente.
- Leistung nahe an GPT-4: Mit einer Leistung nahe GPT-4 in mehreren Sprachaufgaben zeigt dieses Modell umfassende Sprachverarbeitungsfähigkeiten auf hohem Niveau.
Verwendung und Anwendungen
StepStar bietet eine offene Plattform für Unternehmen und Entwickler, die sich für den Zugang zum Schritt-2-16k-Modell.
Benutzer können das Modell über API-Aufrufe in Anwendungen oder Entwicklungsprojekte integrieren und dabei die von der Plattform bereitgestellte Dokumentation und Entwicklungswerkzeuge zur Implementierung verschiedener Funktionen zur Verarbeitung natürlicher Sprache verwenden.
DeepSeek-V2.5 von deepseek
Zusammenfassung Einleitung
DeepSeek-V2.5ist ein leistungsfähiges Open-Source-Sprachmodell, das die Fähigkeiten von DeepSeek-V2-Chat und DeepSeek-Coder-V2-Instruct integriert und den Höhepunkt früherer Modellentwicklungen darstellt. Die wichtigsten Details sind wie folgt:
- Entwicklungsgeschichte: Im September 2024 wurde DeepSeek-V2.5 offiziell veröffentlicht, das Chat- und Codierfunktionen kombiniert. Diese Version verbessert sowohl die allgemeinen Sprachkenntnisse als auch die Codierungsfunktionen.
- Open Source Natur: Im Einklang mit der Verpflichtung zur Open-Source-Entwicklung ist DeepSeek-V2.5 jetzt auf Hugging Face verfügbar, so dass Entwickler das Modell nach Bedarf anpassen und optimieren können.

Hauptmerkmale und Vorteile
- Kombinierte Sprach- und Kodierfähigkeiten: DeepSeek-V2.5 behält die Konversationsfähigkeiten eines Chatmodells und die Codierstärken eines Codiermodells bei, was es zu einer echten "All-in-One"-Lösung macht, die in der Lage ist, alltägliche Konversationen zu führen, komplexe Anweisungen zu befolgen, Code zu generieren und zu vervollständigen.
- Ausrichtung an menschlichen Vorlieben: Das Modell wurde genau auf die menschlichen Vorlieben abgestimmt und hinsichtlich Schreibqualität und Einhaltung von Anweisungen optimiert. Es funktioniert natürlicher und intelligenter bei mehreren Aufgaben, um die Benutzeranforderungen besser zu verstehen und zu erfüllen.
- Hervorragende Leistung: DeepSeek-V2.5 übertrifft vorherige Versionen bei verschiedenen Benchmarks und erreicht Spitzenergebnisse bei Codierungs-Benchmarks wie Humaneval Python und Live Code Bench, was seine Stärke bei der Einhaltung von Anweisungen und der Codegenerierung zeigt.
- Erweiterte Kontextunterstützung: Mit einer maximalen Kontextlänge von 128.000 Token verarbeitet DeepSeek-V2.5 lange Texte und Dialoge mit mehreren Durchgängen effektiv.
- Hohe Kosten-Wirksamkeit: Im Vergleich zu erstklassigen Closed-Source-Modellen wie Claude 3.5 Sonett Und GPT-4o, DeepSeek-V2.5 bietet einen erheblichen Kostenvorteil.
Verwendungsmethoden
- Über die Webplattform: Greifen Sie über Webplattformen wie den DeepSeek-V2.5-Playground von SiliconCloud auf DeepSeek-V2.5 zu.
- Über API: Benutzer können ein Konto erstellen, um einen API-Schlüssel zu erhalten, und dann DeepSeek-V2.5 über die API für sekundäre Entwicklung und Anwendungen in ihre Systeme integrieren.
- Lokale Bereitstellung: Erfordert 8 GPUs mit jeweils 80 GB und verwendet Hugging Faces Transformers zur Inferenz. Einzelheiten zu den einzelnen Schritten finden Sie in der Dokumentation und im Beispielcode.
- Innerhalb bestimmter Produkte:
- Cursor: Mit diesem auf VSCode basierenden KI-Code-Editor können Benutzer das DeepSeek-V2.5-Modell konfigurieren und über Verknüpfungen eine Verbindung zur API von SiliconCloud herstellen, um auf der Seite Code zu generieren und so die Codierungseffizienz zu verbessern.
- Andere Entwicklungstools oder Plattformen: Jedes Entwicklungstool oder jede Plattform, die externe Sprachmodell-APIs unterstützt, kann DeepSeek-V2.5 theoretisch durch den Erhalt eines API-Schlüssels integrieren und so die Sprachgenerierung und Codeerstellung aktivieren.
Ernie-4.0-turbo-8k-preview von Baidu
Zusammenfassung Einleitung
Ernie-4.0-Turbo-8k-Vorschau ist Teil der ERNIE 4.0 Turbo-Serie von Baidu, die am 28. Juni 2024 offiziell veröffentlicht und am 5. Juli 2024 vollständig für Unternehmenskunden zugänglich gemacht wird.
Hauptmerkmale und Vorteile
- Leistungsverbesserung: Als aktualisierte Version von ERNIE 4.0 erweitert dieses Modell die Kontexteingabelänge von 2.000 auf 8.000 Token. Dadurch kann es größere Datensätze verarbeiten, mehr Dokumente oder URLs lesen und bei Aufgaben mit langen Texten eine bessere Leistung erzielen.
- Kostensenkung: Die Eingabe- und Ausgabekosten von ERNIE 4.0-turbo-8k-preview betragen nur 0,03 CNY pro 1.000 Token und 0,06 CNY pro 1.000 Token, eine Preissenkung von 70% gegenüber der allgemeinen Version von ERNIE 4.0.
- Technische Optimierung: Dieses durch die Turbotechnologie verbesserte Modell erreicht eine doppelte Verbesserung der Trainingsgeschwindigkeit und der Leistung und ermöglicht so ein schnelleres Training und eine schnellere Bereitstellung des Modells.
- Breite Anwendung: Aufgrund seiner Leistungs- und Kostenvorteile ist das Modell in vielen Bereichen wie intelligentem Kundenservice, virtuellen Assistenten, Bildung und Unterhaltung einsetzbar und sorgt für ein reibungsloses und natürliches Gesprächserlebnis. Aufgrund seiner robusten Generierungsfunktionen eignet es sich auch hervorragend für die Inhaltserstellung und Datenanalyse.
Verwendung
Die ERNIE 4.0-turbo-8k-preview ist in erster Linie für Unternehmenskunden verfügbar, die über Baidus Qianfan Large Model Platform auf Baidu Intelligent Cloud darauf zugreifen können.
Top 10 der von einem chinesischen Unternehmen entwickelten KI-Modelle
| Modell | Entwickler | Hauptmerkmal & Stärke | Anwendung |
| Hunyuan-Groß | Tencent | Open Source, 398 Milliarden Parameter | Laden Sie das Modell herunter |
| Mondschuss (Kimi) | Moonshot-KI | Fähigkeit zur Verarbeitung langer Texte, hohes Sprachverständnis | API, offizielle App und Tools |
| GLM-4-Plus | szhipu.ai | Sprachverständnis, Befolgen von Anweisungen und Verarbeitung langer Texte. | API |
| SenseChat 5.5 | SinnZeit | Leistungsstarke, umfassende Leistung, außergewöhnliche Sprachfähigkeiten | Sensetime-Website, API |
| Qwen2.5-72B | Alibaba Cloud | Kontextlänge unterstützt bis zu 128 KB, Mehrsprachigkeitsunterstützung für über 29 Sprachen | Modell herunterladen, offizielle Website |
| Doubao-pro | ByteDance | Starke umfassende Fähigkeiten, hohe Kosteneffizienz, Chatbot, | Daobao App, API |
| 360gpt2-pro | 360 | Erweiterte Sicherheitsfunktionen, starke Sprachgenerierung | Lobechat, 360AI-Browser |
| Schritt-2-16k | Stiefspaß | Billionen-Parameter-Sprachmodell,Multi-Domain-Wissensabdeckung,Leistung nahe an GPT-4 | API |
| DeepSeek-V2.5 | tiefseeken | Kombinierte Sprach- und Codierfähigkeiten, Ausrichtung an menschlichen Präferenzen | Webplattform, API, lokale Bereitstellung |
| Ernie-4.0-turbo-8k | Baidu | Breite Anwendung, Kostensenkung, | Nur Unternehmenskunden |


