

Apa itu model LLM?
Definisi dan gambaran umum
Model AI adalah program yang telah dilatih pada serangkaian data untuk mengenali pola tertentu atau membuat keputusan tertentu tanpa campur tangan manusia lebih lanjut.
Model bahasa besar, juga dikenal sebagai Gelar Magister Hukum (LLM), adalah model pembelajaran mendalam yang sangat besar yang telah dilatih sebelumnya pada sejumlah besar data.
Transformator yang mendasarinya adalah serangkaian jaringan saraf yang terdiri dari encoder dan decoder dengan kemampuan self-attention. Encoder dan decoder mengekstrak makna dari serangkaian teks dan memahami hubungan antara kata dan frasa di dalamnya.
Model mana yang terbaik bagi Anda?
Model-model besar AI berkembang sangat pesat. Berbagai perusahaan dan lembaga penelitian menyajikan pencapaian penelitian baru setiap hari, bersama dengan model-model bahasa besar baru.
Oleh karena itu, kami tidak dapat memberi tahu Anda secara pasti mana yang terbaik.
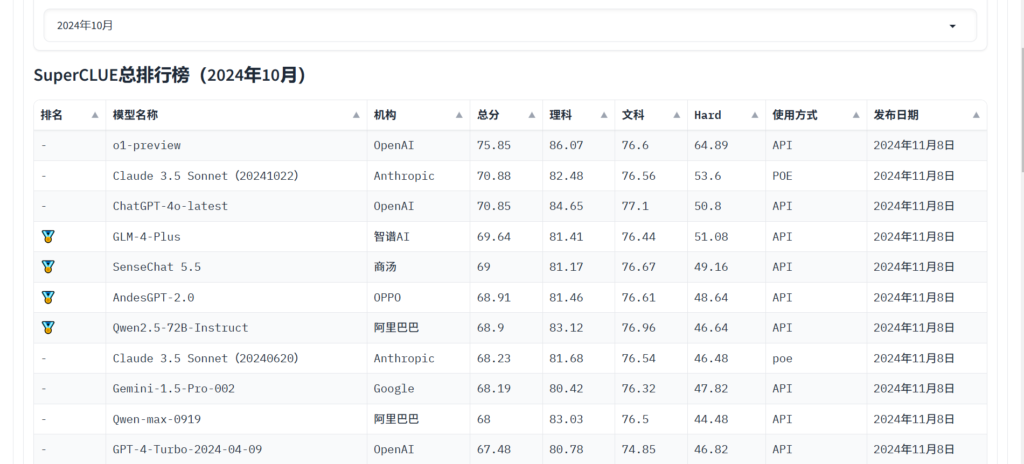
Namun, ada beberapa perusahaan dan model papan atas, seperti OpenAI. Sekarang ada seperangkat standar dan pertanyaan pengujian untuk mengevaluasi model.
Anda dapat merujuk ke petunjuk super untuk melihat skor model dalam berbagai tugas dan memilih yang sesuai dengan Anda. Anda juga dapat mengikuti berita terbaru untuk mengetahui lebih lanjut tentang kemampuan model LLM.
Hunyuan-Besar oleh Tencent
Pengenalan Model
Pada tanggal 5 November, Bahasa Indonesia: Tencent merilis Model Bahasa Besar MoE Open-Source Hunyuan-besar dengan total 398 miliar parameter, menjadikannya yang terbesar di industri, dengan 52 miliar parameter aktivasi.
Hasil evaluasi publik menunjukkan bahwa model Hunyuan Large milik Tencent memimpin secara komprehensif dalam berbagai proyek.

Keunggulan Teknis
- Data Sintetis Berkualitas Tinggi:Dengan meningkatkan pelatihan dengan data sintetis, Hunyuan-Besar dapat mempelajari representasi yang lebih kaya, menangani masukan konteks panjang, dan menggeneralisasi lebih baik ke data yang tidak terlihat.
- Kompresi Cache KV: Memanfaatkan strategi Grouped Query Attention (GQA) dan Cross-Layer Attention (CLA) untuk secara signifikan mengurangi penggunaan memori dan overhead komputasi cache KV, sehingga meningkatkan throughput inferensi.
- Skala Kecepatan Pembelajaran Khusus Pakar: Menetapkan kecepatan pembelajaran yang berbeda untuk pakar yang berbeda untuk memastikan setiap sub-model secara efektif belajar dari data dan berkontribusi terhadap kinerja keseluruhan.
- Kemampuan Pemrosesan Konteks Panjang:Model pra-terlatih mendukung rangkaian teks hingga 256K, dan model Instruct mendukung hingga 128K, secara signifikan meningkatkan kemampuan untuk menangani tugas konteks panjang.
- Pembandingan yang Luas: Melakukan eksperimen ekstensif dalam berbagai bahasa dan tugas untuk memvalidasi efektivitas praktis dan keamanan Hunyuan-Large.
Kerangka Inferensi dan Kerangka Pelatihan
Rilis sumber terbuka ini menawarkan dua opsi backend inferensi yang disesuaikan untuk Hunyuan-Model besar:yang populer vLLM-backend dan TensorRT-LLM Backend. Kedua solusi tersebut mencakup pengoptimalan untuk meningkatkan kinerja.
Model sumber terbuka Hunyuan-Large sepenuhnya kompatibel dengan format Hugging Face, yang memungkinkan peneliti dan pengembang melakukan penyempurnaan model menggunakan kerangka kerja hf-deepspeed. Selain itu, kami mendukung percepatan pelatihan melalui penggunaan flash attention.
Cara menggunakan model ini lebih lanjut
Ini adalah model sumber terbuka. Anda dapat menemukan “tencent-hunyuan” di Bahasa Indonesia: GitHub, yang menyediakan petunjuk terperinci dan panduan penggunaan. Anda dapat menjelajahi dan menelitinya lebih lanjut untuk menciptakan lebih banyak kemungkinan.
Pelayaran ke Bulan(Kimi) oleh Moonshot AI
Ringkasan Pendahuluan
Moonshot adalah model bahasa berskala besar yang dikembangkan oleh Dark Side of the Moon. Berikut ini adalah ikhtisar fitur-fiturnya:
- Terobosan Teknologi: Moonshot mencapai kemajuan luar biasa dalam pemrosesan teks panjang, dengan produk asisten pintarnya, Kimichat, yang mendukung hingga 2 juta karakter Mandarin dalam masukan konteks tanpa kehilangan.
- Arsitektur Model: Dengan menggunakan struktur jaringan yang inovatif dan pengoptimalan rekayasa, ia mencapai perhatian jangka panjang tanpa bergantung pada solusi "pintasan" seperti jendela geser, downsampling, atau model yang lebih kecil yang sering kali menurunkan kinerja. Hal ini memungkinkan pemahaman yang komprehensif terhadap teks yang sangat panjang bahkan dengan ratusan miliar parameter.
- Berorientasi pada Aplikasi: Dikembangkan dengan fokus pada aplikasi praktis, Moonshot bertujuan untuk menjadi alat harian yang sangat diperlukan bagi pengguna, berkembang berdasarkan umpan balik pengguna nyata untuk menghasilkan nilai nyata.

Fitur Utama
- Kemampuan Pemrosesan Teks Panjang: Mampu menangani teks yang luas seperti novel atau laporan keuangan lengkap, menawarkan kepada pengguna wawasan dan ringkasan dokumen yang panjang dan mendalam.
- Fusi Multimoda: Mengintegrasikan berbagai modalitas, menggabungkan teks dengan data gambar untuk meningkatkan kemampuan analisis dan pembuatan.
- Kemampuan Pemahaman dan Generasi Bahasa Tinggi: Menunjukkan kinerja multibahasa yang sangat baik, menafsirkan masukan pengguna secara akurat dan menghasilkan respons berkualitas tinggi, koheren, dan tepat secara semantik.
- Skalabilitas Fleksibel: Menawarkan skalabilitas yang kuat, memungkinkan penyesuaian dan pengoptimalan berdasarkan berbagai skenario dan kebutuhan aplikasi, memberikan pengembang dan perusahaan fleksibilitas dan otonomi yang signifikan.
Metode Penggunaan
- Integrasi API: Pengguna dapat mendaftar akun pada platform resmi Dark Side of the Moon, mengajukan kunci API, lalu mengintegrasikan kemampuan Moonshot ke dalam aplikasi mereka menggunakan API dengan bahasa pemrograman yang kompatibel.
- Menggunakan Produk dan Alat Resmi: Langsung gunakan Kimichat, produk asisten pintar berdasarkan model Moonshot, atau manfaatkan alat dan platform terkait yang ditawarkan oleh Dark Side of the Moon.
- Integrasi dengan Kerangka Kerja dan Alat Lain: Moonshot dapat diintegrasikan dengan kerangka kerja pengembangan AI populer seperti LangChain untuk membangun aplikasi model bahasa yang lebih tangguh.
GLM-4-Plus oleh zhipu.ai
Ringkasan Pendahuluan
GLM-4-Plus, yang dikembangkan oleh Zhipu AI, adalah iterasi terkini dari model dasar GLM yang dikembangkan sendiri sepenuhnya, dengan peningkatan signifikan dalam pemahaman bahasa, mengikuti instruksi, dan pemrosesan teks panjang.
Fitur dan Keunggulan Utama
- Pemahaman Bahasa yang Kuat: Dilatih pada kumpulan data yang luas dan algoritma yang dioptimalkan, GLM-4-Plus unggul dalam menangani semantik yang kompleks, secara akurat menafsirkan makna dan konteks berbagai teks.
- Pemrosesan Teks Panjang yang Luar Biasa: Dengan mekanisme memori yang inovatif dan teknik pemrosesan tersegmentasi, GLM-4-Plus dapat secara efektif menangani teks panjang hingga 128k token, membuatnya sangat mahir dalam pemrosesan data dan ekstraksi informasi.
- Kemampuan Berpikir yang Ditingkatkan: Menggabungkan Pengoptimalan Kebijakan Proksimal (PPO) untuk menjaga stabilitas dan efisiensi saat mengeksplorasi solusi optimal, secara signifikan meningkatkan kinerja model dalam tugas-tugas penalaran kompleks seperti matematika dan pemrograman.
- Akurasi Tinggi dalam Mengikuti Instruksi: Memahami dan mematuhi instruksi pengguna secara akurat, menghasilkan teks berkualitas tinggi dan sesuai harapan berdasarkan kebutuhan pengguna.
Petunjuk Penggunaan
- Daftarkan Akun dan Dapatkan Kunci APIPertama, daftarkan akun di situs web resmi Zhipu dan dapatkan kunci API.
- Tinjau Dokumentasi Resmi: Lihat dokumentasi resmi seri GLM-4 untuk parameter terperinci dan petunjuk penggunaan.
SenseChat 5.5 oleh SenceTime
Ringkasan Pendahuluan
SenseChat 5.5, yang dikembangkan oleh SenseTime, adalah versi 5.5 dari model bahasa besarnya, berdasarkan InternLM-123b, salah satu model bahasa besar paling awal di Tiongkok yang dibangun di atas triliunan parameter dan terus diperbarui.

Fitur dan Keunggulan Utama
- Kinerja Komprehensif yang Kuat: Secara konsisten berada di peringkat teratas dalam berbagai tugas evaluasi, unggul dalam kompetensi dasar dalam humaniora dan sains serta tugas "Sulit" tingkat lanjut. Menunjukkan kinerja yang unggul dalam pemahaman dan keamanan bahasa dalam humaniora, dan unggul dalam logika dan pengodean dalam sains.
- Aplikasi Edge yang Efisien: SenseTime telah merilis versi SenseChat Lite-5.5, yang mengurangi waktu muat awal menjadi hanya 0,19 detik, peningkatan 40% dibandingkan SenseChat Lite-5.0 yang dirilis pada bulan April, dengan kecepatan inferensi mencapai 90,2 karakter per detik dan biaya tahunan per perangkat serendah 9,9 yuan.
- Kemampuan Bahasa yang Luar Biasa: Sebagai aplikasi bahasa alami, aplikasi ini menangani data teks yang ekstensif secara efektif, menunjukkan dialog bahasa alami yang kuat, kemampuan penalaran logis, pengetahuan luas, dan pembaruan yang sering. Aplikasi ini mendukung bahasa Mandarin Sederhana, bahasa Mandarin Tradisional, bahasa Inggris, dan bahasa pemrograman umum lainnya.
Penggunaan dan Aplikasi Produk
- Penggunaan Langsung:Pengguna dapat mendaftar di [situs web SenseTime] untuk mengakses SenseChat melalui web atau aplikasi seluler dan berinteraksi dengan model.
- Integrasi API: SenseTime menawarkan akses API untuk bisnis dan pengembang, memungkinkan mereka mengintegrasikan SenseChat 5.5 ke dalam produk atau aplikasi mereka.
Qwen2.5-72B-Instruksi oleh tim Qwen, Alibaba Cloud
Pengenalan Model
Qwen2.5 adalah seri terbaru dari model bahasa besar Qwen. Untuk Qwen2.5, tim merilis sejumlah model bahasa dasar dan model bahasa yang disesuaikan dengan instruksi mulai dari 0,5 hingga 72 miliar parameter.
Fitur utama
- Model bahasa yang padat, mudah digunakan, hanya dekoder, tersedia dalam 0,5 miliar, 1,5 miliar, 3B, 7B, 14B, 32B, Dan 72B ukuran, serta varian dasar dan instruksi.
- Dilatih terlebih dahulu pada kumpulan data skala besar terbaru kami, yang mencakup hingga 18T token.
- Peningkatan signifikan dalam mengikuti instruksi, menghasilkan teks panjang (lebih dari 8K token), memahami data terstruktur (misalnya, tabel), dan menghasilkan keluaran terstruktur, khususnya JSON.
- Lebih tangguh terhadap keragaman perintah sistem, meningkatkan penerapan permainan peran dan pengaturan kondisi untuk chatbot.
- Panjang konteks mendukung hingga 128 ribu token dan dapat menghasilkan hingga 8 ribu token.
- Dukungan multibahasa untuk lebih dari 29 bahasa, termasuk Cina, Inggris, Prancis, Spanyol, Portugis, Jerman, Italia, Rusia, Jepang, Korea, Vietnam, Thailand, Arab, dan banyak lagi.
Bagaimana cara memulai dengan cepat?
Anda dapat menemukan tutorial untuk menggunakan model besar di Github dan Hugging face. Berdasarkan tutorial ini, Anda dapat menjalankan model secara efektif dan mewujudkan fungsi serta ide Anda.
Doubao-pro oleh Tim Doubao, ByteDance
Ringkasan Pendahuluan
Doubao-pro adalah model bahasa besar yang dikembangkan secara independen oleh ByteDance dan resmi dirilis pada 15 Mei 2024. Dalam platform evaluasi Flageval untuk model besar, Doubao-pro menempati peringkat kedua di antara model sumber tertutup dengan skor 75,96.
- Versi: Doubao-pro menyertakan versi dengan jendela konteks 4k, 32k, dan 128k, masing-masing mendukung panjang konteks yang berbeda untuk inferensi dan penyempurnaan.
- Peningkatan Kinerja:Menurut pengujian internal ByteDance, Doubao-pro-4k mencapai skor total 76,8 di 11 tolok ukur publik standar industri.
Fitur dan Keunggulan Utama
- Kemampuan Komprehensif yang Kuat: Doubao-pro unggul dalam matematika, penerapan pengetahuan, dan pemecahan masalah dalam evaluasi objektif dan subjektif.
- Berbagai Macam Aplikasi:Sebagai salah satu model domestik yang paling banyak digunakan dan serbaguna, asisten AI Doubao, “Doubao,” menempati peringkat pertama dalam unduhan di antara aplikasi AIGC di Apple App Store dan pasar aplikasi Android utama.
- Efektivitas Biaya Tinggi: Biaya input inferensi Doubao-pro-32k hanya 0,0008 yuan per seribu token. Misalnya, memproses versi bahasa Mandarin Harry Potter (2,74 juta karakter) biayanya hanya 1,5 yuan.
- Pemahaman dan Generasi Bahasa yang Luar Biasa: Doubao-pro secara akurat memahami beragam masukan bahasa alami dan menghasilkan respons berkualitas tinggi, koheren, dan logis, memenuhi kebutuhan pengguna dalam Tanya Jawab sederhana, pembuatan teks kompleks, dan penjelasan di bidang khusus.
- Kecepatan Inferensi yang Efisien: Dengan pelatihan dan pengoptimalan data yang ekstensif, Doubao-pro menawarkan keunggulan kecepatan inferensi, yang memungkinkan waktu respons yang cepat dan pengalaman pengguna yang lebih baik, terutama saat menangani teks dalam jumlah besar atau tugas yang rumit.
Metode Penggunaan
- Melalui Mesin Gunung Berapi: Gunakan Doubao-pro dengan memanggil API model, dengan contoh kode tersedia dalam dokumentasi resmi Volcano Engine.
- Untuk Produk Tertentu: Doubao-pro tersedia untuk pasar perusahaan melalui Volcano Engine, yang memungkinkan bisnis untuk mengintegrasikannya ke dalam produk atau layanan mereka. Anda juga dapat mencoba model Doubao melalui aplikasi Doubao.
360gpt2-pro oleh 360
Ringkasan Pendahuluan
- Nama Model: 360GPT2-Pro adalah bagian dari seri model besar 360 Zhibrain yang dikembangkan oleh 360.
- Fondasi Teknis: Dengan memanfaatkan 20 tahun data keamanan, 10 tahun pengalaman AI, dan keahlian 80 pakar AI dan 100 pakar keamanan, 360 menggunakan 5.000 sumber daya GPU selama 200 hari untuk melatih dan mengoptimalkan model Zhibrain, dengan 360GPT2-Pro menjadi salah satu versi lanjutannya.

Fitur dan Keunggulan Utama
- Generasi Bahasa yang Kuat: Unggul dalam tugas-tugas pembuatan bahasa, terutama dalam bidang humaniora, dengan menciptakan konten berkualitas tinggi, kreatif, dan koheren secara logis, seperti cerita dan copywriting.
- Pemahaman dan Aplikasi Pengetahuan yang Kuat: Dilengkapi dengan basis pengetahuan yang luas, ia secara akurat menafsirkan dan menerapkan informasi untuk menjawab pertanyaan dan memecahkan masalah secara efektif.
- Peningkatan Generasi Berbasis Pengambilan Kembali: Kompeten dalam pembangkitan peningkatan perolehan kembali, khususnya untuk bahasa Mandarin, yang memungkinkan model menghasilkan respons yang selaras dengan kebutuhan pengguna dan data dunia nyata, sehingga mengurangi kemungkinan halusinasi.
- Fitur Keamanan yang Ditingkatkan: Dengan memanfaatkan keahlian 360 yang sudah lama di bidang keamanan, 360GPT2-Pro memberikan tingkat keamanan dan keandalan, serta mengatasi berbagai risiko keamanan secara efektif.
Metode Penggunaan dan Produk Terkait
- Pencarian 360AI: Mengintegrasikan 360GPT2-Pro dengan fungsi pencarian untuk memberikan pengguna pengalaman pencarian yang lebih komprehensif dan mendalam.
- Peramban 360AI: Menggabungkan 360GPT2-Pro ke dalam 360AI Browser, yang memungkinkan pengguna berinteraksi dengan model melalui antarmuka tertentu atau melalui masukan suara untuk memperoleh informasi dan saran.
Langkah-2-16k oleh stepfun
Ringkasan Pendahuluan
- Pengembang: StepStar merilis versi resmi Model bahasa triliun parameter STEP-2 pada tahun 2024, dengan langkah-2-16k merujuk pada variannya yang mendukung jendela konteks 16k.
- Arsitektur Model: Dibangun di atas arsitektur MoE (Mixture of Experts) yang inovatif, yang secara dinamis mengaktifkan berbagai model pakar berdasarkan tugas dan distribusi data, sehingga meningkatkan kinerja dan efisiensi.
- Skala Parameter: Dengan satu triliun parameter, model tersebut menangkap pengetahuan bahasa dan informasi semantik yang luas, menampilkan kemampuan hebat di berbagai tugas pemrosesan bahasa alami.

Fitur dan Keunggulan Utama
- Pemahaman dan Generasi Bahasa yang Kuat: Menafsirkan teks masukan secara akurat dan menghasilkan respons alami berkualitas tinggi, mendukung tugas-tugas seperti menjawab pertanyaan, pembuatan konten, dan pertukaran percakapan dengan akurat dan bernilai.
- Cakupan Pengetahuan Multi-domain: Dilatih pada kumpulan data besar, model ini mencakup pengetahuan luas dalam berbagai bidang seperti matematika, logika, pemrograman, pengetahuan, dan penulisan kreatif, sehingga menjadikannya serbaguna untuk respons dan aplikasi lintas domain.
- Kemampuan Pemrosesan Urutan Panjang: Dengan jendela konteks 16k, model ini unggul dalam menangani rangkaian teks yang panjang, memfasilitasi pemahaman dan pemrosesan artikel yang panjang dan dokumen yang kompleks.
- Performa Mendekati GPT-4:Mencapai kinerja mendekati GPT-4 dalam berbagai tugas bahasa, model ini menampilkan kemampuan pemrosesan bahasa komprehensif tingkat tinggi.
Penggunaan dan Aplikasi
StepStar menyediakan platform terbuka bagi perusahaan dan pengembang untuk mengajukan akses ke model langkah-2-16k.
Pengguna dapat mengintegrasikan model ke dalam aplikasi atau proyek pengembangan melalui panggilan API, menggunakan dokumentasi yang disediakan platform dan alat pengembangan untuk mengimplementasikan berbagai fungsi pemrosesan bahasa alami.
DeepSeek-V2.5 oleh deepseek
Ringkasan Pendahuluan
Pencarian Dalam-V2.5, yang dikembangkan oleh tim DeepSeek, adalah model bahasa sumber terbuka yang kuat yang memadukan kemampuan DeepSeek-V2-Chat dan DeepSeek-Coder-V2-Instruct, yang merupakan puncak dari kemajuan model sebelumnya. Berikut ini adalah rincian utamanya:
- Sejarah Perkembangan: Pada bulan September 2024, mereka resmi merilis DeepSeek-V2.5, yang menggabungkan kemampuan mengobrol dan membuat kode. Versi ini meningkatkan kemampuan bahasa umum dan fungsionalitas membuat kode.
- Alam Sumber Terbuka: Sejalan dengan komitmen terhadap pengembangan sumber terbuka, DeepSeek-V2.5 sekarang tersedia di Hugging Face, yang memungkinkan pengembang untuk menyesuaikan dan mengoptimalkan model sesuai kebutuhan.

Fitur dan Keunggulan Utama
- Kemampuan Bahasa dan Pengkodean Gabungan: DeepSeek-V2.5 mempertahankan kemampuan percakapan model obrolan dan kekuatan pengkodean model pembuat kode, menjadikannya solusi "semua dalam satu" yang sesungguhnya yang mampu menangani percakapan sehari-hari, mengikuti instruksi yang rumit, pembuatan kode, dan penyelesaian.
- Penyelarasan Preferensi Manusia:Disesuaikan agar selaras dengan preferensi manusia, model ini telah dioptimalkan untuk kualitas penulisan dan kepatuhan terhadap instruksi, bekerja lebih alami dan cerdas dalam menangani berbagai tugas guna lebih memahami dan memenuhi kebutuhan pengguna.
- Kinerja Luar Biasa: Pencarian Dalam-V2.5 melampaui versi sebelumnya pada berbagai tolok ukur, dan meraih hasil teratas dalam tolok ukur pengkodean seperti humaneval python dan live code bench, memamerkan kekuatannya dalam kepatuhan instruksi dan pembuatan kode.
- Dukungan Konteks yang Diperluas: Dengan panjang konteks maksimum 128k token, DeepSeek-V2.5 secara efektif menangani teks bentuk panjang dan dialog multi-giliran.
- Efektivitas Biaya Tinggi:Dibandingkan dengan model sumber tertutup tingkat atas seperti Claude 3.5 Soneta dan GPT-4o, DeepSeek-V2.5 menawarkan keuntungan biaya yang signifikan.
Metode Penggunaan
- Melalui Platform Web:Akses DeepSeek-V2.5 melalui platform web seperti taman bermain DeepSeek-V2.5 SiliconCloud.
- Melalui API: Pengguna dapat membuat akun untuk mendapatkan kunci API, lalu mengintegrasikan DeepSeek-V2.5 ke dalam sistem mereka melalui API untuk pengembangan dan aplikasi sekunder.
- Penerapan Lokal: Memerlukan 8 GPU masing-masing 80 GB, menggunakan Transformer Hugging Face untuk inferensi. Lihat dokumentasi dan contoh kode untuk langkah-langkah spesifik.
- Dalam Produk Tertentu:
- Kursor: Editor kode AI ini, berdasarkan VSCode, memungkinkan pengguna mengonfigurasi model DeepSeek-V2.5, menghubungkan ke API SiliconCloud untuk pembuatan kode pada halaman melalui pintasan, sehingga meningkatkan efisiensi pengkodean.
- Alat atau Platform Pengembangan Lainnya:Alat pengembangan atau platform apa pun yang mendukung API model bahasa eksternal secara teoritis dapat mengintegrasikan DeepSeek-V2.5 dengan memperoleh kunci API, yang memungkinkan kemampuan pembuatan bahasa dan penulisan kode.
Ernie-4.0-turbo-8k-pratinjau oleh Baidu
Ringkasan Pendahuluan
Ernie-4.0-turbo-8k-pratinjau merupakan bagian dari seri ERNIE 4.0 Turbo Baidu yang resmi dirilis pada tanggal 28 Juni 2024 dan dibuka sepenuhnya untuk klien perusahaan pada tanggal 5 Juli 2024.
Fitur dan Keunggulan Utama
- Peningkatan Kinerja: Sebagai versi terbaru ERNIE 4.0, model ini memperluas panjang input konteks dari 2k token menjadi 8k token, sehingga mampu menangani kumpulan data yang lebih besar, membaca lebih banyak dokumen atau URL, dan bekerja lebih baik pada tugas yang melibatkan teks panjang.
- Pengurangan BiayaBiaya input dan output ERNIE 4.0-turbo-8k-preview serendah 0,03 CNY per 1.000 token dan 0,06 CNY per 1.000 token, pengurangan harga 70% dari versi umum ERNIE 4.0.
- Optimasi Teknis: Ditingkatkan dengan teknologi turbo, model ini mencapai peningkatan ganda dalam kecepatan dan kinerja pelatihan, yang memungkinkan pelatihan dan penerapan model yang lebih cepat.
- Aplikasi Luas: Berkat keunggulan kinerja dan biayanya, model ini dapat diaplikasikan secara luas di berbagai bidang seperti layanan pelanggan cerdas, asisten virtual, pendidikan, dan hiburan, serta memberikan pengalaman percakapan yang lancar dan alami. Kemampuan pembangkitannya yang tangguh juga membuatnya sangat cocok untuk pembuatan konten dan analisis data.
Penggunaan
Pratinjau ERNIE 4.0-turbo-8k terutama tersedia untuk klien perusahaan, yang dapat mengaksesnya melalui Platform Model Besar Qianfan Baidu di Baidu Intelligent Cloud.
10 Model AI Teratas yang Dibuat oleh Perusahaan Tiongkok
| Model | Pengembang | Fitur utama &Kekuatan | Cara penggunaan |
| Hunyuan-Besar | Bahasa Indonesia: Tencent | Sumber terbuka, 398 miliar parameter | Unduh modelnya |
| Moonshot (kimi) | AI Penembakan Bulan | Kemampuan Pemrosesan Teks Panjang, Pemahaman Bahasa Tinggi | API, Aplikasi dan alat resmi |
| GLM-4-Plus | zhipu.ai | pemahaman bahasa, mengikuti instruksi, dan pemrosesan teks panjang. | API |
| Obrolan Rasa 5.5 | Waktu Kalimat | Performa Komprehensif yang Kuat, Kemampuan Bahasa yang Luar Biasa | Situs web Sensetime, API |
| Qwen2.5-72B | Awan Alibaba | Panjang konteks mendukung hingga 128K, Dukungan multibahasa untuk lebih dari 29 bahasa | Unduh model, situs web resmi |
| Doubao-pro | Tari Byte | Kemampuan Komprehensif yang Kuat, efektivitas biaya tinggi, chatbot, | Aplikasi Daobao, API |
| 360gpt2-pro | 360 | Fitur Keamanan yang Ditingkatkan, Pembuatan Bahasa yang Kuat | Lobechat, peramban 360AI |
| Langkah-2-16k | langkah menyenangkan | model bahasa parameter triliun, Cakupan Pengetahuan Multidomain, Kinerja Mendekati GPT-4 | API |
| Pencarian Dalam-V2.5 | pencarian mendalam | Gabungan Kemampuan Bahasa dan Pengkodean, Penyelarasan Preferensi Manusia | Platform web, API, penerapan lokal |
| Ernie-4.0-turbo-8k | Bahasa Indonesia: Baidu | Aplikasi Luas, pengurangan biaya, | Hanya klien perusahaan |


