

Ce este modelul LLM?
Definiție și prezentare generală
Un model AI este un program care a fost antrenat pe un set de date pentru a recunoaște anumite modele sau pentru a lua anumite decizii fără intervenție umană ulterioară.
Modele de limbaj mari, cunoscute și sub numele de LLM-uri, sunt modele de învățare profundă foarte mari care sunt pre-antrenate pe cantități mari de date.
Transformatorul de bază este un set de rețele neuronale care constau dintr-un encoder și un decodor cu capacități de auto-atenție. Codificatorul și decodorul extrag semnificații dintr-o secvență de text și înțeleg relațiile dintre cuvinte și expresii din aceasta.
Care este cel mai bun model pentru tine?
Modelele mari de AI se dezvoltă foarte rapid. Diferite companii și instituții de cercetare prezintă zilnic noi realizări în cercetare, împreună cu noi modele de limbaj mari.
Prin urmare, nu vă putem spune definitiv care este cel mai bun.
Cu toate acestea, există companii și modele de top, cum ar fi OpenAI. Există acum un set de standarde și întrebări de testare pentru a evalua modelele.
Vă puteți referi la superclueai pentru a vizualiza scorurile modelului la diverse sarcini și alegeți-l pe cel care vi se potrivește. De asemenea, puteți urmări cele mai recente știri pentru a afla mai multe despre capacitatea modelului LLM.
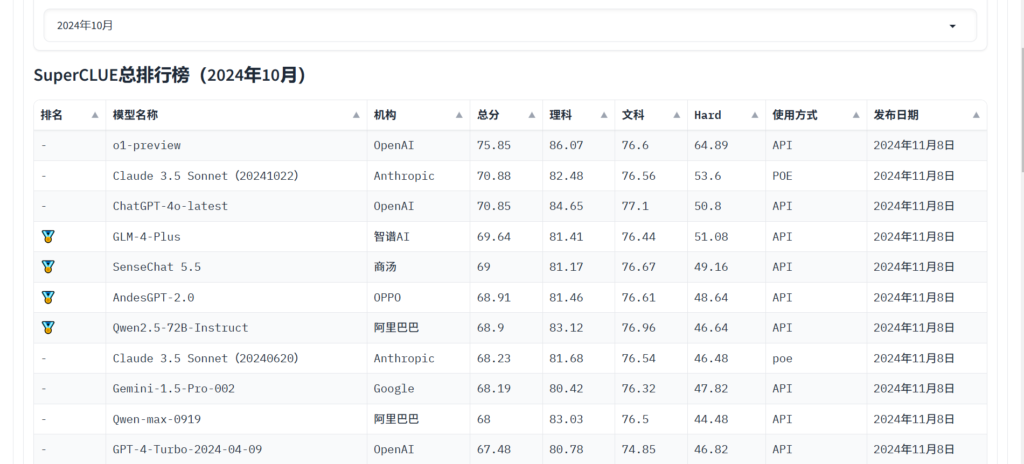
Hunyuan-Large de Tencent
Introducere model
Pe 5 noiembrie, Tencent lansează Open-Source MoE Large Language Model Hunyuan-large, cu un total de 398 de miliarde de parametri, ceea ce îl face cel mai mare din industrie, cu 52 de miliarde de parametri de activare.
Rezultatele evaluării publice arată că modelul Hunyuan Large de la Tencent conduce cuprinzător în diverse proiecte.

Avantaje tehnice
- Date sintetice de înaltă calitate: Prin îmbunătățirea antrenamentului cu date sintetice, Hunyuan-Large poate învăța reprezentări mai bogate, poate gestiona intrări în context lung și poate generaliza mai bine la date nevăzute.
- Compresie KV Cache: Utilizează strategiile Gruped Query Attention (GQA) și Cross-Layer Attention (CLA) pentru a reduce semnificativ utilizarea memoriei și supraîncărcarea de calcul a cache-urilor KV, îmbunătățind debitul de inferență.
- Scalare a ratei de învățare specifică experților: Setează rate de învățare diferite pentru diferiți experți pentru a se asigura că fiecare submodel învață eficient din date și contribuie la performanța generală.
- Capacitate de procesare a contextului lung: Modelul pre-antrenat acceptă secvențe de text de până la 256K, iar modelul Instruct acceptă până la 128K, îmbunătățind semnificativ capacitatea de a gestiona sarcini cu context lung.
- Benchmarking extins: Efectuează experimente extinse în diferite limbi și sarcini pentru a valida eficacitatea practică și siguranța lui Hunyuan-Large.
Cadrul de inferență și Cadrul de formare
Această versiune open-source oferă două opțiuni de backend de inferență adaptate pentru Hunyuan-Model mare: popularul vLLM-backend iar cel TensorRT-LLM Backend. Ambele soluții includ optimizări pentru performanță îmbunătățită.
Modelul open-source Hunyuan-Large este pe deplin compatibil cu formatul Hugging Face, permițând cercetătorilor și dezvoltatorilor să efectueze reglajul fin al modelului folosind cadrul hf-deepspeed. În plus, sprijinim accelerarea antrenamentului prin utilizarea atenției flash.
Cum să utilizați în continuare acest model
Acesta este un model open-source. Puteți găsi „tencent-hunyuan” pe GitHub, unde oferă instrucțiuni detaliate și ghiduri de utilizare. Îl puteți explora și cerceta în continuare pentru a crea mai multe posibilități.
Moonshot(Kimi) de Moonshot AI
Rezumat Introducere
Moonshot este un model de limbaj la scară largă dezvoltat de Dark Side of the Moon. Iată o prezentare generală a caracteristicilor sale:
- Descoperire tehnologică: Moonshot realizează progrese remarcabile în procesarea textului lung, cu produsul său asistent inteligent, Kimichat, care acceptă până la 2 milioane de caractere chinezești în introducerea contextului fără pierderi.
- Arhitectura modelului: Utilizând o structură de rețea inovatoare și optimizări de inginerie, obține o atenție pe rază lungă, fără a se baza pe soluții de „scurtătură” precum ferestre glisante, eșantionare sau modele mai mici care deteriorează adesea performanța. Acest lucru permite înțelegerea completă a textelor ultra-lungi chiar și cu sute de miliarde de parametri.
- Orientat spre aplicație: Dezvoltat cu accent pe aplicarea practică, Moonshot își propune să devină un instrument zilnic indispensabil pentru utilizatori, evoluând pe baza feedback-ului real al utilizatorilor pentru a genera valoare tangibilă.

Caracteristici cheie
- Capacitatea de procesare a textului lung: Capabil să gestioneze texte extinse, cum ar fi romane sau rapoarte financiare complete, oferind utilizatorilor perspective aprofundate și cuprinzătoare și rezumate ale documentelor lungi.
- Fuziune multimodală: integrează mai multe modalități, combinând textul cu datele de imagine pentru a îmbunătăți capacitățile de analiză și generare.
- Înțelegerea limbajului ridicat și capacitatea de generare: Demonstrează o performanță multilingvă excelentă, interpretând cu acuratețe inputurile utilizatorului și generând răspunsuri de înaltă calitate, coerente și adecvate semantic.
- Scalabilitate flexibilă: Oferă o scalabilitate puternică, permițând personalizarea și optimizarea pe baza diferitelor scenarii și nevoi de aplicație, oferind dezvoltatorilor și întreprinderilor flexibilitate și autonomie semnificative.
Metode de utilizare
- Integrare API: Utilizatorii se pot înregistra pentru un cont pe platforma oficială Dark Side of the Moon, pot solicita o cheie API și apoi pot integra capabilitățile Moonshot în aplicațiile lor folosind API-ul cu limbaje de programare compatibile.
- Utilizarea produselor și instrumentelor oficiale: Utilizați direct Kimichat, produsul asistent inteligent bazat pe modelul Moonshot, sau folosiți instrumentele și platformele asociate oferite de Dark Side of the Moon.
- Integrare cu alte cadre și instrumente: Moonshot poate fi integrat cu cadre populare de dezvoltare AI, cum ar fi LangChain, pentru a construi aplicații de model de limbaj mai robuste.
GLM-4-Plus de zhipu.ai
Rezumat Introducere
GLM-4-Plus, dezvoltat de Zhipu AI, este cea mai recentă iterație a modelului de bază GLM complet dezvoltat de sine, cu îmbunătățiri semnificative în înțelegerea limbii, urmărirea instrucțiunilor și procesarea textului lung.
Caracteristici cheie și avantaje
- Înțelegere puternică a limbajului: Instruit pe seturi extinse de date și algoritmi optimizați, GLM-4-Plus excelează în gestionarea semanticii complexe, interpretând cu acuratețe sensul și contextul diferitelor texte.
- Procesare remarcabilă a textului lung: Cu un mecanism inovator de memorie și o tehnică de procesare segmentată, GLM-4-Plus poate gestiona în mod eficient texte lungi de până la 128.000 de jetoane, ceea ce îl face extrem de competent în procesarea datelor și extragerea informațiilor.
- Capacități de raționament îmbunătățite: Încorporează Optimizarea politicii proximale (PPO) pentru a menține stabilitatea și eficiența în timp ce explorează soluții optime, îmbunătățind semnificativ performanța modelului în sarcini complexe de raționament precum matematica și programarea.
- Precizie ridicată în urma instrucțiunilor: înțelege cu acuratețe și aderă la instrucțiunile utilizatorului, generând text de înaltă calitate, aliniat la așteptări, bazat pe cerințele utilizatorului.
Instrucțiuni de utilizare
- Înregistrați un cont și obțineți o cheie API: În primul rând, înregistrați un cont pe site-ul oficial al lui Zhipu și obțineți o cheie API.
- Consultați documentația oficială: Consultați documentația oficială din seria GLM-4 pentru parametrii și instrucțiunile de utilizare detaliate.
SenseChat 5.5 de SenceTime
Rezumat Introducere
SenseChat 5.5, dezvoltat de SenseTime, este versiunea 5.5 a modelului său de limbă mare, bazat pe InternLM-123b, unul dintre cele mai vechi modele de limbaj mari din China, construit pe trilioane de parametri și actualizat continuu.

Caracteristici cheie și avantaje
- Performanță cuprinzătoare puternică: se clasează în mod constant printre primele niveluri într-o varietate de sarcini de evaluare, excelând în competențele fundamentale în științe umaniste și științe, precum și în sarcinile „grele” avansate. Demonstrează performanțe superioare în înțelegerea limbii și securitatea în științe umaniste și excelează în logică și codificare în științe.
- Aplicații Edge eficiente: SenseTime a lansat versiunea SenseChat Lite-5.5, care reduce timpul inițial de încărcare la doar 0,19 secunde, o îmbunătățire 40% față de SenseChat Lite-5.0 lansat în aprilie, cu viteza de inferență atingând 90,2 caractere pe secundă și un cost anual pe dispozitiv de până la 9,9 yuani.
- Capacități lingvistice excepționale: Ca aplicație în limbaj natural, gestionează în mod eficient date de text extinse, demonstrând dialog robust în limbaj natural, abilități de raționament logic, cunoștințe ample și actualizări frecvente. Acesta acceptă chineză simplificată, chineză tradițională, engleză și limbaje de programare comune.
Produse de utilizare și aplicare
- Utilizare directă: Utilizatorii se pot înregistra pe [site-ul web SenseTime] pentru a accesa SenseChat prin intermediul aplicației web sau mobile și a interacționa cu modelul.
- Integrare API: SenseTime oferă acces API pentru companii și dezvoltatori, permițându-le să integreze SenseChat 5.5 în produsele sau aplicațiile lor.
Qwen2.5-72B-Instruit de echipa Qwen, Alibaba Cloud
Model Inturduction
Qwen2.5 este cea mai recentă serie de modele de limbaj Qwen mari. Pentru Qwen2.5, echipa a lansat o serie de modele de limbaj de bază și modele de limbaj ajustate pentru instrucțiuni, variind de la 0,5 la 72 de miliarde de parametri.
Caracteristici cheie
- Modele de limbă dense, ușor de utilizat, numai pentru decodor, disponibile în 0,5B, 1.5B, 3B, 7B, 14B, 32B, și 72B dimensiuni și variante de bază și de instrucție.
- Preinstruit pe cel mai recent set de date pe scară largă, cuprinzând până la 18T jetoane.
- Îmbunătățiri semnificative în urmărirea instrucțiunilor, generarea de texte lungi (peste 8.000 de simboluri), înțelegerea datelor structurate (de exemplu, tabele) și generarea de rezultate structurate, în special JSON.
- Mai rezistent la diversitatea solicitărilor de sistem, îmbunătățind implementarea jocului de rol și setarea condițiilor pentru chatbot.
- Lungimea contextului acceptă până la 128K jetoane și poate genera până la 8K jetoane.
- Suport multilingv pentru peste 29 limbi, inclusiv chineză, engleză, franceză, spaniolă, portugheză, germană, italiană, rusă, japoneză, coreeană, vietnameză, thailandeză, arabă și multe altele.
Cum să începi rapid?
Puteți găsi tutoriale pentru utilizarea modelelor mari pe Github și Hugging face. Pe baza acestor tutoriale, puteți rula eficient modelul și vă puteți realiza funcțiile și ideile.
Doubao-pro de Doubao Team, ByteDance
Rezumat Introducere
Doubao-pro este un model de limbaj mare dezvoltat independent de ByteDance, lansat oficial pe 15 mai 2024. În platforma de evaluare Flageval pentru modele mari, Doubao-pro s-a clasat pe locul al doilea în rândul modelelor cu sursă închisă, cu un scor de 75,96.
- Versiuni: Doubao-pro include versiuni cu ferestre de context 4k, 32k și 128k, fiecare acceptând lungimi de context diferite pentru inferență și reglare fină.
- Îmbunătățirea performanței: Conform testelor interne ByteDance, Doubao-pro-4k a obținut un scor total de 76,8 la 11 benchmark-uri publice standard din industrie.
Caracteristici cheie și avantaje
- Abilități cuprinzătoare puternice: Doubao-pro excelează în matematică, aplicarea cunoștințelor și rezolvarea de probleme prin evaluări obiective și subiective.
- Gamă largă de aplicații: Fiind unul dintre cele mai utilizate și versatile modele autohtone, asistentul AI al lui Doubao, „Doubao”, se află pe primul loc la descărcări printre aplicațiile AIGC de pe Apple App Store și pe piețele majore de aplicații Android.
- Cost-eficiență ridicată: Costul de intrare a inferenței Doubao-pro-32k este de numai 0,0008 yuani per mia de jetoane. De exemplu, procesarea versiunii chineze a Harry Potter (2,74 milioane de caractere) costă doar 1,5 yuani.
- Înțelegerea și generarea limbii remarcabile: Doubao-pro înțelege cu acuratețe diverse intrări în limbaj natural și generează răspunsuri de înaltă calitate, coerente și logice, satisfacând nevoile utilizatorilor în întrebări și răspunsuri simple, creare de text complexe și explicații în domenii specializate.
- Viteză de inferență eficientă: Cu antrenament și optimizare extinsă a datelor, Doubao-pro oferă un avantaj al vitezei de inferență, permițând timpi de răspuns rapid și o experiență îmbunătățită a utilizatorului, în special atunci când se manipulează volume mari de text sau sarcini complexe.
Metode de utilizare
- Prin motorul vulcanului: Utilizați Doubao-pro apelând API-ul modelului, cu mostre de cod disponibile în documentația oficială a Volcano Engine.
- Pentru produse specifice: Doubao-pro este disponibil pentru piața întreprinderilor prin Volcano Engine, permițând companiilor să-l integreze în produsele sau serviciile lor. De asemenea, puteți experimenta modelul Doubao prin aplicația Doubao.
360gpt2-pro cu 360
Rezumat Introducere
- Numele modelului: 360GPT2-Pro face parte din seria de modele mari 360 Zhibrain dezvoltată de 360.
- Fundația tehnică: Folosind 20 de ani de date de securitate, 10 ani de experiență AI și expertiza a 80 de AI și 100 de experți în securitate, 360 a folosit 5.000 de resurse GPU în 200 de zile pentru a antrena și optimiza modelul Zhibrain, 360GPT2-Pro fiind una dintre versiunile sale avansate.

Caracteristici cheie și avantaje
- Generație de limbaj puternic: Excelează în sarcinile de generare a limbii, în special în științe umaniste, prin crearea de conținut de înaltă calitate, creativ și coerent din punct de vedere logic, cum ar fi povești și copywriting.
- Înțelegerea și aplicarea solidă a cunoștințelor: Dotat cu o bază largă de cunoștințe, interpretează și aplică cu acuratețe informațiile pentru a răspunde la întrebări și a rezolva problemele în mod eficient.
- Generare îmbunătățită bazată pe recuperare: Competent în generarea de recuperare sporită, în special pentru chinezi, permițând modelului să genereze răspunsuri care sunt aliniate cu nevoile utilizatorilor și cu datele din lumea reală, reducând probabilitatea de halucinație.
- Funcții de securitate îmbunătățite: Beneficiind de experiența de lungă durată a 360 în domeniul securității, 360GPT2-Pro oferă un nivel de siguranță și fiabilitate, abordând eficient diferitele riscuri de securitate.
Metode de utilizare și produse înrudite
- Căutare 360AI: integrează 360GPT2-Pro cu funcționalitatea de căutare pentru a oferi utilizatorilor o experiență de căutare mai cuprinzătoare și mai aprofundată.
- Browser 360AI: Încorporează 360GPT2-Pro în browserul 360AI, permițând utilizatorilor să interacționeze cu modelul prin intermediul unor interfețe specifice sau prin introducerea vocală pentru a obține informații și sugestii.
Pasul 2-16k cu distracția pas
Rezumat Introducere
- Dezvoltator: StepStar a lansat versiunea oficială a Model de limbaj STEP-2 trilioane de parametri în 2024, cu pasul 2-16k referitor la varianta sa care acceptă o fereastră de context de 16k.
- Arhitectura modelului: Construit pe o arhitectură inovatoare MoE (Mixture of Experts), care activează dinamic diferite modele de experți bazate pe sarcini și distribuția datelor, îmbunătățind atât performanța, cât și eficiența.
- Scala parametrilor: Cu un trilion de parametri, modelul captează cunoștințe extinse de limbă și informații semantice, afișând capabilități puternice în diferite sarcini de procesare a limbajului natural.

Caracteristici cheie și avantaje
- Înțelegerea și generarea puternică a limbajului: interpretează cu acuratețe textul introdus și generează răspunsuri naturale de înaltă calitate, susținând sarcini precum răspunsul la întrebări, generarea de conținut și schimbul conversațional cu acuratețe și valoare.
- Acoperire de cunoștințe multi-domeniu: Antrenat pe seturi de date masive, modelul cuprinde cunoștințe ample în domenii precum matematica, logica, programarea, cunoștințele și scrierea creativă, făcându-l versatil pentru răspunsuri și aplicații pe mai multe domenii.
- Capacitate de procesare în secvență lungă: Cu o fereastră de context de 16k, modelul excelează la manipularea secvențelor de text lungi, facilitând înțelegerea și procesarea articolelor lungi și a documentelor complexe.
- Performanță apropiată de GPT-4: Obținând performanțe aproape de GPT-4 în sarcini în mai multe limbi, acest model prezintă abilități cuprinzătoare de procesare a limbajului la nivel înalt.
Utilizare și aplicații
StepStar oferă o platformă deschisă pentru ca întreprinderile și dezvoltatorii să solicite acces la modelul pas-2-16k.
Utilizatorii pot integra modelul în aplicații sau proiecte de dezvoltare prin apeluri API, folosind documentația furnizată de platformă și instrumentele de dezvoltare pentru a implementa diferite funcționalități de procesare a limbajului natural.
DeepSeek-V2.5 de deepseek
Rezumat Introducere
DeepSeek-V2.5, dezvoltat de echipa DeepSeek, este un model de limbaj puternic open-source care integrează capabilitățile DeepSeek-V2-Chat și DeepSeek-Coder-V2-Instruct, reprezentând punctul culminant al progreselor anterioare ale modelului. Detaliile cheie sunt următoarele:
- Istoricul dezvoltării: În septembrie 2024, au lansat oficial DeepSeek-V2.5, combinând capabilitățile de chat și codare. Această versiune îmbunătățește atât competența generală a limbii, cât și funcționalitatea de codare.
- Open Source Nature: În conformitate cu angajamentul față de dezvoltarea open-source, DeepSeek-V2.5 este acum disponibil pe Hugging Face, permițând dezvoltatorilor să ajusteze și să optimizeze modelul după cum este necesar.

Caracteristici cheie și avantaje
- Limbaj combinat și abilități de codare: DeepSeek-V2.5 păstrează abilitățile conversaționale ale unui model de chat și punctele forte de codare ale unui model de codificator, făcându-l o adevărată soluție „tot-in-one”, capabilă să gestioneze conversațiile de zi cu zi, urmărirea complexă a instrucțiunilor, generarea și finalizarea codului.
- Alinierea preferințelor umane: Ajustat pentru a se alinia preferințelor umane, modelul a fost optimizat pentru calitatea scrisului și aderarea la instrucțiuni, funcționând mai natural și mai inteligent în mai multe sarcini pentru a înțelege mai bine și a satisface nevoile utilizatorilor.
- Performanță remarcabilă: DeepSeek-V2.5 depășește versiunile anterioare pe diferite benchmark-uri și obține rezultate de top în benchmark-uri de codare, cum ar fi humaneval python și live code bench, arătându-și puterea în aderarea la instrucțiuni și generarea de cod.
- Suport context extins: Cu o lungime maximă a contextului de 128.000 de jetoane, DeepSeek-V2.5 gestionează eficient textele de formă lungă și dialogurile cu mai multe rânduri.
- Cost-eficiență ridicată: În comparație cu modelele cu sursă închisă de top, cum ar fi Claude 3.5 Sonet şi GPT-4o, DeepSeek-V2.5 oferă un avantaj semnificativ de cost.
Metode de utilizare
- Prin platforma web: Accesați DeepSeek-V2.5 prin platforme web precum terenul de joacă DeepSeek-V2.5 de la SiliconCloud.
- Prin API: Utilizatorii își pot crea un cont pentru a obține o cheie API, apoi pot integra DeepSeek-V2.5 în sistemele lor prin intermediul API-ului pentru dezvoltare și aplicații secundare.
- Desfăşurare locală: Necesită 8 GPU-uri de 80 GB fiecare, folosind transformatoarele lui Hugging Face pentru deducere. Consultați documentația și codul exemplu pentru pași specifici.
- În cadrul Produselor Specifice:
- Cursor: Acest editor de cod AI, bazat pe VSCode, permite utilizatorilor să configureze modelul DeepSeek-V2.5, conectându-se la API-ul SiliconCloud pentru generarea codului pe pagină prin comenzi rapide, sporind eficiența codării.
- Alte instrumente sau platforme de dezvoltare: Orice instrument de dezvoltare sau platformă care acceptă API-uri de model de limbaj extern poate integra teoretic DeepSeek-V2.5 prin obținerea unei chei API, permițând generarea de limbaj și capabilitățile de scriere a codului.
Ernie-4.0-turbo-8k-preview de Baidu
Rezumat Introducere
Previzualizare Ernie-4.0-turbo-8k face parte din seria Baidu ERNIE 4.0 Turbo, lansată oficial pe 28 iunie 2024 și deschisă complet clienților întreprinderi pe 5 iulie 2024.
Caracteristici cheie și avantaje
- Îmbunătățirea performanței: Fiind o versiune actualizată a ERNIE 4.0, acest model extinde lungimea de introducere a contextului de la 2.000 de jetoane la 8.000 de jetoane, permițându-i să gestioneze seturi de date mai mari, să citească mai multe documente sau adrese URL și să funcționeze mai bine în sarcinile care implică texte lungi.
- Reducerea costurilor: Costurile de intrare și ieșire ale ERNIE 4.0-turbo-8k-preview sunt de până la 0,03 CNY per 1.000 de jetoane și 0,06 CNY per 1.000 de jetoane, o reducere de preț 70% față de versiunea generală a ERNIE 4.0.
- Optimizare tehnică: Îmbunătățit de tehnologia turbo, acest model realizează îmbunătățiri duble în viteza de antrenament și performanță, permițând antrenament și implementare mai rapidă a modelului.
- Aplicație largă: Datorită performanței și avantajelor sale de cost, modelul este aplicabil pe scară largă în domenii precum serviciul inteligent pentru clienți, asistenți virtuali, educație și divertisment, oferind o experiență de conversație fluidă și naturală. Capacitățile sale robuste de generare îl fac, de asemenea, foarte potrivit pentru crearea de conținut și analiza datelor.
Utilizare
Previzualizarea ERNIE 4.0-turbo-8k este disponibilă în primul rând clienților întreprinderi, care o pot accesa prin intermediul platformei Qianfan Large Model de la Baidu pe Baidu Intelligent Cloud.
Top 10 modele AI create de compania chineză
| Model | Dezvoltator | Caracteristica cheie & Puterea | Cum se utilizează |
| Hunyuan-Large | Tencent | Open source, 398 de miliarde de parametri | Descărcați modelul |
| Moonshot (kimi) | Moonshot AI | Capacitate de procesare a textului lung, înțelegere ridicată a limbii | API, aplicație și instrumente oficiale |
| GLM-4-Plus | zhipu.ai | înțelegerea limbii, urmărirea instrucțiunilor și procesarea textului lung. | API |
| SenseChat 5.5 | SenceTime | Performanță cuprinzătoare puternică, abilități lingvistice excepționale | Site web Sensetime, API |
| Qwen2.5-72B | Alibaba Cloud | Lungimea contextului acceptă până la 128K, suport multilingv pentru peste 29 de limbi | Descărcați modelul, site-ul oficial |
| Doubao-pro | ByteDance | Abilități cuprinzătoare puternice, rentabilitate ridicată, chatbot, | Aplicația Daobao, API |
| 360gpt2-pro | 360 | Caracteristici de securitate îmbunătățite, generare de limbaj puternic | Lobechat, browser 360AI |
| Pasul-2-16k | stepfun | model de limbă cu trilioane de parametri, acoperire a cunoștințelor pe mai multe domenii, performanță apropiată de GPT-4 | API |
| DeepSeek-V2.5 | deepseek | Limbaj combinat și abilități de codare, aliniere a preferințelor umane | Platformă web, API, implementare locală |
| Ernie-4.0-turbo-8k | Baidu | Aplicație largă, reducerea costurilor, | Doar clienții întreprinderi |


