

LLM คืออะไร?
ความหมายและภาพรวม
โมเดล AI คือโปรแกรมที่ได้รับการฝึกอบรมด้วยชุดข้อมูลเพื่อให้สามารถจดจำรูปแบบบางอย่างหรือตัดสินใจบางอย่างโดยไม่ต้องมีการแทรกแซงจากมนุษย์เพิ่มเติม
โมเดลภาษาขนาดใหญ่ หรือเรียกอีกอย่างว่า นิติศาสตร์มหาบัณฑิต (LLM)เป็นโมเดลการเรียนรู้เชิงลึกขนาดใหญ่ที่ได้รับการฝึกอบรมล่วงหน้าด้วยข้อมูลจำนวนมหาศาล
หม้อแปลงพื้นฐานคือชุดของเครือข่ายประสาทที่ประกอบด้วยตัวเข้ารหัสและตัวถอดรหัสที่มีความสามารถในการใส่ใจตัวเอง ตัวเข้ารหัสและตัวถอดรหัสจะแยกความหมายจากลำดับของข้อความและทำความเข้าใจความสัมพันธ์ระหว่างคำและวลีในนั้น
รุ่นไหนเหมาะกับคุณที่สุด?
โมเดลขนาดใหญ่ของ AI กำลังพัฒนาอย่างรวดเร็ว บริษัทและสถาบันวิจัยต่างๆ นำเสนอผลงานวิจัยใหม่ๆ ทุกวัน ควบคู่ไปกับโมเดลภาษาขนาดใหญ่ใหม่ๆ
ดังนั้นเราจึงไม่สามารถบอกคุณได้อย่างแน่ชัดว่าอันไหนดีที่สุด
อย่างไรก็ตาม มีบริษัทและโมเดลชั้นนำ เช่น OpenAI ปัจจุบันมีชุดมาตรฐานและคำถามทดสอบสำหรับประเมินโมเดล
คุณสามารถอ้างอิงได้ ซุปเปอร์คลูเอีย เพื่อดูคะแนนของแบบจำลองในงานต่างๆ และเลือกงานที่เหมาะกับคุณ นอกจากนี้ คุณยังสามารถติดตามข่าวสารล่าสุดเพื่อทราบข้อมูลเพิ่มเติมเกี่ยวกับความสามารถของแบบจำลอง LLM
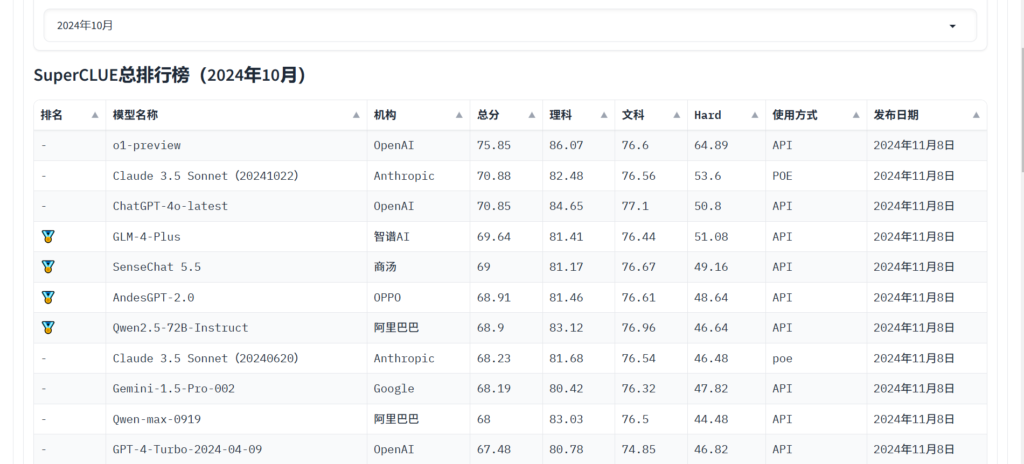
Hunyuan-Large โดย Tencent
การแนะนำแบบจำลอง
วันที่ 5 พฤศจิกายน เทนเซ็นต์ เปิดตัว Hunyuan-large Open-Source MoE Large Language Model ที่มีพารามิเตอร์ทั้งหมด 398 พันล้านตัว ซึ่งทำให้เป็นโมเดลภาษาที่ใหญ่ที่สุดในอุตสาหกรรม โดยมีพารามิเตอร์การเปิดใช้งาน 52 พันล้านตัว
ผลการประเมินสาธารณะแสดงให้เห็นว่าโมเดล Hunyuan Large ของ Tencent เป็นผู้นำอย่างครอบคลุมในโครงการต่างๆ

ข้อได้เปรียบทางเทคนิค
- ข้อมูลสังเคราะห์คุณภาพสูง:โดยการปรับปรุงการฝึกอบรมด้วยข้อมูลสังเคราะห์ ฮุนหยวน-ใหญ่ สามารถเรียนรู้การแสดงข้อมูลที่สมบูรณ์ยิ่งขึ้น จัดการอินพุตบริบทระยะยาว และสรุปผลข้อมูลที่ไม่เคยเห็นได้ดีขึ้น
- การบีบอัดแคช KV:ใช้กลยุทธ์ Grouped Query Attention (GQA) และ Cross-Layer Attention (CLA) เพื่อลดการใช้หน่วยความจำและค่าใช้จ่ายในการคำนวณของแคช KV อย่างมีนัยสำคัญ ซึ่งจะช่วยปรับปรุงอัตราการอนุมานที่ส่งผ่านข้อมูล
- การปรับขนาดอัตราการเรียนรู้เฉพาะผู้เชี่ยวชาญ:กำหนดอัตราการเรียนรู้ที่แตกต่างกันสำหรับผู้เชี่ยวชาญที่แตกต่างกันเพื่อให้แน่ใจว่าแต่ละโมเดลย่อยเรียนรู้จากข้อมูลอย่างมีประสิทธิภาพและมีส่วนสนับสนุนต่อประสิทธิภาพโดยรวม
- ความสามารถในการประมวลผลบริบทระยะยาว:โมเดลที่ผ่านการฝึกอบรมล่วงหน้ารองรับลำดับข้อความสูงสุดถึง 256K และโมเดล Instruct รองรับสูงสุดถึง 128K ซึ่งช่วยเพิ่มความสามารถในการจัดการงานบริบทระยะยาวได้อย่างมาก
- การเปรียบเทียบประสิทธิภาพที่ครอบคลุม:ดำเนินการทดลองอย่างกว้างขวางในภาษาและงานต่างๆ เพื่อตรวจยืนยันประสิทธิภาพในทางปฏิบัติและความปลอดภัยของ Hunyuan-Large
กรอบอนุมานและกรอบการฝึกอบรม
การเปิดตัวโอเพ่นซอร์สนี้นำเสนอตัวเลือกแบ็กเอนด์การอนุมานสองแบบที่ปรับแต่งสำหรับ ฮุนหยวน-โมเดลใหญ่: ความนิยม แบ็กเอนด์ vLLM และ เทนเซอร์RT-LLM แบ็กเอนด์ ทั้งสองโซลูชันมีการปรับแต่งเพื่อประสิทธิภาพที่ดีขึ้น
โมเดลโอเพ่นซอร์ส Hunyuan-Large เข้ากันได้อย่างสมบูรณ์กับรูปแบบ Hugging Face ช่วยให้นักวิจัยและนักพัฒนาปรับแต่งโมเดลได้โดยใช้กรอบงาน hf-deepspeed นอกจากนี้ เรายังรองรับการเร่งความเร็วในการฝึกโดยใช้แฟลชเอตเทอร์
วิธีใช้งานโมเดลนี้ต่อไป
นี่เป็นโมเดลโอเพ่นซอร์ส คุณสามารถค้นหา “tencent-hunyuan” ได้ที่ GitHubซึ่งมีคำแนะนำและคำแนะนำการใช้งานโดยละเอียด คุณสามารถศึกษาและค้นคว้าเพิ่มเติมเพื่อสร้างความเป็นไปได้เพิ่มเติมได้
มูนช็อต(คิมิ) โดย Moonshot AI
บทสรุป บทนำ
Moonshot คือโมเดลภาษาขนาดใหญ่ที่พัฒนาโดย Dark Side of the Moon ต่อไปนี้คือภาพรวมของคุณสมบัติต่างๆ:
- ความก้าวหน้าทางเทคโนโลยี:Moonshot ประสบความสำเร็จอย่างน่าทึ่งในการประมวลผลข้อความยาว ด้วยผลิตภัณฑ์ผู้ช่วยอัจฉริยะ Kimichat รองรับอักขระจีนสูงสุด 2 ล้านตัวในการป้อนบริบทแบบไม่สูญเสียข้อมูล
- สถาปัตยกรรมแบบจำลอง:ด้วยการใช้โครงสร้างเครือข่ายที่สร้างสรรค์และการเพิ่มประสิทธิภาพทางวิศวกรรม ทำให้สามารถให้ความสนใจในระยะไกลได้โดยไม่ต้องพึ่งพาโซลูชัน "ทางลัด" เช่น หน้าต่างแบบเลื่อน การดาวน์แซมปลิง หรือโมเดลขนาดเล็กที่มักจะทำให้ประสิทธิภาพลดลง ซึ่งช่วยให้เข้าใจข้อความยาวเป็นพิเศษได้อย่างครอบคลุม แม้ว่าจะมีพารามิเตอร์นับแสนล้านรายการก็ตาม
- เน้นการใช้งาน:Moonshot พัฒนาขึ้นโดยเน้นการใช้งานจริง โดยมีเป้าหมายที่จะเป็นเครื่องมือในชีวิตประจำวันที่ขาดไม่ได้สำหรับผู้ใช้ โดยพัฒนาบนพื้นฐานของความคิดเห็นจริงของผู้ใช้ เพื่อสร้างมูลค่าที่จับต้องได้

คุณสมบัติหลัก
- ความสามารถในการประมวลผลข้อความยาว:มีความสามารถในการจัดการข้อความจำนวนมาก เช่น นวนิยาย หรือรายงานทางการเงินฉบับสมบูรณ์ โดยนำเสนอข้อมูลเชิงลึกที่ครบถ้วนและเจาะลึก ตลอดจนบทสรุปของเอกสารยาวๆ ให้กับผู้ใช้
- การผสมผสานหลายรูปแบบ:บูรณาการโหมดต่างๆ มากมาย โดยผสมผสานข้อความกับข้อมูลภาพเพื่อเพิ่มประสิทธิภาพการวิเคราะห์และการสร้าง
- ความสามารถในการเข้าใจและการสร้างภาษาขั้นสูง:แสดงให้เห็นถึงประสิทธิภาพการใช้งานหลายภาษาที่ยอดเยี่ยม ตีความอินพุตของผู้ใช้ได้อย่างแม่นยำ และสร้างการตอบสนองที่มีคุณภาพสูง สอดคล้อง และเหมาะสมทางความหมาย
- ความสามารถในการปรับขนาดได้อย่างยืดหยุ่น:ให้ความสามารถในการปรับขนาดที่แข็งแกร่ง ช่วยให้ปรับแต่งและเพิ่มประสิทธิภาพได้ตามสถานการณ์และความต้องการแอปพลิเคชันที่แตกต่างกัน มอบความยืดหยุ่นและอิสระที่สำคัญให้กับนักพัฒนาและองค์กร
วิธีการใช้งาน
- การรวม API:ผู้ใช้สามารถลงทะเบียนบัญชีบนแพลตฟอร์มอย่างเป็นทางการของ Dark Side of the Moon สมัครขอรับรหัส API จากนั้นบูรณาการความสามารถของ Moonshot เข้ากับแอปพลิเคชันของตนโดยใช้ API ที่มีภาษาการเขียนโปรแกรมที่เข้ากันได้
- การใช้ผลิตภัณฑ์และเครื่องมืออย่างเป็นทางการ:ใช้ Kimichat ผลิตภัณฑ์ผู้ช่วยอัจฉริยะตามแบบจำลอง Moonshot โดยตรง หรือใช้ประโยชน์จากเครื่องมือและแพลตฟอร์มที่เกี่ยวข้องที่ให้บริการโดย Dark Side of the Moon
- การบูรณาการกับกรอบงานและเครื่องมืออื่น ๆ:Moonshot สามารถบูรณาการกับเฟรมเวิร์กการพัฒนา AI ยอดนิยม เช่น LangChain เพื่อสร้างแอปพลิเคชันโมเดลภาษาที่แข็งแกร่งยิ่งขึ้น
GLM-4-Plus โดย zhipu.ai
บทสรุป บทนำ
GLM-4-Plus ที่พัฒนาโดย Zhipu AI คือรุ่นล่าสุดของโมเดลรากฐาน GLM ที่พัฒนาขึ้นเองทั้งหมดซึ่งมีการปรับปรุงอย่างมากในด้านความเข้าใจภาษา การปฏิบัติตามคำสั่ง และการประมวลผลข้อความยาว
คุณสมบัติหลักและข้อดี
- ความเข้าใจภาษาที่แข็งแกร่ง:GLM-4-Plus ได้รับการฝึกฝนด้วยชุดข้อมูลที่ครอบคลุมและอัลกอริทึมที่ได้รับการปรับให้เหมาะสม ทำให้สามารถจัดการกับความหมายที่ซับซ้อนได้อย่างแม่นยำ ตีความความหมายและบริบทของข้อความต่างๆ ได้อย่างแม่นยำ
- การประมวลผลข้อความยาวที่โดดเด่น:ด้วยกลไกหน่วยความจำที่ล้ำสมัยและเทคนิคการประมวลผลแบบแบ่งส่วน GLM-4-Plus สามารถจัดการกับข้อความยาวๆ ได้อย่างมีประสิทธิภาพถึง 128,000 โทเค็น ทำให้มีประสิทธิภาพสูงในการประมวลผลข้อมูลและการดึงข้อมูล
- ความสามารถในการใช้เหตุผลที่เพิ่มขึ้น:ผสานรวม Proximal Policy Optimization (PPO) เพื่อรักษาเสถียรภาพและประสิทธิภาพในขณะที่สำรวจโซลูชันที่ดีที่สุด ปรับปรุงประสิทธิภาพของโมเดลอย่างมีนัยสำคัญในงานการใช้เหตุผลที่ซับซ้อน เช่น คณิตศาสตร์และการเขียนโปรแกรม
- ความแม่นยำในการปฏิบัติตามคำสั่งสูงเข้าใจและปฏิบัติตามคำแนะนำผู้ใช้ได้อย่างถูกต้อง โดยสร้างข้อความที่มีคุณภาพสูงและสอดคล้องกับความคาดหวังโดยอิงตามข้อกำหนดของผู้ใช้
คำแนะนำการใช้งาน
- ลงทะเบียนบัญชีและรับรหัส API:ขั้นแรกลงทะเบียนบัญชีบนเว็บไซต์อย่างเป็นทางการของ Zhipu และรับรหัส API
- ตรวจสอบเอกสารอย่างเป็นทางการ:โปรดดูเอกสารอย่างเป็นทางการของซีรีส์ GLM-4 เพื่อดูพารามิเตอร์โดยละเอียดและคำแนะนำการใช้งาน
SenseChat 5.5 โดย SenceTime
บทสรุป บทนำ
SenseChat 5.5 ที่พัฒนาโดย SenseTime เป็นเวอร์ชัน 5.5 ของโมเดลภาษาขนาดใหญ่ซึ่งมีพื้นฐานมาจาก InternLM-123b ซึ่งเป็นหนึ่งในโมเดลภาษาขนาดใหญ่รุ่นแรกๆ ของจีนที่สร้างขึ้นจากพารามิเตอร์นับล้านล้านตัวและอัปเดตอย่างต่อเนื่อง

คุณสมบัติหลักและข้อดี
- ประสิทธิภาพอันทรงพลังที่ครอบคลุม:อยู่ในอันดับต้นๆ อย่างสม่ำเสมอในงานประเมินผลที่หลากหลาย โดดเด่นในความสามารถพื้นฐานด้านมนุษยศาสตร์และวิทยาศาสตร์ รวมถึงงาน "ยาก" ขั้นสูง แสดงให้เห็นถึงประสิทธิภาพที่เหนือกว่าในการเข้าใจภาษาและความปลอดภัยในมนุษยศาสตร์ และโดดเด่นในด้านตรรกะและการเขียนโค้ดในวิทยาศาสตร์
- แอปพลิเคชัน Edge ที่มีประสิทธิภาพ:SenseTime ได้เปิดตัวเวอร์ชัน SenseChat Lite-5.5 ซึ่งลดเวลาการโหลดเริ่มต้นเหลือเพียง 0.19 วินาที ซึ่งปรับปรุง 40% เมื่อเทียบกับ SenseChat Lite-5.0 ที่เปิดตัวในเดือนเมษายน โดยมีความเร็วในการอนุมานถึง 90.2 อักขระต่อวินาที และค่าใช้จ่ายรายปีต่ออุปกรณ์ต่ำเพียง 9.9 หยวน
- ความสามารถด้านภาษาที่โดดเด่น:เนื่องจากเป็นแอปพลิเคชันภาษาธรรมชาติ จึงสามารถจัดการข้อมูลข้อความจำนวนมากได้อย่างมีประสิทธิภาพ แสดงให้เห็นถึงบทสนทนาภาษาธรรมชาติที่แข็งแกร่ง ความสามารถในการใช้เหตุผลเชิงตรรกะ ความรู้ที่กว้างขวาง และการอัพเดตบ่อยครั้ง นอกจากนี้ยังรองรับภาษาจีนตัวย่อ ภาษาจีนตัวเต็ม ภาษาอังกฤษ และภาษาโปรแกรมทั่วไปอีกด้วย
ผลิตภัณฑ์การใช้งานและการประยุกต์ใช้
- การใช้โดยตรงผู้ใช้สามารถลงทะเบียนบน [เว็บไซต์ SenseTime] เพื่อเข้าถึง SenseChat ผ่านทางเว็บหรือแอปมือถือและโต้ตอบกับนางแบบ
- การรวม API:SenseTime นำเสนอการเข้าถึง API ให้กับธุรกิจและนักพัฒนา ช่วยให้พวกเขาสามารถรวม SenseChat 5.5 เข้ากับผลิตภัณฑ์หรือแอปพลิเคชันของพวกเขาได้
Qwen2.5-72B-คำแนะนำโดยทีมงาน Qwen, Alibaba Cloud
แบบจำลองการแทรกซึม
Qwen2.5 คือซีรีส์ล่าสุดของโมเดลภาษาขนาดใหญ่ของ Qwen สำหรับ คเวน2.5ทีมได้เผยแพร่โมเดลภาษาพื้นฐานและโมเดลภาษาที่ปรับแต่งคำสั่งจำนวนหนึ่งซึ่งมีพารามิเตอร์ตั้งแต่ 0.5 ถึง 72 พันล้านพารามิเตอร์
คุณสมบัติที่สำคัญ
- โมเดลภาษาที่ถอดรหัสได้อย่างเดียว ใช้งานง่าย มีความหนาแน่น พร้อมใช้งานใน 0.5พัน, 1.5พันล้าน, 3บี, 7บี, 14 ข, 32บี, และ 72บี ขนาด และฐานและคำสั่งต่างๆ
- ได้รับการฝึกอบรมล่วงหน้าบนชุดข้อมูลขนาดใหญ่ล่าสุดของเรา ซึ่งครอบคลุมถึง 18ตัน โทเค็น
- การปรับปรุงที่สำคัญในคำสั่งการปฏิบัติตาม การสร้างข้อความยาวๆ (โทเค็นมากกว่า 8,000 รายการ) การทำความเข้าใจข้อมูลที่มีโครงสร้าง (เช่น ตาราง) และการสร้างเอาต์พุตที่มีโครงสร้าง โดยเฉพาะ JSON
- มีความยืดหยุ่นมากขึ้นต่อความหลากหลายของคำเตือนของระบบ เพิ่มประสิทธิภาพในการใช้งานการเล่นตามบทบาทและการกำหนดเงื่อนไขสำหรับแชทบอท
- ความยาวของบริบทรองรับได้ถึง 128K โทเค็นและสามารถสร้างได้มากถึง 8K โทเค็น
- รองรับหลายภาษาสำหรับมากกว่า 29 ภาษาต่างๆ รวมถึงจีน อังกฤษ ฝรั่งเศส สเปน โปรตุเกส เยอรมัน อิตาลี รัสเซีย ญี่ปุ่น เกาหลี เวียดนาม ไทย อาหรับ และอื่นๆ อีกมากมาย
จะเริ่มต้นอย่างรวดเร็วได้อย่างไร?
คุณสามารถค้นหาบทช่วยสอนเกี่ยวกับการใช้โมเดลขนาดใหญ่ได้ที่ Github และ Hugging face จากบทช่วยสอนเหล่านี้ คุณสามารถรันโมเดลและใช้งานฟังก์ชันและแนวคิดของคุณได้อย่างมีประสิทธิภาพ
Doubao-pro โดยทีม Doubao, ByteDance
บทสรุป บทนำ
Doubao-pro คือโมเดลภาษาขนาดใหญ่ที่พัฒนาขึ้นโดย ByteDance อย่างอิสระ เปิดตัวอย่างเป็นทางการเมื่อวันที่ 15 พฤษภาคม 2024 ในแพลตฟอร์มประเมิน Flageval สำหรับโมเดลขนาดใหญ่ Doubao-pro อยู่ในอันดับที่สองในบรรดาโมเดลแบบปิดซอร์สด้วยคะแนน 75.96
- เวอร์ชันต่างๆ:Dubao-pro ประกอบด้วยเวอร์ชันที่มีหน้าต่างบริบท 4k, 32k และ 128k โดยแต่ละเวอร์ชันรองรับความยาวบริบทที่แตกต่างกันสำหรับการอนุมานและปรับแต่งอย่างละเอียด
- การปรับปรุงประสิทธิภาพการทำงาน:ตามการทดสอบภายในของ ByteDance Doubao-pro-4k ได้คะแนนรวม 76.8 คะแนน จากเกณฑ์มาตรฐานอุตสาหกรรม 11 รายการ
คุณสมบัติหลักและข้อดี
- ความสามารถที่ครอบคลุมแข็งแกร่ง:Doubao-pro โดดเด่นในด้านคณิตศาสตร์ การประยุกต์ใช้ความรู้ และการแก้ปัญหาผ่านการประเมินแบบอัตนัยและแบบวัตถุประสงค์
- ขอบเขตการใช้งานที่กว้างขวาง:"Doubao" ซึ่งเป็นผู้ช่วย AI ของ Doubao เป็นหนึ่งในรุ่นภายในประเทศที่มีการใช้งานแพร่หลายที่สุดและมีความหลากหลายมากที่สุด โดยมียอดดาวน์โหลดสูงสุดในบรรดาแอพพลิเคชั่น AIGC บน Apple App Store และตลาดแอพพลิเคชั่น Android หลักๆ
- คุ้มค่าต้นทุนสูง:ต้นทุนการป้อนข้อมูลอนุมานของ Doubao-pro-32k อยู่ที่เพียง 0.0008 หยวนต่อโทเค็นหนึ่งพันตัว ตัวอย่างเช่น การประมวลผลเวอร์ชันภาษาจีนของ แฮรี่ พอตเตอร์ (2.74 ล้านตัวอักษร) ราคาเพียง 1.5 หยวน
- ความเข้าใจและการสร้างภาษาที่โดดเด่น:Doubao-pro เข้าใจอินพุตภาษาธรรมชาติที่หลากหลายได้อย่างแม่นยำและสร้างคำตอบที่มีคุณภาพสูง สอดคล้อง และมีเหตุผล ตอบสนองความต้องการของผู้ใช้ในรูปแบบถามตอบง่ายๆ การสร้างข้อความที่ซับซ้อน และการอธิบายในสาขาเฉพาะทาง
- ความเร็วในการอนุมานที่มีประสิทธิภาพ:ด้วยการฝึกอบรมและการเพิ่มประสิทธิภาพข้อมูลอย่างครอบคลุม Doubao-pro จึงมอบข้อได้เปรียบด้านความเร็วในการอนุมาน ช่วยให้ตอบสนองรวดเร็วขึ้นและเพิ่มประสบการณ์การใช้งานให้กับผู้ใช้ โดยเฉพาะอย่างยิ่งเมื่อต้องจัดการกับข้อความจำนวนมากหรืองานที่ซับซ้อน
วิธีการใช้งาน
- ผ่านเครื่องยนต์ภูเขาไฟ:ใช้ Doubao-pro โดยเรียก API ของโมเดล โดยมีตัวอย่างโค้ดอยู่ในเอกสารประกอบอย่างเป็นทางการของ Volcano Engine
- สำหรับผลิตภัณฑ์เฉพาะ:Dubao-pro มีจำหน่ายในตลาดองค์กรผ่าน Volcano Engine ช่วยให้ธุรกิจต่างๆ สามารถบูรณาการเข้ากับผลิตภัณฑ์หรือบริการของตนเองได้ นอกจากนี้ คุณยังสามารถสัมผัสประสบการณ์ของโมเดล Doubao ผ่านแอป Doubao ได้อีกด้วย
360gpt2-pro โดย 360
บทสรุป บทนำ
- ชื่อรุ่น:360GPT2-Pro เป็นส่วนหนึ่งของซีรีส์โมเดลขนาดใหญ่ 360 Zhibrain ที่พัฒนาโดย 360
- มูลนิธิทางเทคนิค:ด้วยการใช้ข้อมูลความปลอดภัย 20 ปี ประสบการณ์ด้าน AI 10 ปี และความเชี่ยวชาญของผู้เชี่ยวชาญด้าน AI 80 รายและผู้เชี่ยวชาญด้านความปลอดภัย 100 ราย 360 ใช้ทรัพยากร GPU จำนวน 5,000 รายการในเวลา 200 วันเพื่อฝึกอบรมและเพิ่มประสิทธิภาพให้กับโมเดล Zhibrain โดย 360GPT2-Pro เป็นหนึ่งในเวอร์ชันขั้นสูง

คุณสมบัติหลักและข้อดี
- การสร้างภาษาที่แข็งแกร่ง:มีความโดดเด่นในงานด้านการสร้างภาษา โดยเฉพาะในสาขาวิชามนุษยศาสตร์ โดยการสร้างเนื้อหาที่มีคุณภาพสูง สร้างสรรค์ และสอดคล้องกันอย่างมีตรรกะ เช่น เรื่องราวและการเขียนบทโฆษณา
- ความรู้ความเข้าใจและการประยุกต์ใช้ที่แข็งแกร่ง:ด้วยฐานความรู้ที่กว้างขวาง จึงสามารถตีความและประยุกต์ใช้ข้อมูลได้อย่างแม่นยำ เพื่อตอบคำถามและแก้ไขปัญหาได้อย่างมีประสิทธิภาพ
- การสร้างตามการค้นคืนที่ได้รับการปรับปรุง:มีความสามารถในการเรียกค้นข้อมูลแบบเพิ่มปริมาณ โดยเฉพาะอย่างยิ่งสำหรับชาวจีน ทำให้โมเดลสามารถสร้างการตอบสนองที่สอดคล้องกับความต้องการของผู้ใช้และข้อมูลในโลกแห่งความเป็นจริงได้ โดยลดความน่าจะเป็นของการเกิดภาพหลอน
- คุณสมบัติการรักษาความปลอดภัยขั้นสูง:360GPT2-Pro ได้รับประโยชน์จากความเชี่ยวชาญด้านความปลอดภัยที่ยาวนานของ 360 จึงมอบระดับความปลอดภัยและความน่าเชื่อถือ พร้อมจัดการกับความเสี่ยงด้านความปลอดภัยต่างๆ ได้อย่างมีประสิทธิภาพ
วิธีการใช้งานและผลิตภัณฑ์ที่เกี่ยวข้อง
- การค้นหา 360AI:บูรณาการ 360GPT2-Pro เข้ากับฟังก์ชันการค้นหาเพื่อมอบประสบการณ์การค้นหาที่ครอบคลุมและเจาะลึกมากขึ้นแก่ผู้ใช้
- เบราว์เซอร์ 360AI:รวม 360GPT2-Pro ไว้ใน 360AI Browser ช่วยให้ผู้ใช้สามารถโต้ตอบกับโมเดลผ่านอินเทอร์เฟซเฉพาะหรือผ่านการป้อนข้อมูลด้วยเสียงเพื่อรับข้อมูลและข้อเสนอแนะ
Step-2-16k โดย Stepfun
บทสรุป บทนำ
- ผู้พัฒนา:StepStar เปิดตัวเวอร์ชันอย่างเป็นทางการของ แบบจำลองภาษาพารามิเตอร์ล้านล้าน STEP-2 ในปี 2024 โดยขั้นตอนที่ 2-16k หมายถึงตัวแปรที่รองรับหน้าต่างบริบท 16k
- สถาปัตยกรรมแบบจำลอง:สร้างขึ้นบนสถาปัตยกรรม MoE (การผสมผสานผู้เชี่ยวชาญ) ที่เป็นนวัตกรรม ซึ่งเปิดใช้งานโมเดลผู้เชี่ยวชาญต่างๆ แบบไดนามิกตามงานและการกระจายข้อมูล ช่วยเพิ่มประสิทธิภาพและประสิทธิผล
- มาตราส่วนพารามิเตอร์:ด้วยพารามิเตอร์นับล้านล้าน โมเดลนี้จึงสามารถรวบรวมความรู้ด้านภาษาและข้อมูลด้านความหมายได้อย่างครอบคลุม แสดงให้เห็นถึงความสามารถอันทรงพลังในงานการประมวลผลภาษาธรรมชาติที่หลากหลาย

คุณสมบัติหลักและข้อดี
- ความเข้าใจและการสร้างภาษาอันทรงพลัง:ตีความข้อความอินพุตได้อย่างแม่นยำและสร้างการตอบสนองที่มีคุณภาพสูงและเป็นธรรมชาติ รองรับงานต่างๆ เช่น การตอบคำถาม การสร้างเนื้อหา และการแลกเปลี่ยนสนทนาด้วยความแม่นยำและมีค่า
- ความรู้ที่ครอบคลุมหลายโดเมน:แบบจำลองที่ได้รับการฝึกฝนบนชุดข้อมูลขนาดใหญ่ ครอบคลุมความรู้ที่กว้างขวางในสาขาต่างๆ เช่น คณิตศาสตร์ ตรรกะ การเขียนโปรแกรม ความรู้ และการเขียนเชิงสร้างสรรค์ ทำให้มีความยืดหยุ่นสำหรับการตอบสนองและการใช้งานแบบข้ามโดเมน
- ความสามารถในการประมวลผลลำดับยาว:ด้วยหน้าต่างบริบทขนาด 16,000 ตารางนิ้ว โมเดลนี้จึงเหมาะกับการจัดการลำดับข้อความยาวๆ ช่วยให้เข้าใจและประมวลผลบทความยาวๆ และเอกสารที่ซับซ้อนได้ง่ายขึ้น
- ประสิทธิภาพใกล้เคียงกับ GPT-4:ด้วยการบรรลุประสิทธิภาพที่ใกล้เคียง GPT-4 ในงานหลายภาษา โมเดลนี้แสดงให้เห็นถึงความสามารถในการประมวลผลภาษาที่ครอบคลุมระดับสูง
การใช้งานและแอปพลิเคชัน
StepStar มอบแพลตฟอร์มแบบเปิดสำหรับองค์กรและนักพัฒนาเพื่อสมัครขอเข้าถึง โมเดลขั้นที่ 2-16k.
ผู้ใช้สามารถบูรณาการโมเดลเข้ากับแอปพลิเคชันหรือโครงการพัฒนาต่างๆ ผ่านการเรียก API โดยใช้เอกสารประกอบและเครื่องมือการพัฒนาที่แพลตฟอร์มจัดให้เพื่อใช้งานฟังก์ชันการประมวลผลภาษาธรรมชาติต่างๆ
DeepSeek-V2.5 โดย deepseek
บทสรุป บทนำ
ดีพซีค-V2.5ซึ่งพัฒนาโดยทีมงาน DeepSeek เป็นโมเดลภาษาโอเพ่นซอร์สอันทรงพลังที่ผสานรวมความสามารถของ DeepSeek-V2-Chat และ DeepSeek-Coder-V2-Instruct เข้าด้วยกัน ซึ่งถือเป็นจุดสุดยอดของความก้าวหน้าจากโมเดลก่อนหน้านี้ รายละเอียดสำคัญมีดังนี้:
- ประวัติการพัฒนา:ในเดือนกันยายน 2024 พวกเขาได้เปิดตัว DeepSeek-V2.5 อย่างเป็นทางการ ซึ่งรวมความสามารถในการแชทและการเขียนโค้ดเข้าด้วยกัน เวอร์ชันนี้ช่วยพัฒนาทั้งความสามารถด้านภาษาทั่วไปและฟังก์ชันการเขียนโค้ด
- โอเพ่นซอร์สธรรมชาติ:สอดคล้องกับความมุ่งมั่นในการพัฒนาโอเพนซอร์ส DeepSeek-V2.5 พร้อมให้บริการบน Hugging Face แล้ว ช่วยให้นักพัฒนาสามารถปรับแต่งและเพิ่มประสิทธิภาพโมเดลตามต้องการได้

คุณสมบัติหลักและข้อดี
- ความสามารถด้านภาษาและการเขียนโค้ดรวมกัน:DeepSeek-V2.5 ยังคงความสามารถในการสนทนาของโมเดลการแชทและจุดแข็งในการเขียนโค้ดของโมเดลผู้เขียนโค้ด ทำให้เป็นโซลูชัน "ครบวงจร" อย่างแท้จริงที่สามารถจัดการการสนทนาในชีวิตประจำวัน การติดตามคำสั่งที่ซับซ้อน การสร้างโค้ด และการเสร็จสมบูรณ์
- การจัดแนวความชอบของมนุษย์:ปรับแต่งให้สอดคล้องกับความชอบของมนุษย์ โมเดลได้รับการปรับให้เหมาะสมสำหรับคุณภาพการเขียนและการปฏิบัติตามคำแนะนำ ทำงานได้เป็นธรรมชาติและชาญฉลาดมากขึ้นในงานต่างๆ มากมาย เพื่อให้เข้าใจและตอบสนองความต้องการของผู้ใช้ได้ดียิ่งขึ้น
- ประสิทธิภาพที่โดดเด่น: ดีพซีค-V2.5 เหนือกว่าเวอร์ชันก่อนหน้าในการประเมินผลต่างๆ และทำผลงานได้ดีที่สุดในการทำการทดสอบการเขียนโค้ด เช่น Humaneval Python และ Live Code Bench แสดงให้เห็นถึงความแข็งแกร่งในการยึดมั่นตามคำสั่งและการสร้างโค้ด
- การรองรับบริบทที่ขยาย:ด้วยความยาวบริบทสูงสุด 128,000 โทเค็น DeepSeek-V2.5 จัดการข้อความรูปแบบยาวและบทสนทนาหลายรอบได้อย่างมีประสิทธิภาพ
- คุ้มค่าต้นทุนสูง:เมื่อเทียบกับโมเดลปิดซอร์สระดับบนสุด เช่น คล็อด 3.5 โซเน็ต และ GPT-4o, ดีพซีค-V2.5 มีข้อได้เปรียบด้านต้นทุนที่สำคัญ
วิธีการใช้งาน
- ผ่านทางแพลตฟอร์มเว็บ:เข้าถึง DeepSeek-V2.5 ผ่านแพลตฟอร์มเว็บ เช่น สนามเด็กเล่น DeepSeek-V2.5 ของ SiliconCloud
- ผ่านทาง APIผู้ใช้สามารถสร้างบัญชีเพื่อรับรหัส API จากนั้นรวม DeepSeek-V2.5 เข้ากับระบบของตนผ่านทาง API สำหรับการพัฒนารองและแอปพลิเคชัน
- การปรับใช้ในพื้นที่:ต้องใช้ GPU 8 ตัว โดยแต่ละตัวจะมีขนาด 80GB โดยใช้ Transformers ของ Hugging Face สำหรับการอนุมาน โปรดดูเอกสารและโค้ดตัวอย่างสำหรับขั้นตอนเฉพาะ
- ภายในผลิตภัณฑ์เฉพาะ:
- เคอร์เซอร์:ตัวแก้ไขโค้ด AI นี้ซึ่งใช้ VSCode ช่วยให้ผู้ใช้สามารถกำหนดค่าโมเดล DeepSeek-V2.5 โดยเชื่อมต่อกับ API ของ SiliconCloud สำหรับการสร้างโค้ดบนหน้าผ่านทางลัด ช่วยเพิ่มประสิทธิภาพในการเขียนโค้ด
- เครื่องมือหรือแพลตฟอร์มการพัฒนาอื่น ๆ:เครื่องมือพัฒนาหรือแพลตฟอร์มใดๆ ที่รองรับ API โมเดลภาษาภายนอกสามารถบูรณาการ DeepSeek-V2.5 ได้ในทางทฤษฎีโดยการรับคีย์ API ช่วยให้สามารถสร้างภาษาและเขียนโค้ดได้
Ernie-4.0-turbo-8k-พรีวิวโดย Baidu
บทสรุป บทนำ
เออร์นี่-4.0-เทอร์โบ-8k-พรีวิว เป็นส่วนหนึ่งของซีรีส์ ERNIE 4.0 Turbo ของ Baidu เปิดตัวอย่างเป็นทางการเมื่อวันที่ 28 มิถุนายน 2024 และเปิดให้บริการอย่างเต็มรูปแบบแก่ลูกค้าองค์กรเมื่อวันที่ 5 กรกฎาคม 2024
คุณสมบัติหลักและข้อดี
- การปรับปรุงประสิทธิภาพการทำงาน:ในฐานะที่เป็นเวอร์ชันอัพเกรดของ ERNIE 4.0 โมเดลนี้ขยายความยาวของอินพุตบริบทจาก 2,000 โทเค็นเป็น 8,000 โทเค็น ช่วยให้สามารถจัดการชุดข้อมูลขนาดใหญ่ อ่านเอกสารหรือ URL ได้มากขึ้น และทำงานได้ดีขึ้นในงานที่มีข้อความยาวๆ
- การลดต้นทุน:ต้นทุนอินพุตและเอาต์พุตของ ERNIE 4.0-turbo-8k-preview ต่ำถึง 0.03 หยวนต่อ 1,000 โทเค็น และ 0.06 หยวนต่อ 1,000 โทเค็น ซึ่งลดราคาลง 70% จากเวอร์ชันทั่วไปของ ERNIE 4.0
- การเพิ่มประสิทธิภาพทางเทคนิค:ด้วยการปรับปรุงด้วยเทคโนโลยีเทอร์โบ ทำให้โมเดลนี้มีประสิทธิภาพและความเร็วในการฝึกที่ดีขึ้นสองเท่า ช่วยให้ฝึกและปรับใช้โมเดลได้เร็วยิ่งขึ้น
- การใช้งานที่กว้างขวาง:เนื่องจากประสิทธิภาพและข้อได้เปรียบด้านต้นทุน โมเดลนี้จึงสามารถนำไปประยุกต์ใช้อย่างแพร่หลายในสาขาต่างๆ เช่น บริการลูกค้าอัจฉริยะ ผู้ช่วยเสมือน การศึกษา และความบันเทิง ช่วยให้ประสบการณ์การสนทนาราบรื่นและเป็นธรรมชาติ ความสามารถในการสร้างที่แข็งแกร่งยังทำให้โมเดลนี้เหมาะอย่างยิ่งสำหรับการสร้างเนื้อหาและการวิเคราะห์ข้อมูลอีกด้วย
การใช้งาน
ERNIE 4.0-turbo-8k-preview นี้มีให้บริการแก่ลูกค้าองค์กรเป็นหลัก โดยลูกค้าเหล่านี้สามารถเข้าถึงได้ผ่าน Qianfan Large Model Platform ของ Baidu บน Baidu Intelligent Cloud
10 อันดับโมเดล AI ที่สร้างโดยบริษัทจีน
| แบบอย่าง | ผู้พัฒนา | คุณสมบัติหลักและจุดแข็ง | วิธีการใช้งาน |
| ฮุนหยวน-ใหญ่ | เทนเซ็นต์ | โอเพ่นซอร์ส 398 พันล้านพารามิเตอร์ | ดาวน์โหลดโมเดล |
| มูนช็อต(คิมิ) | มูนช็อต เอไอ | ความสามารถในการประมวลผลข้อความยาว ความเข้าใจภาษาสูง | API, แอปอย่างเป็นทางการและเครื่องมือ |
| จีแอลเอ็ม-4-พลัส | จิปูเอย | ความเข้าใจภาษา การปฏิบัติตามคำสั่ง และการประมวลผลข้อความยาว | เอพีไอ |
| เซนส์แชต 5.5 | เซนซ์ไทม์ | ประสิทธิภาพที่ครอบคลุมและความสามารถด้านภาษาที่โดดเด่น | เว็บไซต์ Sensetime, API |
| คิวเวน2.5-72บี | อาลีบาบาคลาวด์ | รองรับความยาวบริบทสูงสุด 128K รองรับหลายภาษาสำหรับมากกว่า 29 ภาษา | ดาวน์โหลดโมเดล เว็บไซต์อย่างเป็นทางการ |
| โดวเป่า-โปร | ไบต์แดนซ์ | ความสามารถที่ครอบคลุมแข็งแกร่ง คุ้มต้นทุนสูง แชทบอท | แอป Daobao,API |
| 360gpt2-โปร | 360 | คุณสมบัติการรักษาความปลอดภัยขั้นสูง การสร้างภาษาที่แข็งแกร่ง | Lobechat, เบราว์เซอร์ 360AI |
| ขั้นตอนที่ 2-16k | สเต็ปฟัน | แบบจำลองภาษาพารามิเตอร์ล้านล้าน การครอบคลุมความรู้หลายโดเมน ประสิทธิภาพใกล้เคียงกับ GPT-4 | เอพีไอ |
| ดีพซีค-V2.5 | การค้นหาอย่างลึกซึ้ง | ความสามารถด้านภาษาและการเขียนโค้ดผสมผสาน, การจัดแนวความชอบของมนุษย์ | แพลตฟอร์มเว็บ, API, การใช้งานในพื้นที่ |
| เออร์นี่-4.0-เทอร์โบ-8k | ไป่ตู้ | การใช้งานกว้างขวาง ลดต้นทุน | เฉพาะลูกค้าองค์กรเท่านั้น |


