

एलएलएम मॉडल क्या है?
परिभाषा और अवलोकन
एआई मॉडल एक प्रोग्राम है जिसे डेटा के एक सेट पर प्रशिक्षित किया गया है ताकि वह बिना किसी मानवीय हस्तक्षेप के कुछ पैटर्न को पहचान सके या कुछ निर्णय ले सके।
बड़े भाषा मॉडल, जिन्हें 'बड़े भाषा मॉडल' के नाम से भी जाना जाता है। एलएलएम, बहुत बड़े गहन शिक्षण मॉडल हैं जो विशाल मात्रा में डेटा पर पूर्व प्रशिक्षित होते हैं।
अंतर्निहित ट्रांसफॉर्मर न्यूरल नेटवर्क का एक सेट है जिसमें एक एनकोडर और एक डिकोडर होता है जिसमें स्व-ध्यान क्षमताएं होती हैं। एनकोडर और डिकोडर पाठ के अनुक्रम से अर्थ निकालते हैं और उसमें शब्दों और वाक्यांशों के बीच संबंधों को समझते हैं।
आपके लिए कौन सा मॉडल सबसे अच्छा है?
एआई के बड़े मॉडल बहुत तेज़ी से विकसित हो रहे हैं। अलग-अलग कंपनियाँ और शोध संस्थान रोज़ाना नई शोध उपलब्धियाँ पेश करते हैं, साथ ही नए बड़े भाषा मॉडल भी पेश करते हैं।
इसलिए, हम निश्चित रूप से आपको यह नहीं बता सकते कि कौन सा सर्वोत्तम है।
हालाँकि, ओपनएआई जैसी शीर्ष-स्तरीय कंपनियाँ और मॉडल मौजूद हैं। अब मॉडलों का मूल्यांकन करने के लिए मानकों और परीक्षण प्रश्नों का एक सेट है।
आप संदर्भ ले सकते हैं सुपरक्लूएआई विभिन्न कार्यों में मॉडल के स्कोर देखने और अपने लिए उपयुक्त एक को चुनने के लिए। इसके अलावा, आप LLM मॉडल की क्षमता के बारे में अधिक जानने के लिए नवीनतम समाचारों का अनुसरण कर सकते हैं।
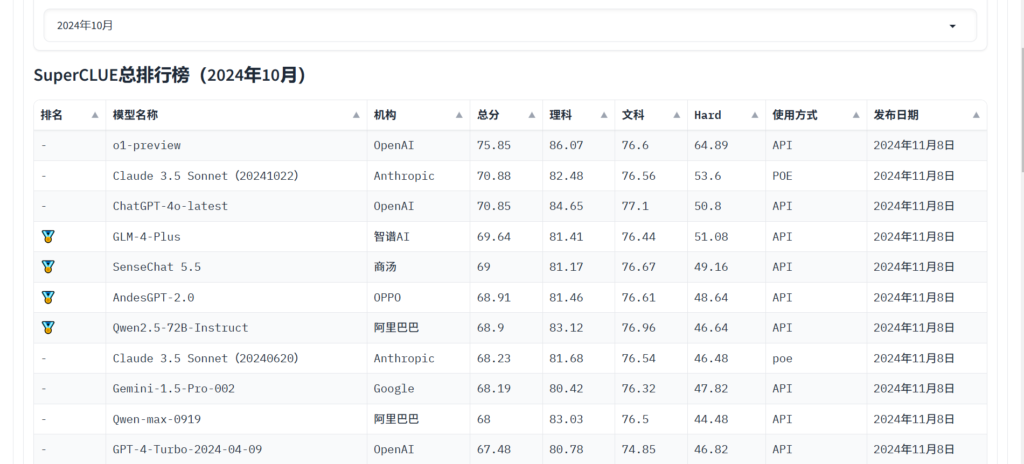
Tencent द्वारा हुनयुआन-लार्ज
मॉडल परिचय
5 नवंबर को, Tencent ओपन-सोर्स MoE लार्ज लैंग्वेज मॉडल हुनयुआन-लार्ज को कुल 398 बिलियन पैरामीटर्स के साथ जारी किया गया है, जो 52 बिलियन एक्टिवेशन पैरामीटर्स के साथ उद्योग में सबसे बड़ा है।
सार्वजनिक मूल्यांकन के परिणाम बताते हैं कि Tencent का हुनयुआन लार्ज मॉडल विभिन्न परियोजनाओं में व्यापक रूप से अग्रणी है।

तकनीकी लाभ
- उच्च गुणवत्ता वाला सिंथेटिक डेटा: सिंथेटिक डेटा के साथ प्रशिक्षण को बढ़ाकर, हुनयुआन-बड़ा समृद्ध प्रतिनिधित्व सीख सकते हैं, दीर्घ-संदर्भ इनपुट को संभाल सकते हैं, तथा अदृश्य डेटा को बेहतर ढंग से सामान्यीकृत कर सकते हैं।
- केवी कैश संपीड़न: ग्रुप्ड क्वेरी अटेंशन (GQA) और क्रॉस-लेयर अटेंशन (CLA) रणनीतियों का उपयोग करके KV कैश के मेमोरी उपयोग और कम्प्यूटेशनल ओवरहेड को काफी कम किया जाता है, जिससे अनुमान थ्रूपुट में सुधार होता है।
- विशेषज्ञ-विशिष्ट शिक्षण दर स्केलिंग: यह विभिन्न विशेषज्ञों के लिए अलग-अलग सीखने की दरें निर्धारित करता है, ताकि यह सुनिश्चित हो सके कि प्रत्येक उप-मॉडल डेटा से प्रभावी रूप से सीखता है और समग्र प्रदर्शन में योगदान देता है।
- दीर्घ-संदर्भ प्रसंस्करण क्षमतापूर्व-प्रशिक्षित मॉडल 256K तक के पाठ अनुक्रमों का समर्थन करता है, और इंस्ट्रक्ट मॉडल 128K तक का समर्थन करता है, जो लंबे-संदर्भ कार्यों को संभालने की क्षमता को महत्वपूर्ण रूप से बढ़ाता है।
- व्यापक बेंचमार्किंगहुनयुआन-लार्ज की व्यावहारिक प्रभावशीलता और सुरक्षा को प्रमाणित करने के लिए विभिन्न भाषाओं और कार्यों में व्यापक प्रयोग आयोजित करता है।
अनुमान फ्रेमवर्क और प्रशिक्षण फ्रेमवर्क
यह ओपन-सोर्स रिलीज़ दो अनुमान बैकएंड विकल्प प्रदान करता है जो कि अनुकूलित हैं हुनयुआन-बड़ा मॉडल: प्रसिद्ध vLLM-बैकएंड और यह टेंसरआरटी-एलएलएम बैकएंड: दोनों समाधानों में बेहतर प्रदर्शन के लिए अनुकूलन शामिल हैं।
हुनयुआन-लार्ज ओपन-सोर्स मॉडल हगिंग फेस प्रारूप के साथ पूरी तरह से संगत है, जिससे शोधकर्ताओं और डेवलपर्स को एचएफ-डीपस्पीड फ्रेमवर्क का उपयोग करके मॉडल को ठीक करने में मदद मिलती है। इसके अतिरिक्त, हम फ्लैश अटेंशन के उपयोग के माध्यम से प्रशिक्षण त्वरण का समर्थन करते हैं।
इस मॉडल का आगे उपयोग कैसे करें
यह एक ओपन-सोर्स मॉडल है। आप “tencent-hunyuan” को यहाँ पा सकते हैं GitHub, जहां वे विस्तृत निर्देश और उपयोग मार्गदर्शिकाएँ प्रदान करते हैं। आप और अधिक संभावनाएँ बनाने के लिए इसे और अधिक खोज और शोध कर सकते हैं।
मूनशॉट(किमि) मूनशॉट एआई द्वारा
सारांश परिचय
मूनशॉट डार्क साइड ऑफ़ द मून द्वारा विकसित एक बड़े पैमाने का भाषा मॉडल है। यहाँ इसकी विशेषताओं का अवलोकन दिया गया है:
- तकनीकी सफलतामूनशॉट ने अपने स्मार्ट सहायक उत्पाद, किमिचाट के साथ, लंबे-पाठ प्रसंस्करण में उल्लेखनीय प्रगति हासिल की है, जो दोषरहित संदर्भ इनपुट में 2 मिलियन चीनी अक्षरों तक का समर्थन करता है।
- मॉडल वास्तुकला: एक अभिनव नेटवर्क संरचना और इंजीनियरिंग अनुकूलन को नियोजित करके, यह स्लाइडिंग विंडो, डाउनसैंपलिंग या छोटे मॉडल जैसे "शॉर्टकट" समाधानों पर निर्भर किए बिना लंबी दूरी का ध्यान प्राप्त करता है जो अक्सर प्रदर्शन को खराब करते हैं। यह सैकड़ों अरबों मापदंडों के साथ भी अल्ट्रा-लंबे पाठों की व्यापक समझ को सक्षम बनाता है।
- अनुप्रयोग-उन्मुखव्यावहारिक अनुप्रयोग पर ध्यान केंद्रित करते हुए विकसित, मूनशॉट का लक्ष्य उपयोगकर्ताओं के लिए एक अपरिहार्य दैनिक उपकरण बनना है, जो मूर्त मूल्य उत्पन्न करने के लिए वास्तविक उपयोगकर्ता प्रतिक्रिया के आधार पर विकसित होता है।

प्रमुख विशेषताऐं
- लंबे-पाठ प्रसंस्करण क्षमता: उपन्यास या पूर्ण वित्तीय रिपोर्ट जैसे व्यापक पाठों को संभालने में सक्षम, उपयोगकर्ताओं को गहन, व्यापक अंतर्दृष्टि और लंबे दस्तावेजों के सारांश प्रदान करता है।
- मल्टीमॉडल फ्यूजन: विश्लेषण और उत्पादन क्षमताओं को बढ़ाने के लिए छवि डेटा के साथ पाठ को संयोजित करके कई तौर-तरीकों को एकीकृत करता है।
- उच्च भाषा समझ और उत्पादन क्षमताउत्कृष्ट बहुभाषी प्रदर्शन प्रदर्शित करता है, उपयोगकर्ता इनपुट की सटीक व्याख्या करता है और उच्च गुणवत्ता वाले, सुसंगत और अर्थपूर्ण रूप से उपयुक्त प्रतिक्रियाएं उत्पन्न करता है।
- लचीली मापनीयता: मजबूत मापनीयता प्रदान करता है, विभिन्न अनुप्रयोग परिदृश्यों और आवश्यकताओं के आधार पर अनुकूलन और अनुकूलन की अनुमति देता है, डेवलपर्स और उद्यमों को महत्वपूर्ण लचीलापन और स्वायत्तता प्रदान करता है।
उपयोग के तरीके
- एपीआई एकीकरणउपयोगकर्ता डार्क साइड ऑफ द मून के आधिकारिक प्लेटफॉर्म पर एक खाते के लिए पंजीकरण कर सकते हैं, एपीआई कुंजी के लिए आवेदन कर सकते हैं, और फिर संगत प्रोग्रामिंग भाषाओं के साथ एपीआई का उपयोग करके मूनशॉट की क्षमताओं को अपने अनुप्रयोगों में एकीकृत कर सकते हैं।
- आधिकारिक उत्पादों और उपकरणों का उपयोग करनामूनशॉट मॉडल पर आधारित स्मार्ट सहायक उत्पाद किमिचाट का सीधे उपयोग करें, या डार्क साइड ऑफ द मून द्वारा प्रस्तुत संबंधित उपकरणों और प्लेटफार्मों का लाभ उठाएं।
- अन्य फ्रेमवर्क और उपकरणों के साथ एकीकरणअधिक मजबूत भाषा मॉडल अनुप्रयोगों के निर्माण के लिए मूनशॉट को लैंगचेन जैसे लोकप्रिय एआई विकास फ्रेमवर्क के साथ एकीकृत किया जा सकता है।
GLM-4-प्लस zhipu.ai द्वारा
सारांश परिचय
झिपु एआई द्वारा विकसित जीएलएम-4-प्लस, पूरी तरह से स्व-विकसित जीएलएम फाउंडेशन मॉडल का नवीनतम संस्करण है, जिसमें भाषा समझ, निर्देश-अनुसरण और लंबे-पाठ प्रसंस्करण में महत्वपूर्ण वृद्धि की गई है।
मुख्य विशेषताएं और लाभ
- मजबूत भाषा समझव्यापक डेटासेट और अनुकूलित एल्गोरिदम पर प्रशिक्षित, GLM-4-Plus जटिल अर्थ विज्ञान को संभालने में उत्कृष्टता प्राप्त करता है, तथा विभिन्न पाठों के अर्थ और संदर्भ की सटीक व्याख्या करता है।
- उत्कृष्ट दीर्घ-पाठ प्रसंस्करणएक अभिनव मेमोरी तंत्र और खंडित प्रसंस्करण तकनीक के साथ, जीएलएम-4-प्लस 128k टोकन तक के लंबे टेक्स्ट को प्रभावी ढंग से संभाल सकता है, जिससे यह डेटा प्रोसेसिंग और सूचना निष्कर्षण में अत्यधिक कुशल बन जाता है।
- उन्नत तर्क क्षमताएँइष्टतम समाधानों की खोज करते समय स्थिरता और दक्षता बनाए रखने के लिए प्रॉक्सिमल पॉलिसी ऑप्टिमाइजेशन (पीपीओ) को शामिल किया गया है, जिससे गणित और प्रोग्रामिंग जैसे जटिल तर्क कार्यों में मॉडल के प्रदर्शन में उल्लेखनीय सुधार हुआ है।
- उच्च अनुदेश-पालन सटीकता: उपयोगकर्ता के निर्देशों को सटीक रूप से समझता है और उनका पालन करता है, उपयोगकर्ता की आवश्यकताओं के आधार पर उच्च गुणवत्ता वाला, अपेक्षा-संरेखित पाठ तैयार करता है।
उपयोग निर्देश
- खाता पंजीकृत करें और API कुंजी प्राप्त करेंसबसे पहले, Zhipu की आधिकारिक वेबसाइट पर एक खाता पंजीकृत करें और एक API कुंजी प्राप्त करें।
- आधिकारिक दस्तावेज़ की समीक्षा करेंविस्तृत मापदंडों और उपयोग निर्देशों के लिए आधिकारिक GLM-4 श्रृंखला दस्तावेज़ देखें।
SenceChat 5.5 SenceTime द्वारा
सारांश परिचय
सेंसटाइम द्वारा विकसित सेंसचैट 5.5, इसके बड़े भाषा मॉडल का 5.5 संस्करण है, जो इंटर्नएलएम-123बी पर आधारित है, जो चीन के सबसे प्रारंभिक बड़े भाषा मॉडलों में से एक है, जो खरबों मापदंडों पर निर्मित है और निरंतर अद्यतन किया जाता है।

मुख्य विशेषताएं और लाभ
- शक्तिशाली व्यापक प्रदर्शन: यह लगातार विभिन्न मूल्यांकन कार्यों में शीर्ष स्तर पर स्थान प्राप्त करता है, मानविकी और विज्ञान में मौलिक दक्षताओं के साथ-साथ उन्नत "कठिन" कार्यों में उत्कृष्टता प्राप्त करता है। यह मानविकी में भाषा समझ और सुरक्षा में बेहतर प्रदर्शन प्रदर्शित करता है, और विज्ञान में तर्क और कोडिंग में उत्कृष्टता प्राप्त करता है।
- कुशल एज अनुप्रयोगसेंसटाइम ने सेंसचैट लाइट-5.5 संस्करण जारी किया है, जो प्रारंभिक लोड समय को घटाकर मात्र 0.19 सेकंड कर देता है, जो अप्रैल में जारी सेंसचैट लाइट-5.0 की तुलना में 40% सुधार है, जिसमें अनुमान गति 90.2 अक्षर प्रति सेकंड तक पहुंच जाती है और प्रति डिवाइस वार्षिक लागत 9.9 युआन जितनी कम होती है।
- असाधारण भाषा क्षमताएँ: एक प्राकृतिक भाषा अनुप्रयोग के रूप में, यह व्यापक पाठ डेटा को प्रभावी ढंग से संभालता है, मजबूत प्राकृतिक भाषा संवाद, तार्किक तर्क क्षमता, व्यापक ज्ञान और लगातार अपडेट प्रदर्शित करता है। यह सरलीकृत चीनी, पारंपरिक चीनी, अंग्रेजी और सामान्य प्रोग्रामिंग भाषाओं का समर्थन करता है।
उपयोग और अनुप्रयोग उत्पाद
- प्रत्यक्ष उपयोगउपयोगकर्ता वेब या मोबाइल ऐप के माध्यम से सेंसचैट तक पहुंचने और मॉडल के साथ बातचीत करने के लिए [सेंसटाइम वेबसाइट] पर पंजीकरण कर सकते हैं।
- एपीआई एकीकरणसेंसटाइम व्यवसायों और डेवलपर्स के लिए एपीआई पहुंच प्रदान करता है, जिससे वे सेंसचैट 5.5 को अपने उत्पादों या अनुप्रयोगों में एकीकृत कर सकते हैं।
Qwen2.5-72B-Qwen टीम द्वारा निर्देशित, अलीबाबा क्लाउड
मॉडल परिचय
Qwen2.5 Qwen बड़े भाषा मॉडल की नवीनतम श्रृंखला है। क्वेन2.5, टीम ने 0.5 से 72 बिलियन पैरामीटर्स तक के कई आधार भाषा मॉडल और निर्देश-संयोजित भाषा मॉडल जारी किए।
प्रमुख विशेषताऐं
- सघन, उपयोग में आसान, केवल डिकोडर भाषा मॉडल, उपलब्ध 0.5बी, 1.5बी, 3 बी, 7 बी, 14बी, 32बी, और 72बी आकार, और आधार और निर्देश वेरिएंट।
- हमारे नवीनतम बड़े पैमाने के डेटासेट पर पूर्व-प्रशिक्षित, जिसमें शामिल हैं 18टी टोकन.
- अनुदेश अनुसरण, लंबे पाठ (8K से अधिक टोकन) तैयार करने, संरचित डेटा (जैसे, तालिकाएं) को समझने, तथा संरचित आउटपुट, विशेष रूप से JSON तैयार करने में महत्वपूर्ण सुधार।
- सिस्टम प्रॉम्प्ट की विविधता के प्रति अधिक लचीला, चैटबॉट्स के लिए रोल-प्ले कार्यान्वयन और स्थिति-निर्धारण को बढ़ाना।
- संदर्भ लंबाई अधिकतम तक का समर्थन करती है 128के टोकन और तक उत्पन्न कर सकते हैं 8के टोकन.
- बहुभाषी समर्थन 29 चीनी, अंग्रेजी, फ्रेंच, स्पेनिश, पुर्तगाली, जर्मन, इतालवी, रूसी, जापानी, कोरियाई, वियतनामी, थाई, अरबी, आदि सहित कई भाषाएं।
जल्दी से कैसे शुरू करें?
आप Github और Hugging face पर बड़े मॉडल का उपयोग करने के लिए ट्यूटोरियल पा सकते हैं। इन ट्यूटोरियल के आधार पर, आप मॉडल को प्रभावी ढंग से चला सकते हैं और अपने कार्यों और विचारों को साकार कर सकते हैं।
डौबाओ टीम, बाइटडांस द्वारा डौबाओ-प्रो
सारांश परिचय
डौबाओ-प्रो बाइटडांस द्वारा स्वतंत्र रूप से विकसित एक बड़ी भाषा मॉडल है, जिसे आधिकारिक तौर पर 15 मई, 2024 को जारी किया गया है। बड़े मॉडलों के लिए फ्लैगेवल मूल्यांकन मंच में, डौबाओ-प्रो 75.96 के स्कोर के साथ बंद-स्रोत मॉडल में दूसरे स्थान पर रहा।
- संस्करणों: डौबाओ-प्रो में 4k, 32k, और 128k संदर्भ विंडो वाले संस्करण शामिल हैं, जिनमें से प्रत्येक अनुमान और फाइन-ट्यूनिंग के लिए अलग-अलग संदर्भ लंबाई का समर्थन करता है।
- प्रदर्शन सुधारबाइटडांस के आंतरिक परीक्षण के अनुसार, डौबाओ-प्रो-4k ने 11 उद्योग-मानक सार्वजनिक बेंचमार्क में कुल 76.8 स्कोर हासिल किया।
मुख्य विशेषताएं और लाभ
- मजबूत व्यापक क्षमताएं: डौबाओ-प्रो वस्तुनिष्ठ और व्यक्तिपरक मूल्यांकन में गणित, ज्ञान अनुप्रयोग और समस्या समाधान में उत्कृष्टता प्राप्त करता है।
- अनुप्रयोगों की विस्तृत श्रृंखलासबसे व्यापक रूप से इस्तेमाल किए जाने वाले और बहुमुखी घरेलू मॉडलों में से एक के रूप में, डौबाओ का एआई सहायक, "डौबाओ", ऐप्पल ऐप स्टोर और प्रमुख एंड्रॉइड ऐप बाजारों में एआईजीसी अनुप्रयोगों के बीच डाउनलोड में पहले स्थान पर है।
- उच्च लागत प्रभावशीलता: डौबाओ-प्रो-32k की अनुमानित इनपुट लागत प्रति हजार टोकन केवल 0.0008 युआन है। उदाहरण के लिए, चीनी संस्करण को संसाधित करना हैरी पॉटर (2.74 मिलियन अक्षर) की लागत केवल 1.5 युआन है।
- उत्कृष्ट भाषा समझ और निर्माणडोबाओ-प्रो विविध प्राकृतिक भाषा इनपुट को सटीक रूप से समझता है और उच्च गुणवत्ता वाले, सुसंगत और तार्किक प्रतिक्रियाएं उत्पन्न करता है, जो सरल प्रश्नोत्तर, जटिल पाठ निर्माण और विशिष्ट क्षेत्रों में स्पष्टीकरण में उपयोगकर्ता की जरूरतों को पूरा करता है।
- कुशल अनुमान गतिव्यापक डेटा प्रशिक्षण और अनुकूलन के साथ, डौबाओ-प्रो एक अनुमान गति लाभ प्रदान करता है, जिससे त्वरित प्रतिक्रिया समय और बेहतर उपयोगकर्ता अनुभव की अनुमति मिलती है, खासकर जब बड़ी मात्रा में पाठ या जटिल कार्यों को संभालना होता है।
उपयोग के तरीके
- ज्वालामुखी इंजन के माध्यम सेमॉडल के API को कॉल करके Doubao-pro का उपयोग करें, कोड नमूने ज्वालामुखी इंजन के आधिकारिक दस्तावेज़ में उपलब्ध हैं।
- विशिष्ट उत्पादों के लिए: डोबाओ-प्रो वोल्केनो इंजन के माध्यम से एंटरप्राइज़ मार्केट के लिए उपलब्ध है, जिससे व्यवसाय इसे अपने उत्पादों या सेवाओं में एकीकृत कर सकते हैं। आप डोबाओ ऐप के माध्यम से डोबाओ मॉडल का अनुभव भी कर सकते हैं।
360gpt2-प्रो 360 द्वारा
सारांश परिचय
- मॉडल नाम: 360GPT2-प्रो 360 द्वारा विकसित 360 Zhibrain बड़े मॉडल श्रृंखला का हिस्सा है।
- तकनीकी आधार20 वर्षों के सुरक्षा डेटा, 10 वर्षों के AI अनुभव और 80 AI और 100 सुरक्षा विशेषज्ञों की विशेषज्ञता का लाभ उठाते हुए, 360 ने ज़ीब्रेन मॉडल को प्रशिक्षित और अनुकूलित करने के लिए 200 दिनों में 5,000 GPU संसाधनों का उपयोग किया, जिसमें 360GPT2-Pro इसके उन्नत संस्करणों में से एक है।

मुख्य विशेषताएं और लाभ
- सशक्त भाषा पीढ़ी: कहानियों और कॉपीराइटिंग जैसे उच्च गुणवत्ता वाले, रचनात्मक और तार्किक रूप से सुसंगत सामग्री का निर्माण करके भाषा निर्माण कार्यों में उत्कृष्टता प्राप्त करना, विशेष रूप से मानविकी में।
- सुदृढ़ ज्ञान समझ और अनुप्रयोगव्यापक ज्ञान आधार से लैस, यह प्रश्नों के उत्तर देने और समस्याओं को प्रभावी ढंग से हल करने के लिए जानकारी की सटीक व्याख्या और अनुप्रयोग करता है।
- उन्नत पुनर्प्राप्ति-आधारित पीढ़ीपुनर्प्राप्ति-संवर्धित पीढ़ी में सक्षम, विशेष रूप से चीनी के लिए, मॉडल को उपयोगकर्ता की जरूरतों और वास्तविक दुनिया के आंकड़ों के साथ संरेखित प्रतिक्रियाएं उत्पन्न करने में सक्षम बनाता है, जिससे मतिभ्रम की संभावना कम हो जाती है।
- उन्नत सुरक्षा सुविधाएँसुरक्षा में 360 की दीर्घकालिक विशेषज्ञता से लाभान्वित होकर, 360GPT2-Pro सुरक्षा और विश्वसनीयता का एक स्तर प्रदान करता है, तथा विभिन्न सुरक्षा जोखिमों का प्रभावी ढंग से समाधान करता है।
उपयोग के तरीके और संबंधित उत्पाद
- 360AI खोज: उपयोगकर्ताओं को अधिक व्यापक और गहन खोज अनुभव प्रदान करने के लिए 360GPT2-Pro को खोज कार्यक्षमता के साथ एकीकृत करता है।
- 360AI ब्राउज़र: 360AI ब्राउज़र में 360GPT2-Pro को शामिल किया गया है, जिससे उपयोगकर्ताओं को जानकारी और सुझाव प्राप्त करने के लिए विशिष्ट इंटरफेस या वॉयस इनपुट के माध्यम से मॉडल के साथ बातचीत करने की अनुमति मिलती है।
स्टेप-2-16k by stepfun
सारांश परिचय
- डेवलपर: स्टेपस्टार ने आधिकारिक संस्करण जारी किया STEP-2 ट्रिलियन-पैरामीटर भाषा मॉडल 2024 में, चरण-2-16k अपने संस्करण को संदर्भित करता है जो 16k संदर्भ विंडो का समर्थन करता है।
- मॉडल वास्तुकला: एक अभिनव MoE (विशेषज्ञों का मिश्रण) वास्तुकला पर निर्मित, जो कार्यों और डेटा वितरण के आधार पर विभिन्न विशेषज्ञ मॉडलों को गतिशील रूप से सक्रिय करता है, जिससे प्रदर्शन और दक्षता दोनों में वृद्धि होती है।
- पैरामीटर स्केलएक ट्रिलियन मापदंडों के साथ, मॉडल व्यापक भाषा ज्ञान और अर्थ संबंधी जानकारी को कैप्चर करता है, और विभिन्न प्राकृतिक भाषा प्रसंस्करण कार्यों में शक्तिशाली क्षमताओं को प्रदर्शित करता है।

मुख्य विशेषताएं और लाभ
- शक्तिशाली भाषा समझ और निर्माणइनपुट टेक्स्ट की सटीक व्याख्या करता है और उच्च गुणवत्ता वाले, प्राकृतिक उत्तर उत्पन्न करता है, तथा प्रश्नों के उत्तर देने, विषय-वस्तु निर्माण और वार्तालाप के आदान-प्रदान जैसे कार्यों को सटीकता और मूल्य के साथ समर्थन प्रदान करता है।
- बहु-डोमेन ज्ञान कवरेजविशाल डेटासेट पर प्रशिक्षित यह मॉडल गणित, तर्क, प्रोग्रामिंग, ज्ञान और रचनात्मक लेखन जैसे क्षेत्रों में व्यापक ज्ञान को सम्मिलित करता है, जिससे यह क्रॉस-डोमेन प्रतिक्रियाओं और अनुप्रयोगों के लिए बहुमुखी बन जाता है।
- लंबी अनुक्रम प्रसंस्करण क्षमता: 16k संदर्भ विंडो के साथ, यह मॉडल लंबे पाठ अनुक्रमों को संभालने, लंबे लेखों और जटिल दस्तावेजों की समझ और प्रसंस्करण को सुविधाजनक बनाने में उत्कृष्ट है।
- प्रदर्शन GPT-4 के करीबबहुभाषा कार्यों में लगभग GPT-4 के समान प्रदर्शन प्राप्त करते हुए, यह मॉडल उच्च-स्तरीय व्यापक भाषा प्रसंस्करण क्षमताओं को प्रदर्शित करता है।
उपयोग और अनुप्रयोग
स्टेपस्टार उद्यमों और डेवलपर्स को एक खुला मंच प्रदान करता है, जहां वे आवेदन कर सकते हैं। चरण-2-16k मॉडल.
उपयोगकर्ता विभिन्न प्राकृतिक भाषा प्रसंस्करण कार्यात्मकताओं को लागू करने के लिए प्लेटफॉर्म-प्रदत्त प्रलेखन और विकास उपकरणों का उपयोग करके, API कॉल के माध्यम से मॉडल को अनुप्रयोगों या विकास परियोजनाओं में एकीकृत कर सकते हैं।
डीपसीक-V2.5 डीपसीक द्वारा
सारांश परिचय
डीपसीक-V2.5डीपसीक टीम द्वारा विकसित, एक शक्तिशाली ओपन-सोर्स भाषा मॉडल है जो डीपसीक-वी2-चैट और डीपसीक-कोडर-वी2-इंस्ट्रक्ट की क्षमताओं को एकीकृत करता है, जो पिछले मॉडल उन्नति की परिणति का प्रतिनिधित्व करता है। मुख्य विवरण इस प्रकार हैं:
- विकास इतिहाससितंबर 2024 में, उन्होंने आधिकारिक तौर पर डीपसीक-V2.5 जारी किया, जिसमें चैट और कोडिंग क्षमताओं को मिलाया गया। यह संस्करण सामान्य भाषा दक्षता और कोडिंग कार्यक्षमता दोनों को बढ़ाता है।
- ओपन सोर्स प्रकृतिओपन-सोर्स विकास के प्रति प्रतिबद्धता के अनुरूप, डीपसीक-V2.5 अब हगिंग फेस पर उपलब्ध है, जिससे डेवलपर्स को आवश्यकतानुसार मॉडल को समायोजित और अनुकूलित करने की अनुमति मिलती है।

मुख्य विशेषताएं और लाभ
- संयुक्त भाषा और कोडिंग क्षमताएंडीपसीक-V2.5 में चैट मॉडल की वार्तालाप क्षमताएं और कोडर मॉडल की कोडिंग क्षमताएं बरकरार हैं, जिससे यह एक वास्तविक "ऑल-इन-वन" समाधान बन जाता है जो रोजमर्रा की बातचीत, जटिल निर्देशों का पालन, कोड निर्माण और पूर्णता को संभालने में सक्षम है।
- मानव वरीयता संरेखणमानवीय प्राथमिकताओं के साथ तालमेल बिठाने के लिए मॉडल को लेखन गुणवत्ता और निर्देश अनुपालन के लिए अनुकूलित किया गया है, जिससे उपयोगकर्ता की आवश्यकताओं को बेहतर ढंग से समझने और पूरा करने के लिए कई कार्यों में अधिक स्वाभाविक और बुद्धिमानी से प्रदर्शन किया जा सके।
- बेहतरीन प्रदर्शन: डीपसीक-V2.5 विभिन्न बेंचमार्क पर पिछले संस्करणों को पीछे छोड़ता है, और ह्यूमनएवल पायथन और लाइव कोड बेंच जैसे कोडिंग बेंचमार्क में शीर्ष परिणाम प्राप्त करता है, जो निर्देश अनुपालन और कोड निर्माण में अपनी ताकत का प्रदर्शन करता है।
- विस्तारित संदर्भ समर्थन: 128k टोकन की अधिकतम संदर्भ लंबाई के साथ, डीपसीक-V2.5 प्रभावी रूप से लंबे-फॉर्म टेक्स्ट और मल्टी-टर्न संवादों को संभालता है।
- उच्च लागत प्रभावशीलता: जैसे शीर्ष स्तरीय बंद स्रोत मॉडल की तुलना में क्लाउड 3.5 सॉनेट और जीपीटी-4o, डीपसीक-V2.5 यह एक महत्वपूर्ण लागत लाभ प्रदान करता है।
उपयोग के तरीके
- वेब प्लेटफॉर्म के माध्यम से: सिलिकॉनक्लाउड के डीपसीक-V2.5 प्लेग्राउंड जैसे वेब प्लेटफार्मों के माध्यम से डीपसीक-V2.5 तक पहुंचें।
- एपीआई के माध्यम सेउपयोगकर्ता API कुंजी प्राप्त करने के लिए एक खाता बना सकते हैं, फिर द्वितीयक विकास और अनुप्रयोगों के लिए API के माध्यम से DeepSeek-V2.5 को अपने सिस्टम में एकीकृत कर सकते हैं।
- स्थानीय परिनियोजन: अनुमान के लिए हगिंग फेस के ट्रांसफॉर्मर का उपयोग करते हुए, 80GB प्रत्येक पर 8 GPU की आवश्यकता होती है। विशिष्ट चरणों के लिए दस्तावेज़ और नमूना कोड देखें।
- विशिष्ट उत्पादों के भीतर:
- कर्सर: VSCode पर आधारित यह AI कोड संपादक, उपयोगकर्ताओं को DeepSeek-V2.5 मॉडल को कॉन्फ़िगर करने की अनुमति देता है, जो शॉर्टकट के माध्यम से ऑन-पेज कोड जेनरेशन के लिए सिलिकॉनक्लाउड के API से जुड़ता है, जिससे कोडिंग दक्षता बढ़ती है।
- अन्य विकास उपकरण या प्लेटफ़ॉर्मकोई भी विकास उपकरण या प्लेटफ़ॉर्म जो बाह्य भाषा मॉडल API का समर्थन करता है, सैद्धांतिक रूप से API कुंजी प्राप्त करके DeepSeek-V2.5 को एकीकृत कर सकता है, जिससे भाषा निर्माण और कोड लेखन क्षमताएं सक्षम हो सकती हैं।
Ernie-4.0-turbo-8k-preview by Baidu
सारांश परिचय
एर्नी-4.0-टर्बो-8k-पूर्वावलोकन यह Baidu की ERNIE 4.0 टर्बो श्रृंखला का हिस्सा है, जिसे आधिकारिक तौर पर 28 जून, 2024 को जारी किया जाएगा, और 5 जुलाई, 2024 को एंटरप्राइज़ ग्राहकों के लिए पूरी तरह से खोल दिया जाएगा।
मुख्य विशेषताएं और लाभ
- प्रदर्शन सुधारERNIE 4.0 के उन्नत संस्करण के रूप में, यह मॉडल संदर्भ इनपुट लंबाई को 2k टोकन से 8k टोकन तक बढ़ाता है, जिससे यह बड़े डेटासेट को संभालने, अधिक दस्तावेज़ या URL पढ़ने और लंबे टेक्स्ट वाले कार्यों पर बेहतर प्रदर्शन करने में सक्षम हो जाता है।
- लागत में कमीERNIE 4.0-turbo-8k-preview की इनपुट और आउटपुट लागत 0.03 CNY प्रति 1,000 टोकन और 0.06 CNY प्रति 1,000 टोकन जितनी कम है, जो ERNIE 4.0 के सामान्य संस्करण की तुलना में 70% मूल्य में कमी है।
- तकनीकी अनुकूलनटर्बो प्रौद्योगिकी द्वारा उन्नत, यह मॉडल प्रशिक्षण गति और प्रदर्शन में दोहरा सुधार प्राप्त करता है, जिससे मॉडल प्रशिक्षण और तैनाती तेज हो जाती है।
- विस्तृत अनुप्रयोग: अपने प्रदर्शन और लागत लाभों के कारण, यह मॉडल बुद्धिमान ग्राहक सेवा, आभासी सहायक, शिक्षा और मनोरंजन जैसे क्षेत्रों में व्यापक रूप से लागू है, जो एक सहज और स्वाभाविक बातचीत का अनुभव प्रदान करता है। इसकी मजबूत पीढ़ी क्षमताएं इसे सामग्री निर्माण और डेटा विश्लेषण के लिए भी अत्यधिक उपयुक्त बनाती हैं।
प्रयोग
ERNIE 4.0-turbo-8k-preview मुख्य रूप से एंटरप्राइज़ ग्राहकों के लिए उपलब्ध है, जो इसे Baidu इंटेलिजेंट क्लाउड पर Baidu के Qianfan लार्ज मॉडल प्लेटफॉर्म के माध्यम से एक्सेस कर सकते हैं।
चीनी कंपनी द्वारा निर्मित शीर्ष 10 AI मॉडल
| नमूना | डेवलपर | मुख्य विशेषता और ताकत | का उपयोग कैसे करें |
| हुनयुआन-बड़ा | Tencent | खुला स्रोत, 398 बिलियन पैरामीटर | मॉडल डाउनलोड करें |
| मूनशॉट(किमी) | मूनशॉट एआई | लंबे-पाठ प्रसंस्करण क्षमता, उच्च भाषा समझ | एपीआई, आधिकारिक ऐप और उपकरण |
| जीएलएम-4-प्लस | zhipu.ai | भाषा समझ, निर्देश-अनुसरण, और लंबे-पाठ प्रसंस्करण। | एपीआई |
| सेंसचैट 5.5 | सेन्सटाइम | शक्तिशाली व्यापक प्रदर्शन, असाधारण भाषा क्षमताएं | सेंसटाइम वेबसाइट, एपीआई |
| क्वेन2.5-72बी | अलीबाबा क्लाउड | संदर्भ लंबाई 128K तक का समर्थन करती है, 29 से अधिक भाषाओं के लिए बहुभाषी समर्थन | मॉडल डाउनलोड करें, आधिकारिक वेबसाइट |
| डोबाओ-प्रो | बाइटडांस | मजबूत व्यापक क्षमताएं, उच्च लागत प्रभावशीलता, चैटबॉट, | दाओबाओ ऐप, एपीआई |
| 360gpt2-प्रो | 360 | उन्नत सुरक्षा सुविधाएँ, सशक्त भाषा निर्माण | लोबेचैट, 360AI ब्राउज़र |
| चरण-2-16k | स्टेपफ़न | ट्रिलियन-पैरामीटर भाषा मॉडल, मल्टी-डोमेन नॉलेज कवरेज, GPT-4 के करीब प्रदर्शन | एपीआई |
| डीपसीक-V2.5 | डीपसीक | संयुक्त भाषा और कोडिंग क्षमताएं, मानव वरीयता संरेखण | वेब प्लेटफ़ॉर्म, एपीआई, स्थानीय परिनियोजन |
| एर्नी-4.0-टर्बो-8k | Baidu | विस्तृत अनुप्रयोग, लागत में कमी, | केवल एंटरप्राइज़ क्लाइंट |


